 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigns and Implementations in Neural Network-based Video Coding
Sep 13, 2023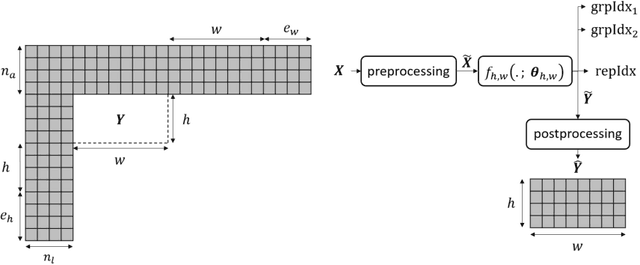
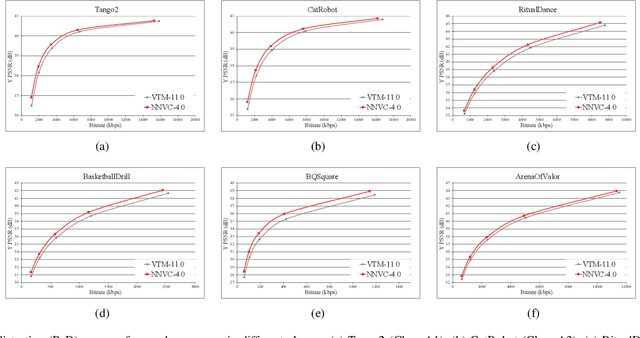
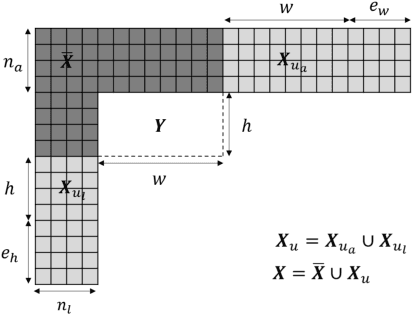
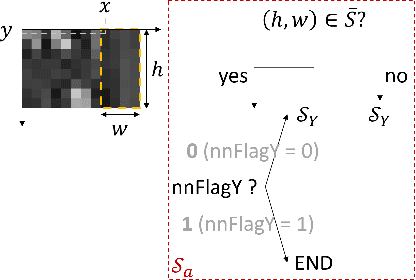
The past decade has witnessed the huge success of deep learning in well-known artificial intelligence applications such as face recognition, autonomous driving, and large language model like ChatGPT. Recently, the application of deep learning has been extended to a much wider range, with neural network-based video coding being one of them. Neural network-based video coding can be performed at two different levels: embedding neural network-based (NN-based) coding tools into a classical video compression framework or building the entire compression framework upon neural networks. This paper elaborates some of the recent exploration efforts of JVET (Joint Video Experts Team of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC29) in the name of neural network-based video coding (NNVC), falling in the former category. Specifically, this paper discusses two major NN-based video coding technologies, i.e. neural network-based intra prediction and neural network-based in-loop filtering, which have been investigated for several meeting cycles in JVET and finally adopted into the reference software of NNVC. Extensive experiments on top of the NNVC have been conducted to evaluate the effectiveness of the proposed techniques. Compared with VTM-11.0_nnvc, the proposed NN-based coding tools in NNVC-4.0 could achieve {11.94%, 21.86%, 22.59%}, {9.18%, 19.76%, 20.92%}, and {10.63%, 21.56%, 23.02%} BD-rate reductions on average for {Y, Cb, Cr} under random-access, low-delay, and all-intra configurations respectively.
A Combined Deep Learning based End-to-End Video Coding Architecture for YUV Color Space
Apr 01, 2021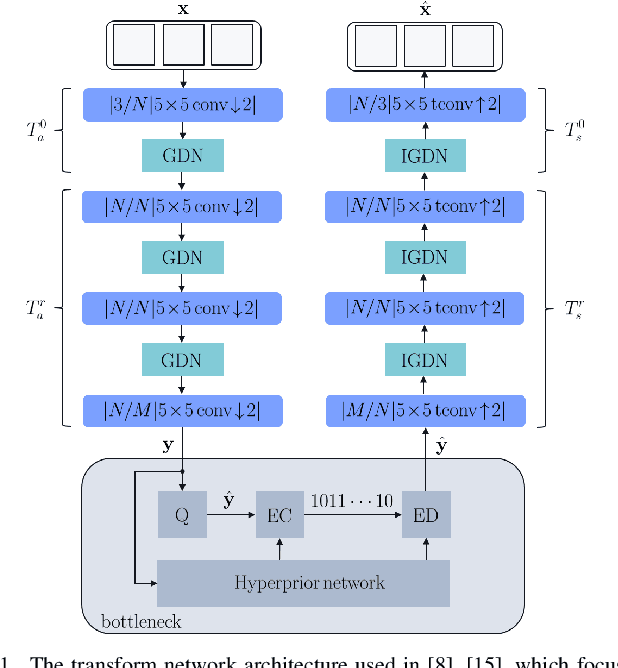
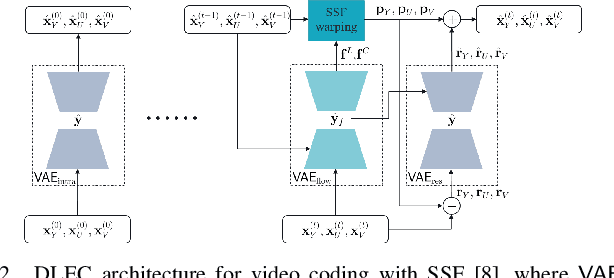

Most of the existing deep learning based end-to-end video coding (DLEC) architectures are designed specifically for RGB color format, yet the video coding standards, including H.264/AVC, H.265/HEVC and H.266/VVC developed over past few decades, have been designed primarily for YUV 4:2:0 format, where the chrominance (U and V) components are subsampled to achieve superior compression performances considering the human visual system. While a broad number of papers on DLEC compare these two distinct coding schemes in RGB domain, it is ideal to have a common evaluation framework in YUV 4:2:0 domain for a more fair comparison. This paper introduces a new DLEC architecture for video coding to effectively support YUV 4:2:0 and compares its performance against the HEVC standard under a common evaluation framework. The experimental results on YUV 4:2:0 video sequences show that the proposed architecture can outperform HEVC in intra-frame coding, however inter-frame coding is not as efficient on contrary to the RGB coding results reported in recent papers.
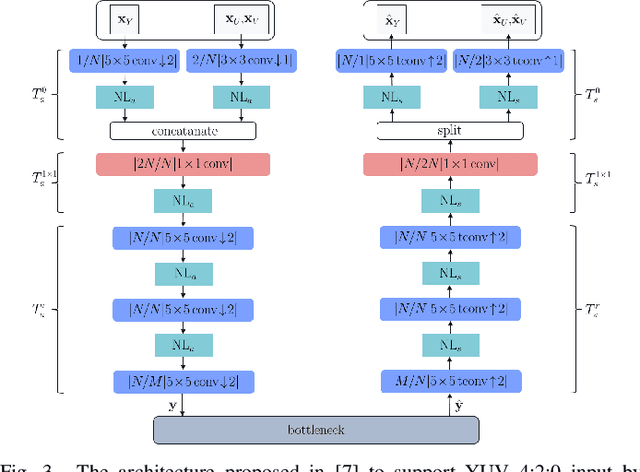
Transform Network Architectures for Deep Learning based End-to-End Image/Video Coding in Subsampled Color Spaces
Feb 27, 2021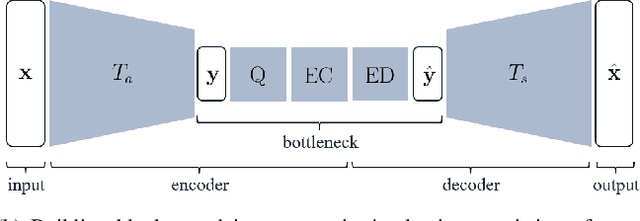



Most of the existing deep learning based end-to-end image/video coding (DLEC) architectures are designed for non-subsampled RGB color format. However, in order to achieve a superior coding performance, many state-of-the-art block-based compression standards such as High Efficiency Video Coding (HEVC/H.265) and Versatile Video Coding (VVC/H.266) are designed primarily for YUV 4:2:0 format, where U and V components are subsampled by considering the human visual system. This paper investigates various DLEC designs to support YUV 4:2:0 format by comparing their performance against the main profiles of HEVC and VVC standards under a common evaluation framework. Moreover, a new transform network architecture is proposed to improve the efficiency of coding YUV 4:2:0 data. The experimental results on YUV 4:2:0 datasets show that the proposed architecture significantly outperforms naive extensions of existing architectures designed for RGB format and achieves about 10% average BD-rate improvement over the intra-frame coding in HEVC.