 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances of End-to-End Video Coding Technologies for AVS Standard Development
Jan 31, 2026Video coding standards are essential to enable the interoperability and widespread adoption of efficient video compression technologies. In pursuit of greater video compression efficiency, the AVS video coding working group launched the standardization exploration of end-to-end intelligent video coding, establishing the AVS End-to-End Intelligent Video Coding Exploration Model (AVS-EEM) project. A core design principle of AVS-EEM is its focus on practical deployment, featuring inherently low computational complexity and requiring strict adherence to the common test conditions of conventional video coding. This paper details the development history of AVS-EEM and provides a systematic introduction to its key technical framework, covering model architectures, training strategies, and inference optimizations. These innovations have collectively driven the project's rapid performance evolution, enabling continuous and significant gains under strict complexity constraints. Through over two years of iterative refinement and collaborative effort, the coding performance of AVS-EEM has seen substantial improvement. Experimental results demonstrate that its latest model achieves superior compression efficiency compared to the conventional AVS3 reference software, marking a significant step toward a deployable intelligent video coding standard.
LMVC: An End-to-End Learned Multiview Video Coding Framework
Sep 04, 2025Multiview video is a key data source for volumetric video, enabling immersive 3D scene reconstruction but posing significant challenges in storage and transmission due to its massive data volume. Recently, deep learning-based end-to-end video coding has achieved great success, yet most focus on single-view or stereo videos, leaving general multiview scenarios underexplored. This paper proposes an end-to-end learned multiview video coding (LMVC) framework that ensures random access and backward compatibility while enhancing compression efficiency. Our key innovation lies in effectively leveraging independent-view motion and content information to enhance dependent-view compression. Specifically, to exploit the inter-view motion correlation, we propose a feature-based inter-view motion vector prediction method that conditions dependent-view motion encoding on decoded independent-view motion features, along with an inter-view motion entropy model that learns inter-view motion priors. To exploit the inter-view content correlation, we propose a disparity-free inter-view context prediction module that predicts inter-view contexts from decoded independent-view content features, combined with an inter-view contextual entropy model that captures inter-view context priors. Experimental results show that our proposed LMVC framework outperforms the reference software of the traditional MV-HEVC standard by a large margin, establishing a strong baseline for future research in this field.
Fine-Grained Motion Compression and Selective Temporal Fusion for Neural B-Frame Video Coding
Jun 09, 2025With the remarkable progress in neural P-frame video coding, neural B-frame coding has recently emerged as a critical research direction. However, most existing neural B-frame codecs directly adopt P-frame coding tools without adequately addressing the unique challenges of B-frame compression, leading to suboptimal performance. To bridge this gap, we propose novel enhancements for motion compression and temporal fusion for neural B-frame coding. First, we design a fine-grained motion compression method. This method incorporates an interactive dual-branch motion auto-encoder with per-branch adaptive quantization steps, which enables fine-grained compression of bi-directional motion vectors while accommodating their asymmetric bitrate allocation and reconstruction quality requirements. Furthermore, this method involves an interactive motion entropy model that exploits correlations between bi-directional motion latent representations by interactively leveraging partitioned latent segments as directional priors. Second, we propose a selective temporal fusion method that predicts bi-directional fusion weights to achieve discriminative utilization of bi-directional multi-scale temporal contexts with varying qualities. Additionally, this method introduces a hyperprior-based implicit alignment mechanism for contextual entropy modeling. By treating the hyperprior as a surrogate for the contextual latent representation, this mechanism implicitly mitigates the misalignment in the fused bi-directional temporal priors. Extensive experiments demonstrate that our proposed codec outperforms state-of-the-art neural B-frame codecs and achieves comparable or even superior compression performance to the H.266/VVC reference software under random-access configurations.
An Information-Theoretic Regularizer for Lossy Neural Image Compression
Nov 23, 2024



Lossy image compression networks aim to minimize the latent entropy of images while adhering to specific distortion constraints. However, optimizing the neural network can be challenging due to its nature of learning quantized latent representations. In this paper, our key finding is that minimizing the latent entropy is, to some extent, equivalent to maximizing the conditional source entropy, an insight that is deeply rooted in information-theoretic equalities. Building on this insight, we propose a novel structural regularization method for the neural image compression task by incorporating the negative conditional source entropy into the training objective, such that both the optimization efficacy and the model's generalization ability can be promoted. The proposed information-theoretic regularizer is interpretable, plug-and-play, and imposes no inference overheads. Extensive experiments demonstrate its superiority in regularizing the models and further squeezing bits from the latent representation across various compression structures and unseen domains.
USTC-TD: A Test Dataset and Benchmark for Image and Video Coding in 2020s
Sep 13, 2024



Image/video coding has been a remarkable research area for both academia and industry for many years. Testing datasets, especially high-quality image/video datasets are desirable for the justified evaluation of coding-related research, practical applications, and standardization activities. We put forward a test dataset namely USTC-TD, which has been successfully adopted in the practical end-to-end image/video coding challenge of the IEEE International Conference on Visual Communications and Image Processing in 2022 and 2023. USTC-TD contains 40 images at 4K spatial resolution and 10 video sequences at 1080p spatial resolution, featuring various content due to the diverse environmental factors (scene type, texture, motion, view) and the designed imaging factors (illumination, shadow, lens). We quantitatively evaluate USTC-TD on different image/video features (spatial, temporal, color, lightness), and compare it with the previous image/video test datasets, which verifies the wider coverage and more diversity of the proposed dataset. We also evaluate both classic standardized and recent learned image/video coding schemes on USTC-TD with PSNR and MS-SSIM, and provide an extensive benchmark for the evaluated schemes. Based on the characteristics and specific design of the proposed test dataset, we analyze the benchmark performance and shed light on the future research and development of image/video coding. All the data are released online: https://esakak.github.io/USTC-TD.
Bi-Directional Deep Contextual Video Compression
Aug 16, 2024



Deep video compression has made remarkable process in recent years, with the majority of advancements concentrated on P-frame coding. Although efforts to enhance B-frame coding are ongoing, their compression performance is still far behind that of traditional bi-directional video codecs. In this paper, we introduce a bi-directional deep contextual video compression scheme tailored for B-frames, termed DCVC-B, to improve the compression performance of deep B-frame coding. Our scheme mainly has three key innovations. First, we develop a bi-directional motion difference context propagation method for effective motion difference coding, which significantly reduces the bit cost of bi-directional motions. Second, we propose a bi-directional contextual compression model and a corresponding bi-directional temporal entropy model, to make better use of the multi-scale temporal contexts. Third, we propose a hierarchical quality structure-based training strategy, leading to an effective bit allocation across large groups of pictures (GOP). Experimental results show that our DCVC-B achieves an average reduction of 26.6% in BD-Rate compared to the reference software for H.265/HEVC under random access conditions. Remarkably, it surpasses the performance of the H.266/VVC reference software on certain test datasets under the same configuration.
NVC-1B: A Large Neural Video Coding Model
Jul 28, 2024



The emerging large models have achieved notable progress in the fields of natural language processing and computer vision. However, large models for neural video coding are still unexplored. In this paper, we try to explore how to build a large neural video coding model. Based on a small baseline model, we gradually scale up the model sizes of its different coding parts, including the motion encoder-decoder, motion entropy model, contextual encoder-decoder, contextual entropy model, and temporal context mining module, and analyze the influence of model sizes on video compression performance. Then, we explore to use different architectures, including CNN, mixed CNN-Transformer, and Transformer architectures, to implement the neural video coding model and analyze the influence of model architectures on video compression performance. Based on our exploration results, we design the first neural video coding model with more than 1 billion parameters -- NVC-1B. Experimental results show that our proposed large model achieves a significant video compression performance improvement over the small baseline model, and represents the state-of-the-art compression efficiency. We anticipate large models may bring up the video coding technologies to the next level.
Prediction and Reference Quality Adaptation for Learned Video Compression
Jun 20, 2024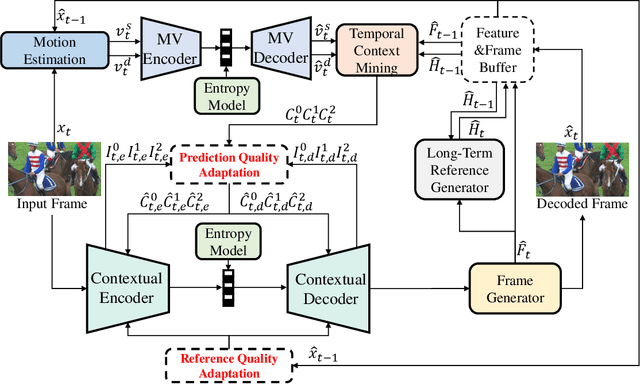



Temporal prediction is one of the most important technologies for video compression. Various prediction coding modes are designed in traditional video codecs. Traditional video codecs will adaptively to decide the optimal coding mode according to the prediction quality and reference quality. Recently, learned video codecs have made great progress. However, they ignore the prediction and reference quality adaptation, which leads to incorrect utilization of temporal prediction and reconstruction error propagation. Therefore, in this paper, we first propose a confidence-based prediction quality adaptation (PQA) module to provide explicit discrimination for the spatial and channel-wise prediction quality difference. With this module, the prediction with low quality will be suppressed and that with high quality will be enhanced. The codec can adaptively decide which spatial or channel location of predictions to use. Then, we further propose a reference quality adaptation (RQA) module and an associated repeat-long training strategy to provide dynamic spatially variant filters for diverse reference qualities. With the filters, it is easier for our codec to achieve the target reconstruction quality according to reference qualities, thus reducing the propagation of reconstruction errors. Experimental results show that our codec obtains higher compression performance than the reference software of H.266/VVC and the previous state-of-the-art learned video codecs in both RGB and YUV420 colorspaces.
Spatial Decomposition and Temporal Fusion based Inter Prediction for Learned Video Compression
Jan 29, 2024Video compression performance is closely related to the accuracy of inter prediction. It tends to be difficult to obtain accurate inter prediction for the local video regions with inconsistent motion and occlusion. Traditional video coding standards propose various technologies to handle motion inconsistency and occlusion, such as recursive partitions, geometric partitions, and long-term references. However, existing learned video compression schemes focus on obtaining an overall minimized prediction error averaged over all regions while ignoring the motion inconsistency and occlusion in local regions. In this paper, we propose a spatial decomposition and temporal fusion based inter prediction for learned video compression. To handle motion inconsistency, we propose to decompose the video into structure and detail (SDD) components first. Then we perform SDD-based motion estimation and SDD-based temporal context mining for the structure and detail components to generate short-term temporal contexts. To handle occlusion, we propose to propagate long-term temporal contexts by recurrently accumulating the temporal information of each historical reference feature and fuse them with short-term temporal contexts. With the SDD-based motion model and long short-term temporal contexts fusion, our proposed learned video codec can obtain more accurate inter prediction. Comprehensive experimental results demonstrate that our codec outperforms the reference software of H.266/VVC on all common test datasets for both PSNR and MS-SSIM.
Offline and Online Optical Flow Enhancement for Deep Video Compression
Jul 11, 2023



Video compression relies heavily on exploiting the temporal redundancy between video frames, which is usually achieved by estimating and using the motion information. The motion information is represented as optical flows in most of the existing deep video compression networks. Indeed, these networks often adopt pre-trained optical flow estimation networks for motion estimation. The optical flows, however, may be less suitable for video compression due to the following two factors. First, the optical flow estimation networks were trained to perform inter-frame prediction as accurately as possible, but the optical flows themselves may cost too many bits to encode. Second, the optical flow estimation networks were trained on synthetic data, and may not generalize well enough to real-world videos. We address the twofold limitations by enhancing the optical flows in two stages: offline and online. In the offline stage, we fine-tune a trained optical flow estimation network with the motion information provided by a traditional (non-deep) video compression scheme, e.g. H.266/VVC, as we believe the motion information of H.266/VVC achieves a better rate-distortion trade-off. In the online stage, we further optimize the latent features of the optical flows with a gradient descent-based algorithm for the video to be compressed, so as to enhance the adaptivity of the optical flows. We conduct experiments on a state-of-the-art deep video compression scheme, DCVC. Experimental results demonstrate that the proposed offline and online enhancement together achieves on average 12.8% bitrate saving on the tested videos, without increasing the model or computational complexity of the decoder side.