 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Out-of-Distribution Detection to Hallucination Detection: A Geometric View
Feb 06, 2026Detecting hallucinations in large language models is a critical open problem with significant implications for safety and reliability. While existing hallucination detection methods achieve strong performance in question-answering tasks, they remain less effective on tasks requiring reasoning. In this work, we revisit hallucination detection through the lens of out-of-distribution (OOD) detection, a well-studied problem in areas like computer vision. Treating next-token prediction in language models as a classification task allows us to apply OOD techniques, provided appropriate modifications are made to account for the structural differences in large language models. We show that OOD-based approaches yield training-free, single-sample-based detectors, achieving strong accuracy in hallucination detection for reasoning tasks. Overall, our work suggests that reframing hallucination detection as OOD detection provides a promising and scalable pathway toward language model safety.
Can Vision-Language Models Answer Face to Face Questions in the Real-World?
Mar 25, 2025AI models have made significant strides in recent years in their ability to describe and answer questions about real-world images. They have also made progress in the ability to converse with users in real-time using audio input. This raises the question: have we reached the point where AI models, connected to a camera and microphone, can converse with users in real-time about scenes and events that are unfolding live in front of the camera? This has been a long-standing goal in AI and is a prerequisite for real-world AI assistants and humanoid robots to interact with humans in everyday situations. In this work, we introduce a new dataset and benchmark, the Qualcomm Interactive Video Dataset (IVD), which allows us to assess the extent to which existing models can support these abilities, and to what degree these capabilities can be instilled through fine-tuning. The dataset is based on a simple question-answering setup, where users ask questions that the system has to answer, in real-time, based on the camera and audio input. We show that existing models fall far behind human performance on this task, and we identify the main sources for the performance gap. However, we also show that for many of the required perceptual skills, fine-tuning on this form of data can significantly reduce this gap.
Live Fitness Coaching as a Testbed for Situated Interaction
Jul 11, 2024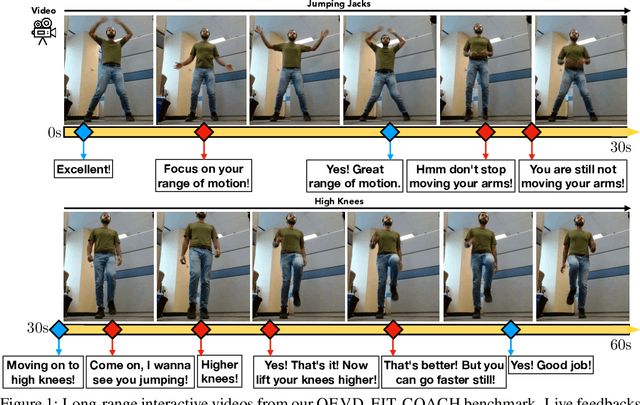



Tasks at the intersection of vision and language have had a profound impact in advancing the capabilities of vision-language models such as dialog-based assistants. However, models trained on existing tasks are largely limited to turn-based interactions, where each turn must be stepped (i.e., prompted) by the user. Open-ended, asynchronous interactions where an AI model may proactively deliver timely responses or feedback based on the unfolding situation in real-time are an open challenge. In this work, we present the QEVD benchmark and dataset which explores human-AI interaction in the challenging, yet controlled, real-world domain of fitness coaching - a task which intrinsically requires monitoring live user activity and providing timely feedback. It is the first benchmark that requires assistive vision-language models to recognize complex human actions, identify mistakes grounded in those actions, and provide appropriate feedback. Our experiments reveal the limitations of existing state of the art vision-language models for such asynchronous situated interactions. Motivated by this, we propose a simple end-to-end streaming baseline that can respond asynchronously to human actions with appropriate feedbacks at the appropriate time.
Unleashing the Creative Mind: Language Model As Hierarchical Policy For Improved Exploration on Challenging Problem Solving
Nov 01, 2023



Large Language Models (LLMs) have achieved tremendous progress, yet they still often struggle with challenging reasoning problems. Current approaches address this challenge by sampling or searching detailed and low-level reasoning chains. However, these methods are still limited in their exploration capabilities, making it challenging for correct solutions to stand out in the huge solution space. In this work, we unleash LLMs' creative potential for exploring multiple diverse problem solving strategies by framing an LLM as a hierarchical policy via in-context learning. This policy comprises of a visionary leader that proposes multiple diverse high-level problem-solving tactics as hints, accompanied by a follower that executes detailed problem-solving processes following each of the high-level instruction. The follower uses each of the leader's directives as a guide and samples multiple reasoning chains to tackle the problem, generating a solution group for each leader proposal. Additionally, we propose an effective and efficient tournament-based approach to select among these explored solution groups to reach the final answer. Our approach produces meaningful and inspiring hints, enhances problem-solving strategy exploration, and improves the final answer accuracy on challenging problems in the MATH dataset. Code will be released at https://github.com/lz1oceani/LLM-As-Hierarchical-Policy.
Painter: Teaching Auto-regressive Language Models to Draw Sketches
Aug 16, 2023
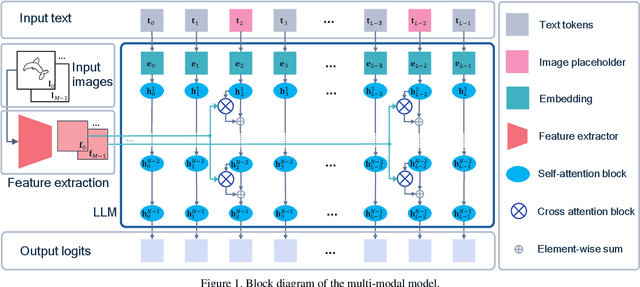

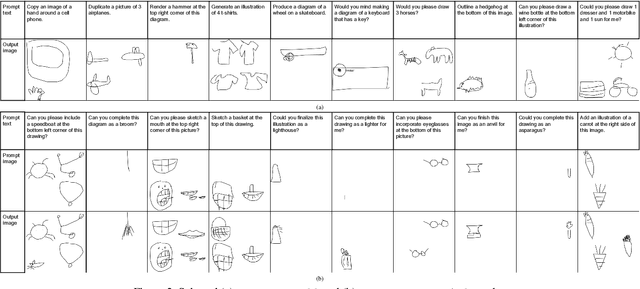
Large language models (LLMs) have made tremendous progress in natural language understanding and they have also been successfully adopted in other domains such as computer vision, robotics, reinforcement learning, etc. In this work, we apply LLMs to image generation tasks by directly generating the virtual brush strokes to paint an image. We present Painter, an LLM that can convert user prompts in text description format to sketches by generating the corresponding brush strokes in an auto-regressive way. We construct Painter based on off-the-shelf LLM that is pre-trained on a large text corpus, by fine-tuning it on the new task while preserving language understanding capabilities. We create a dataset of diverse multi-object sketches paired with textual prompts that covers several object types and tasks. Painter can generate sketches from text descriptions, remove objects from canvas, and detect and classify objects in sketches. Although this is an unprecedented pioneering work in using LLMs for auto-regressive image generation, the results are very encouraging.
Look, Remember and Reason: Visual Reasoning with Grounded Rationales
Jun 30, 2023



Large language models have recently shown human level performance on a variety of reasoning tasks. However, the ability of these models to perform complex visual reasoning has not been studied in detail yet. A key challenge in many visual reasoning tasks is that the visual information needs to be tightly integrated in the reasoning process. We propose to address this challenge by drawing inspiration from human visual problem solving which depends on a variety of low-level visual capabilities. It can often be cast as the three step-process of ``Look, Remember, Reason'': visual information is incrementally extracted using low-level visual routines in a step-by-step fashion until a final answer is reached. We follow the same paradigm to enable existing large language models, with minimal changes to the architecture, to solve visual reasoning problems. To this end, we introduce rationales over the visual input that allow us to integrate low-level visual capabilities, such as object recognition and tracking, as surrogate tasks. We show competitive performance on diverse visual reasoning tasks from the CLEVR, CATER, and ACRE datasets over state-of-the-art models designed specifically for these tasks.
Differentiable bit-rate estimation for neural-based video codec enhancement
Jan 24, 2023



Neural networks (NN) can improve standard video compression by pre- and post-processing the encoded video. For optimal NN training, the standard codec needs to be replaced with a codec proxy that can provide derivatives of estimated bit-rate and distortion, which are used for gradient back-propagation. Since entropy coding of standard codecs is designed to take into account non-linear dependencies between transform coefficients, bit-rates cannot be well approximated with simple per-coefficient estimators. This paper presents a new approach for bit-rate estimation that is similar to the type employed in training end-to-end neural codecs, and able to efficiently take into account those statistical dependencies. It is defined from a mathematical model that provides closed-form formulas for the estimates and their gradients, reducing the computational complexity. Experimental results demonstrate the method's accuracy in estimating HEVC/H.265 codec bit-rates.
Optimized learned entropy coding parameters for practical neural-based image and video compression
Jan 20, 2023



Neural-based image and video codecs are significantly more power-efficient when weights and activations are quantized to low-precision integers. While there are general-purpose techniques for reducing quantization effects, large losses can occur when specific entropy coding properties are not considered. This work analyzes how entropy coding is affected by parameter quantizations, and provides a method to minimize losses. It is shown that, by using a certain type of coding parameters to be learned, uniform quantization becomes practically optimal, also simplifying the minimization of code memory requirements. The mathematical properties of the new representation are presented, and its effectiveness is demonstrated by coding experiments, showing that good results can be obtained with precision as low as 4~bits per network output, and practically no loss with 8~bits.
* 2022 IEEE International Conference on Image Processing (ICIP)
Boosting neural video codecs by exploiting hierarchical redundancy
Aug 08, 2022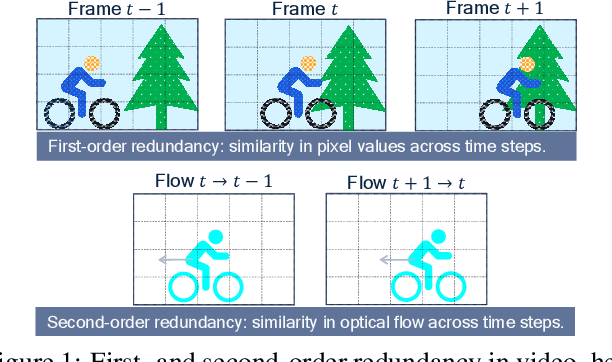
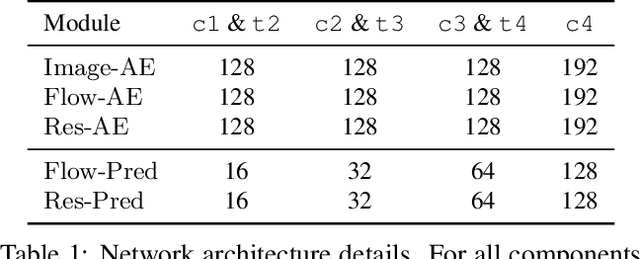
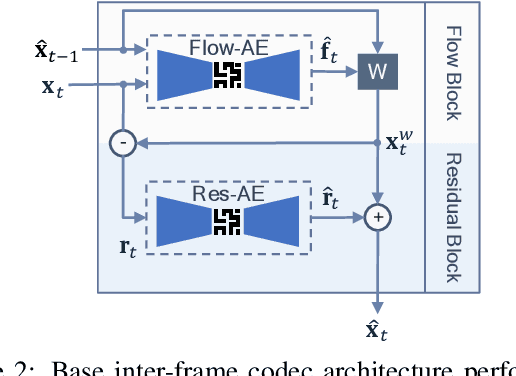
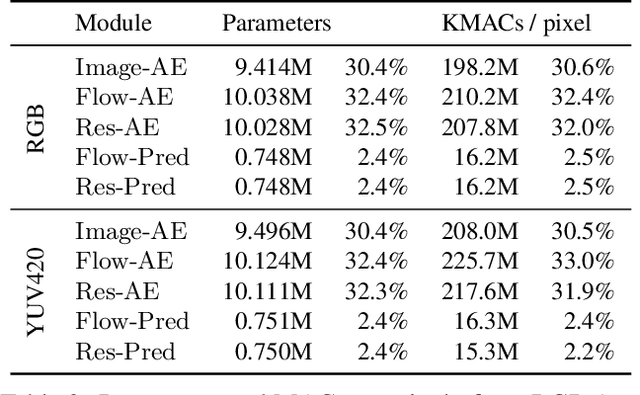
In video compression, coding efficiency is improved by reusing pixels from previously decoded frames via motion and residual compensation. We define two levels of hierarchical redundancy in video frames: 1) first-order: redundancy in pixel space, i.e., similarities in pixel values across neighboring frames, which is effectively captured using motion and residual compensation, 2) second-order: redundancy in motion and residual maps due to smooth motion in natural videos. While most of the existing neural video coding literature addresses first-order redundancy, we tackle the problem of capturing second-order redundancy in neural video codecs via predictors. We introduce generic motion and residual predictors that learn to extrapolate from previously decoded data. These predictors are lightweight, and can be employed with most neural video codecs in order to improve their rate-distortion performance. Moreover, while RGB is the dominant colorspace in neural video coding literature, we introduce general modifications for neural video codecs to embrace the YUV420 colorspace and report YUV420 results. Our experiments show that using our predictors with a well-known neural video codec leads to 38% and 34% bitrate savings in RGB and YUV420 colorspaces measured on the UVG dataset.
MobileCodec: Neural Inter-frame Video Compression on Mobile Devices
Jul 18, 2022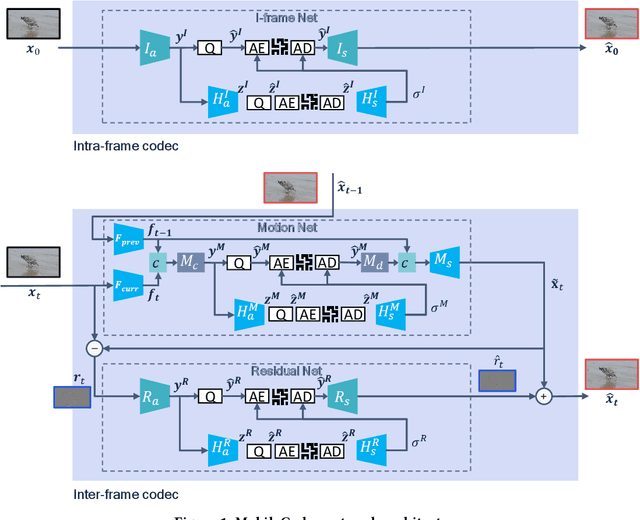
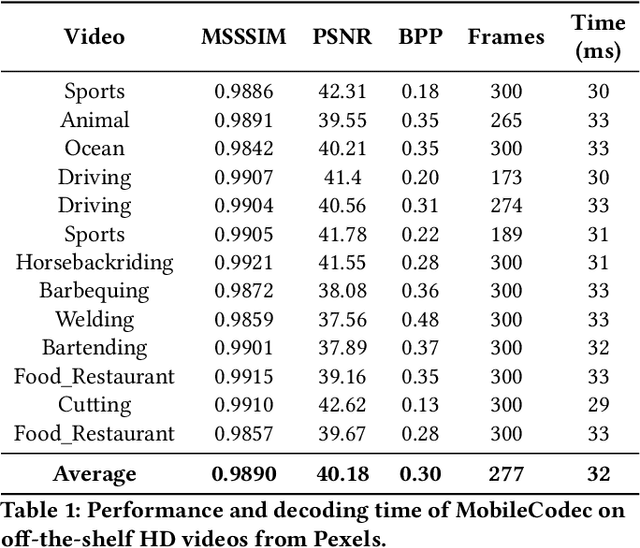
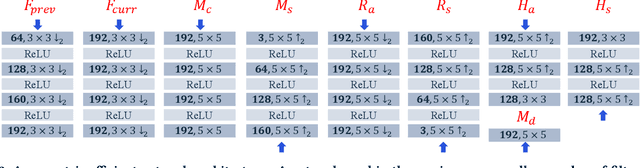
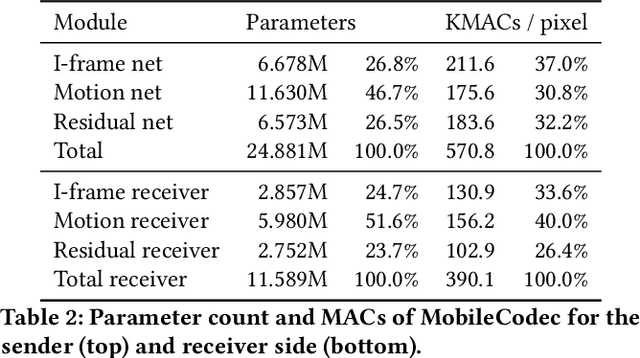
Realizing the potential of neural video codecs on mobile devices is a big technological challenge due to the computational complexity of deep networks and the power-constrained mobile hardware. We demonstrate practical feasibility by leveraging Qualcomm's technology and innovation, bridging the gap from neural network-based codec simulations running on wall-powered workstations, to real-time operation on a mobile device powered by Snapdragon technology. We show the first-ever inter-frame neural video decoder running on a commercial mobile phone, decoding high-definition videos in real-time while maintaining a low bitrate and high visual quality.