 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Latency Neural Stereo Streaming
Mar 26, 2024



The rise of new video modalities like virtual reality or autonomous driving has increased the demand for efficient multi-view video compression methods, both in terms of rate-distortion (R-D) performance and in terms of delay and runtime. While most recent stereo video compression approaches have shown promising performance, they compress left and right views sequentially, leading to poor parallelization and runtime performance. This work presents Low-Latency neural codec for Stereo video Streaming (LLSS), a novel parallel stereo video coding method designed for fast and efficient low-latency stereo video streaming. Instead of using a sequential cross-view motion compensation like existing methods, LLSS introduces a bidirectional feature shifting module to directly exploit mutual information among views and encode them effectively with a joint cross-view prior model for entropy coding. Thanks to this design, LLSS processes left and right views in parallel, minimizing latency; all while substantially improving R-D performance compared to both existing neural and conventional codecs.
Clockwork Diffusion: Efficient Generation With Model-Step Distillation
Dec 13, 2023



This work aims to improve the efficiency of text-to-image diffusion models. While diffusion models use computationally expensive UNet-based denoising operations in every generation step, we identify that not all operations are equally relevant for the final output quality. In particular, we observe that UNet layers operating on high-res feature maps are relatively sensitive to small perturbations. In contrast, low-res feature maps influence the semantic layout of the final image and can often be perturbed with no noticeable change in the output. Based on this observation, we propose Clockwork Diffusion, a method that periodically reuses computation from preceding denoising steps to approximate low-res feature maps at one or more subsequent steps. For multiple baselines, and for both text-to-image generation and image editing, we demonstrate that Clockwork leads to comparable or improved perceptual scores with drastically reduced computational complexity. As an example, for Stable Diffusion v1.5 with 8 DPM++ steps we save 32% of FLOPs with negligible FID and CLIP change.
MobileNVC: Real-time 1080p Neural Video Compression on a Mobile Device
Oct 02, 2023



Neural video codecs have recently become competitive with standard codecs such as HEVC in the low-delay setting. However, most neural codecs are large floating-point networks that use pixel-dense warping operations for temporal modeling, making them too computationally expensive for deployment on mobile devices. Recent work has demonstrated that running a neural decoder in real time on mobile is feasible, but shows this only for 720p RGB video, while the YUV420 format is more commonly used in production. This work presents the first neural video codec that decodes 1080p YUV420 video in real time on a mobile device. Our codec relies on two major contributions. First, we design an efficient codec that uses a block-based motion compensation algorithm available on the warping core of the mobile accelerator, and we show how to quantize this model to integer precision. Second, we implement a fast decoder pipeline that concurrently runs neural network components on the neural signal processor, parallel entropy coding on the mobile GPU, and warping on the warping core. Our codec outperforms the previous on-device codec by a large margin with up to 48 % BD-rate savings, while reducing the MAC count on the receiver side by 10x. We perform a careful ablation to demonstrate the effect of the introduced motion compensation scheme, and ablate the effect of model quantization.
Boosting neural video codecs by exploiting hierarchical redundancy
Aug 08, 2022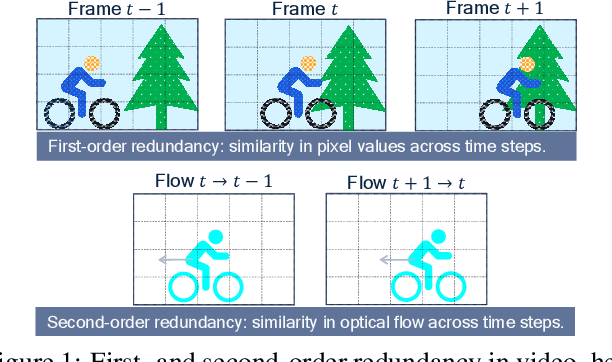
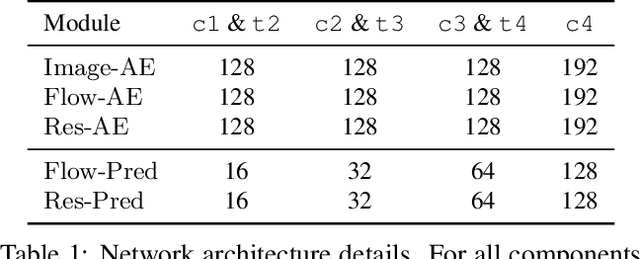
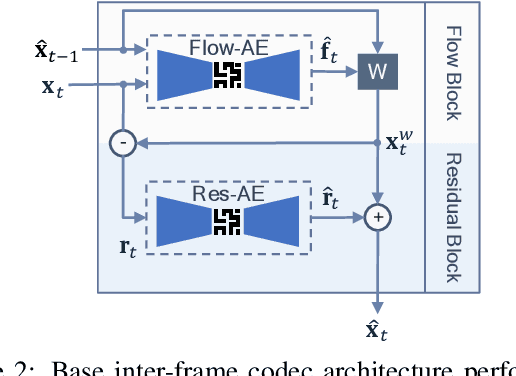
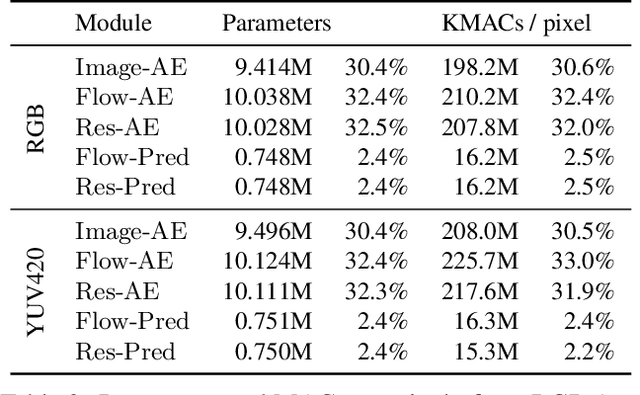
In video compression, coding efficiency is improved by reusing pixels from previously decoded frames via motion and residual compensation. We define two levels of hierarchical redundancy in video frames: 1) first-order: redundancy in pixel space, i.e., similarities in pixel values across neighboring frames, which is effectively captured using motion and residual compensation, 2) second-order: redundancy in motion and residual maps due to smooth motion in natural videos. While most of the existing neural video coding literature addresses first-order redundancy, we tackle the problem of capturing second-order redundancy in neural video codecs via predictors. We introduce generic motion and residual predictors that learn to extrapolate from previously decoded data. These predictors are lightweight, and can be employed with most neural video codecs in order to improve their rate-distortion performance. Moreover, while RGB is the dominant colorspace in neural video coding literature, we introduce general modifications for neural video codecs to embrace the YUV420 colorspace and report YUV420 results. Our experiments show that using our predictors with a well-known neural video codec leads to 38% and 34% bitrate savings in RGB and YUV420 colorspaces measured on the UVG dataset.
MobileCodec: Neural Inter-frame Video Compression on Mobile Devices
Jul 18, 2022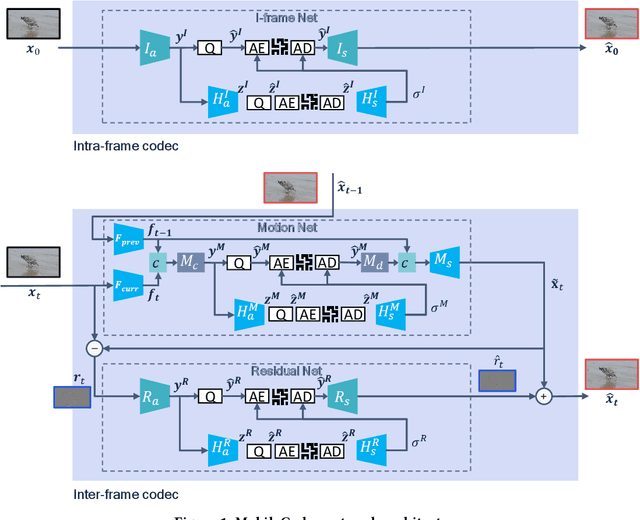
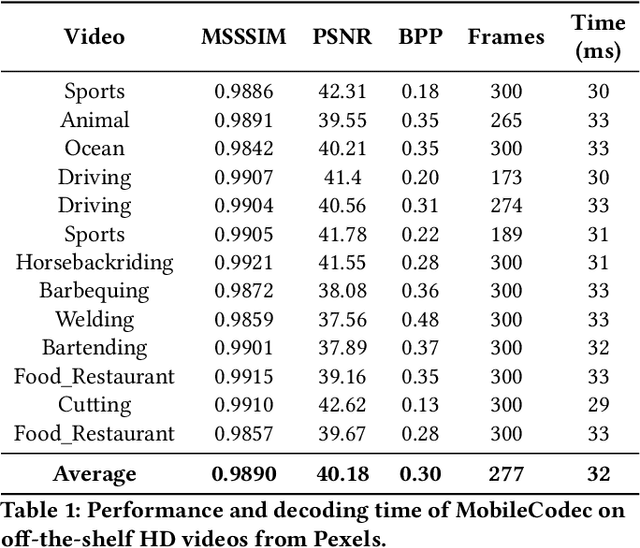
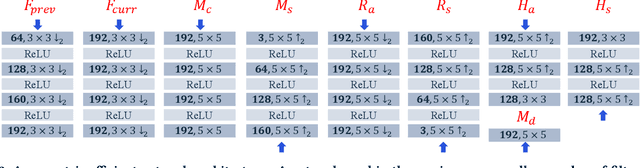
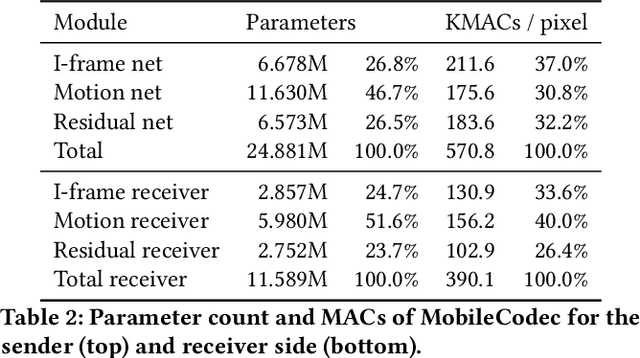
Realizing the potential of neural video codecs on mobile devices is a big technological challenge due to the computational complexity of deep networks and the power-constrained mobile hardware. We demonstrate practical feasibility by leveraging Qualcomm's technology and innovation, bridging the gap from neural network-based codec simulations running on wall-powered workstations, to real-time operation on a mobile device powered by Snapdragon technology. We show the first-ever inter-frame neural video decoder running on a commercial mobile phone, decoding high-definition videos in real-time while maintaining a low bitrate and high visual quality.
Feedback Recurrent Autoencoder for Video Compression
Apr 09, 2020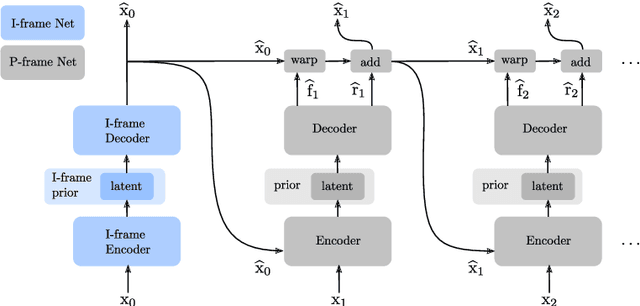
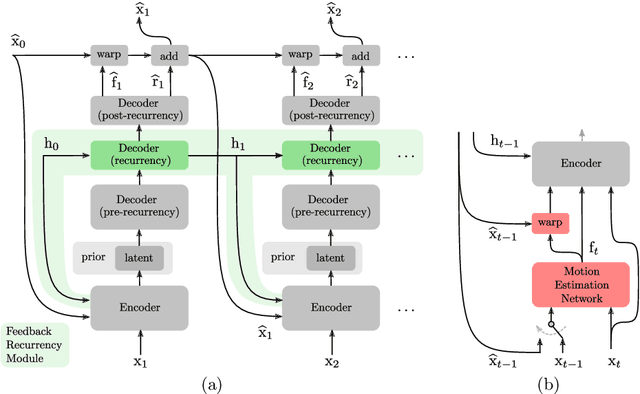
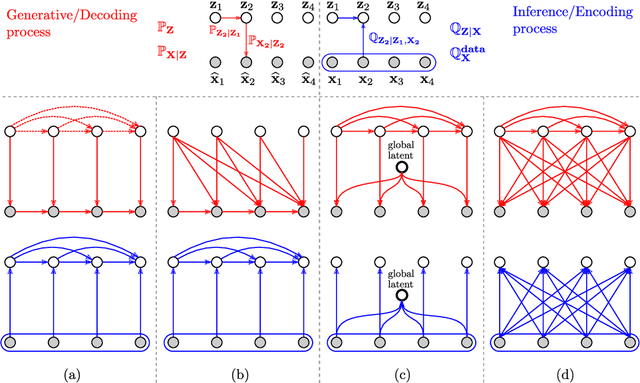
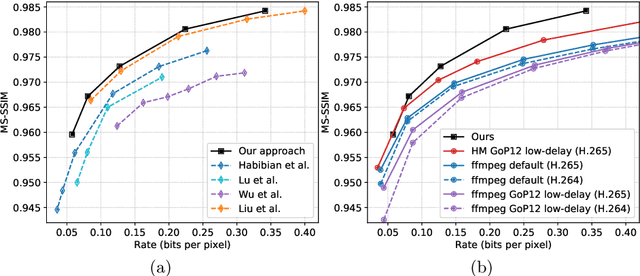
Recent advances in deep generative modeling have enabled efficient modeling of high dimensional data distributions and opened up a new horizon for solving data compression problems. Specifically, autoencoder based learned image or video compression solutions are emerging as strong competitors to traditional approaches. In this work, We propose a new network architecture, based on common and well studied components, for learned video compression operating in low latency mode. Our method yields state of the art MS-SSIM/rate performance on the high-resolution UVG dataset, among both learned video compression approaches and classical video compression methods (H.265 and H.264) in the rate range of interest for streaming applications. Additionally, we provide an analysis of existing approaches through the lens of their underlying probabilistic graphical models. Finally, we point out issues with temporal consistency and color shift observed in empirical evaluation, and suggest directions forward to alleviate those.