 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Noise to Latent: Generating Gaussian Latents for INR-Based Image Compression
Nov 11, 2025Recent implicit neural representation (INR)-based image compression methods have shown competitive performance by overfitting image-specific latent codes. However, they remain inferior to end-to-end (E2E) compression approaches due to the absence of expressive latent representations. On the other hand, E2E methods rely on transmitting latent codes and requiring complex entropy models, leading to increased decoding complexity. Inspired by the normalization strategy in E2E codecs where latents are transformed into Gaussian noise to demonstrate the removal of spatial redundancy, we explore the inverse direction: generating latents directly from Gaussian noise. In this paper, we propose a novel image compression paradigm that reconstructs image-specific latents from a multi-scale Gaussian noise tensor, deterministically generated using a shared random seed. A Gaussian Parameter Prediction (GPP) module estimates the distribution parameters, enabling one-shot latent generation via reparameterization trick. The predicted latent is then passed through a synthesis network to reconstruct the image. Our method eliminates the need to transmit latent codes while preserving latent-based benefits, achieving competitive rate-distortion performance on Kodak and CLIC dataset. To the best of our knowledge, this is the first work to explore Gaussian latent generation for learned image compression.
BiECVC: Gated Diversification of Bidirectional Contexts for Learned Video Compression
May 15, 2025Recent forward prediction-based learned video compression (LVC) methods have achieved impressive results, even surpassing VVC reference software VTM under the Low Delay B (LDB) configuration. In contrast, learned bidirectional video compression (BVC) remains underexplored and still lags behind its forward-only counterparts. This performance gap is mainly due to the limited ability to extract diverse and accurate contexts: most existing BVCs primarily exploit temporal motion while neglecting non-local correlations across frames. Moreover, they lack the adaptability to dynamically suppress harmful contexts arising from fast motion or occlusion. To tackle these challenges, we propose BiECVC, a BVC framework that incorporates diversified local and non-local context modeling along with adaptive context gating. For local context enhancement, BiECVC reuses high-quality features from lower layers and aligns them using decoded motion vectors without introducing extra motion overhead. To model non-local dependencies efficiently, we adopt a linear attention mechanism that balances performance and complexity. To further mitigate the impact of inaccurate context prediction, we introduce Bidirectional Context Gating, inspired by data-dependent decay in recent autoregressive language models, to dynamically filter contextual information based on conditional coding results. Extensive experiments demonstrate that BiECVC achieves state-of-the-art performance, reducing the bit-rate by 13.4% and 15.7% compared to VTM 13.2 under the Random Access (RA) configuration with intra periods of 32 and 64, respectively. To our knowledge, BiECVC is the first learned video codec to surpass VTM 13.2 RA across all standard test datasets. Code will be available at https://github.com/JiangWeibeta/ECVC.
An Information-Theoretic Regularizer for Lossy Neural Image Compression
Nov 23, 2024



Lossy image compression networks aim to minimize the latent entropy of images while adhering to specific distortion constraints. However, optimizing the neural network can be challenging due to its nature of learning quantized latent representations. In this paper, our key finding is that minimizing the latent entropy is, to some extent, equivalent to maximizing the conditional source entropy, an insight that is deeply rooted in information-theoretic equalities. Building on this insight, we propose a novel structural regularization method for the neural image compression task by incorporating the negative conditional source entropy into the training objective, such that both the optimization efficacy and the model's generalization ability can be promoted. The proposed information-theoretic regularizer is interpretable, plug-and-play, and imposes no inference overheads. Extensive experiments demonstrate its superiority in regularizing the models and further squeezing bits from the latent representation across various compression structures and unseen domains.
ECVC: Exploiting Non-Local Correlations in Multiple Frames for Contextual Video Compression
Oct 13, 2024



In Learned Video Compression (LVC), improving inter prediction, such as enhancing temporal context mining and mitigating accumulated errors, is crucial for boosting rate-distortion performance. Existing LVCs mainly focus on mining the temporal movements within adjacent frames, neglecting non-local correlations among frames. Additionally, current contextual video compression models use a single reference frame, which is insufficient for handling complex movements. To address these issues, we propose leveraging non-local correlations across multiple frames to enhance temporal priors, significantly boosting rate-distortion performance. To mitigate error accumulation, we introduce a partial cascaded fine-tuning strategy that supports fine-tuning on full-length sequences with constrained computational resources. This method reduces the train-test mismatch in sequence lengths and significantly decreases accumulated errors. Based on the proposed techniques, we present a video compression scheme ECVC. Experiments demonstrate that our ECVC achieves state-of-the-art performance, reducing 7.3% and 10.5% more bit-rates than DCVC-DC and DCVC-FM over VTM-13.2 low delay B (LDB), respectively, when the intra period (IP) is 32. Additionally, ECVC reduces 11.1% more bit-rate than DCVC-FM over VTM-13.2 LDB when the IP is -1. Our Code will be available at https://github.com/JiangWeibeta/ECVC.
A Neural-network Enhanced Video Coding Framework beyond ECM
Feb 21, 2024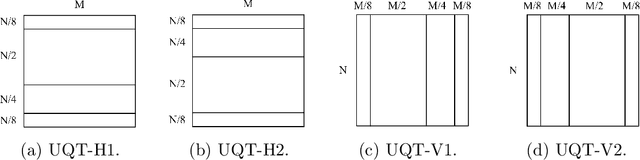

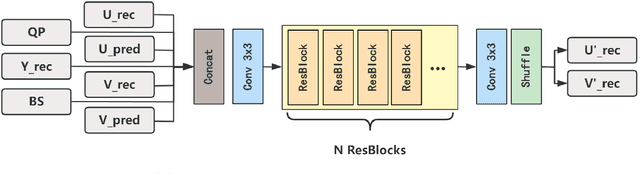
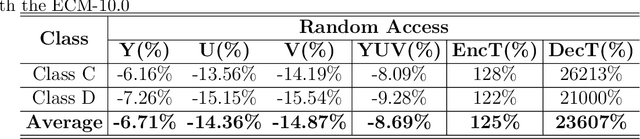
In this paper, a hybrid video compression framework is proposed that serves as a demonstrative showcase of deep learning-based approaches extending beyond the confines of traditional coding methodologies. The proposed hybrid framework is founded upon the Enhanced Compression Model (ECM), which is a further enhancement of the Versatile Video Coding (VVC) standard. We have augmented the latest ECM reference software with well-designed coding techniques, including block partitioning, deep learning-based loop filter, and the activation of block importance mapping (BIM) which was integrated but previously inactive within ECM, further enhancing coding performance. Compared with ECM-10.0, our method achieves 6.26, 13.33, and 12.33 BD-rate savings for the Y, U, and V components under random access (RA) configuration, respectively.
LVC-LGMC: Joint Local and Global Motion Compensation for Learned Video Compression
Feb 04, 2024Existing learned video compression models employ flow net or deformable convolutional networks (DCN) to estimate motion information. However, the limited receptive fields of flow net and DCN inherently direct their attentiveness towards the local contexts. Global contexts, such as large-scale motions and global correlations among frames are ignored, presenting a significant bottleneck for capturing accurate motions. To address this issue, we propose a joint local and global motion compensation module (LGMC) for leaned video coding. More specifically, we adopt flow net for local motion compensation. To capture global context, we employ the cross attention in feature domain for motion compensation. In addition, to avoid the quadratic complexity of vanilla cross attention, we divide the softmax operations in attention into two independent softmax operations, leading to linear complexity. To validate the effectiveness of our proposed LGMC, we integrate it with DCVC-TCM and obtain learned video compression with joint local and global motion compensation (LVC-LGMC). Extensive experiments demonstrate that our LVC-LGMC has significant rate-distortion performance improvements over baseline DCVC-TCM.
* Fix typos and Fig.1 and Fig.2. Accepted at ICASSP 2024. The first attempt to use cross attention for bits-free motion estimation and motion compensation
Designs and Implementations in Neural Network-based Video Coding
Sep 13, 2023
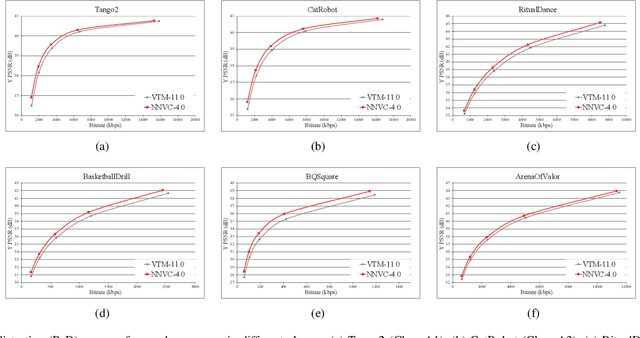
The past decade has witnessed the huge success of deep learning in well-known artificial intelligence applications such as face recognition, autonomous driving, and large language model like ChatGPT. Recently, the application of deep learning has been extended to a much wider range, with neural network-based video coding being one of them. Neural network-based video coding can be performed at two different levels: embedding neural network-based (NN-based) coding tools into a classical video compression framework or building the entire compression framework upon neural networks. This paper elaborates some of the recent exploration efforts of JVET (Joint Video Experts Team of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC29) in the name of neural network-based video coding (NNVC), falling in the former category. Specifically, this paper discusses two major NN-based video coding technologies, i.e. neural network-based intra prediction and neural network-based in-loop filtering, which have been investigated for several meeting cycles in JVET and finally adopted into the reference software of NNVC. Extensive experiments on top of the NNVC have been conducted to evaluate the effectiveness of the proposed techniques. Compared with VTM-11.0_nnvc, the proposed NN-based coding tools in NNVC-4.0 could achieve {11.94%, 21.86%, 22.59%}, {9.18%, 19.76%, 20.92%}, and {10.63%, 21.56%, 23.02%} BD-rate reductions on average for {Y, Cb, Cr} under random-access, low-delay, and all-intra configurations respectively.
Sub-sampled Cross-component Prediction for Emerging Video Coding Standards
Dec 30, 2020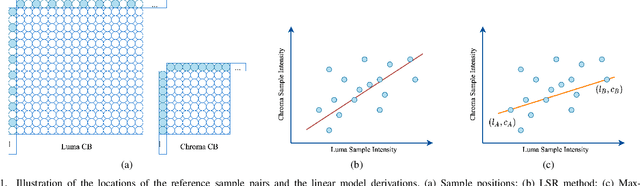

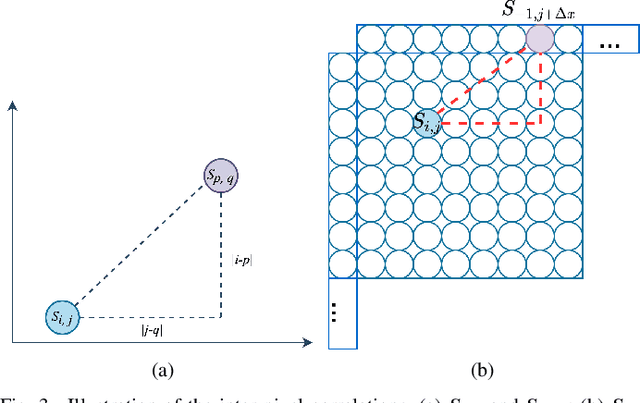
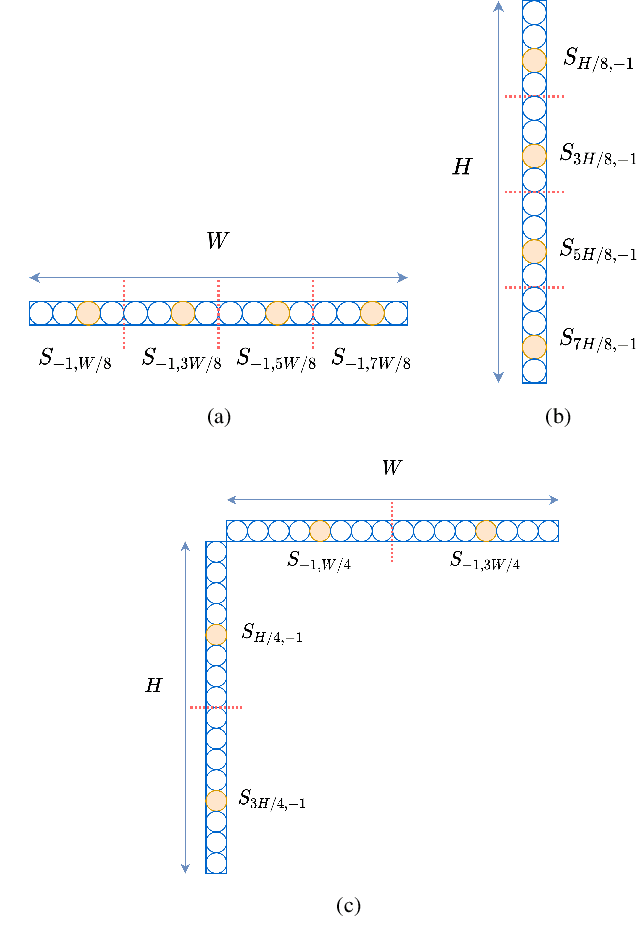
Cross-component linear model (CCLM) prediction has been repeatedly proven to be effective in reducing the inter-channel redundancies in video compression. Essentially speaking, the linear model is identically trained by employing accessible luma and chroma reference samples at both encoder and decoder, elevating the level of operational complexity due to the least square regression or max-min based model parameter derivation. In this paper, we investigate the capability of the linear model in the context of sub-sampled based cross-component correlation mining, as a means of significantly releasing the operation burden and facilitating the hardware and software design for both encoder and decoder. In particular, the sub-sampling ratios and positions are elaborately designed by exploiting the spatial correlation and the inter-channel correlation. Extensive experiments verify that the proposed method is characterized by its simplicity in operation and robustness in terms of rate-distortion performance, leading to the adoption by Versatile Video Coding (VVC) standard and the third generation of Audio Video Coding Standard (AVS3).