 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-of-Interest Based Neural Video Compression
Mar 03, 2022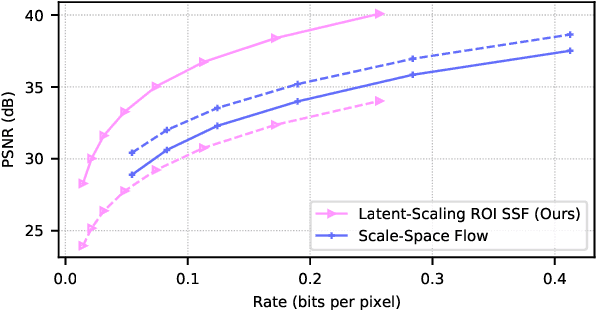

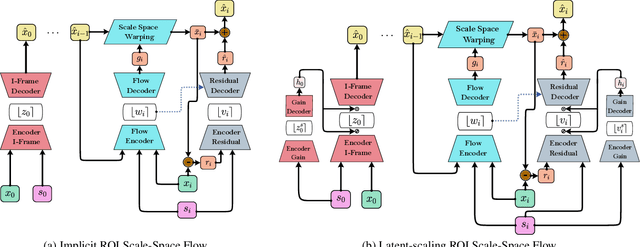
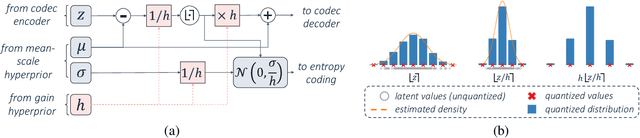
Humans do not perceive all parts of a scene with the same resolution, but rather focus on few regions of interest (ROIs). Traditional Object-Based codecs take advantage of this biological intuition, and are capable of non-uniform allocation of bits in favor of salient regions, at the expense of increased distortion the remaining areas: such a strategy allows a boost in perceptual quality under low rate constraints. Recently, several neural codecs have been introduced for video compression, yet they operate uniformly over all spatial locations, lacking the capability of ROI-based processing. In this paper, we introduce two models for ROI-based neural video coding. First, we propose an implicit model that is fed with a binary ROI mask and it is trained by de-emphasizing the distortion of the background. Secondly, we design an explicit latent scaling method, that allows control over the quantization binwidth for different spatial regions of latent variables, conditioned on the ROI mask. By extensive experiments, we show that our methods outperform all our baselines in terms of Rate-Distortion (R-D) performance in the ROI. Moreover, they can generalize to different datasets and to any arbitrary ROI at inference time. Finally, they do not require expensive pixel-level annotations during training, as synthetic ROI masks can be used with little to no degradation in performance. To the best of our knowledge, our proposals are the first solutions that integrate ROI-based capabilities into neural video compression models.
Extending Neural P-frame Codecs for B-frame Coding
Mar 30, 2021
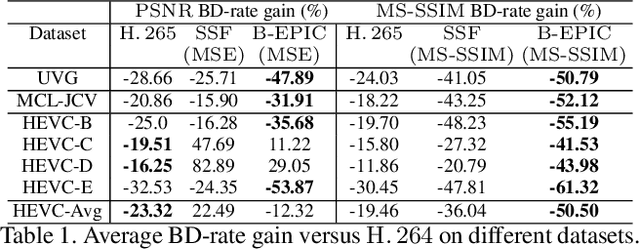
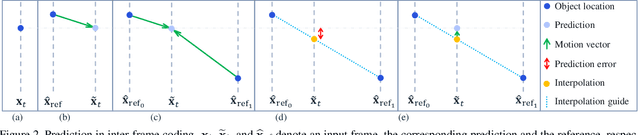

While most neural video codecs address P-frame coding (predicting each frame from past ones), in this paper we address B-frame compression (predicting frames using both past and future reference frames). Our B-frame solution is based on the existing P-frame methods. As a result, B-frame coding capability can easily be added to an existing neural codec. The basic idea of our B-frame coding method is to interpolate the two reference frames to generate a single reference frame and then use it together with an existing P-frame codec to encode the input B-frame. Our studies show that the interpolated frame is a much better reference for the P-frame codec compared to using the previous frame as is usually done. Our results show that using the proposed method with an existing P-frame codec can lead to 28.5%saving in bit-rate on the UVG dataset compared to the P-frame codec while generating the same video quality.
Progressive Neural Image Compression with Nested Quantization and Latent Ordering
Feb 04, 2021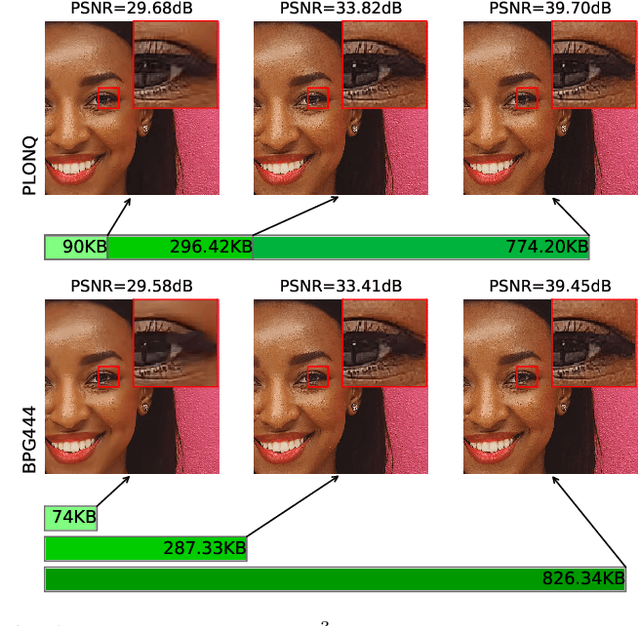

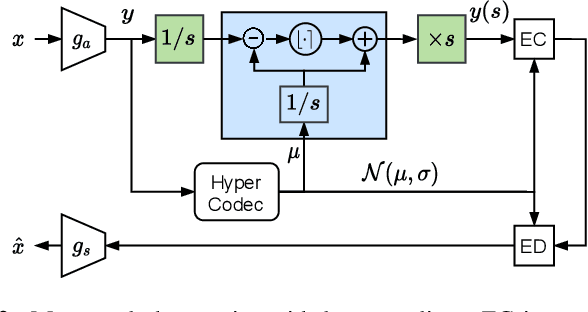
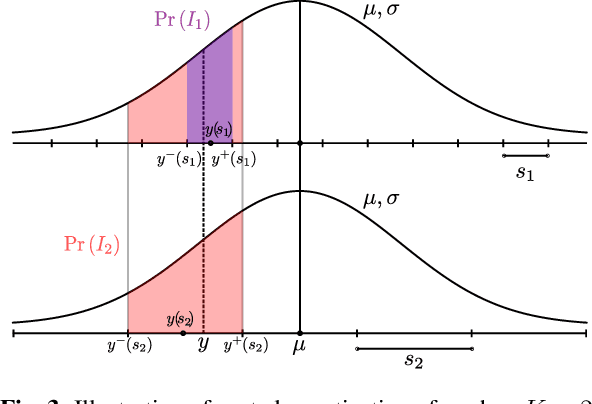
We present PLONQ, a progressive neural image compression scheme which pushes the boundary of variable bitrate compression by allowing quality scalable coding with a single bitstream. In contrast to existing learned variable bitrate solutions which produce separate bitstreams for each quality, it enables easier rate-control and requires less storage. Leveraging the latent scaling based variable bitrate solution, we introduce nested quantization, a method that defines multiple quantization levels with nested quantization grids, and progressively refines all latents from the coarsest to the finest quantization level. To achieve finer progressiveness in between any two quantization levels, latent elements are incrementally refined with an importance ordering defined in the rate-distortion sense. To the best of our knowledge, PLONQ is the first learning-based progressive image coding scheme and it outperforms SPIHT, a well-known wavelet-based progressive image codec.
Feedback Recurrent Autoencoder for Video Compression
Apr 09, 2020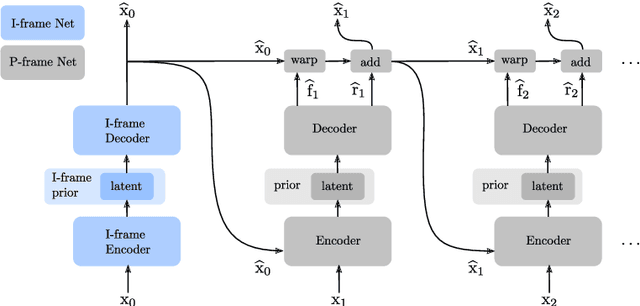
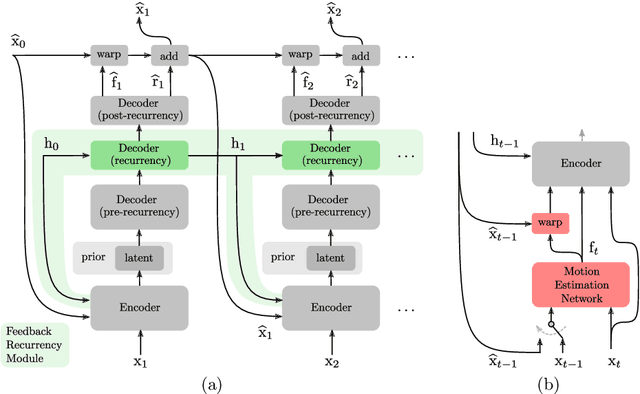
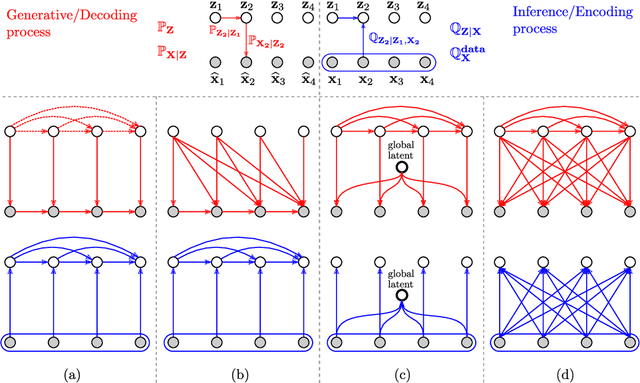
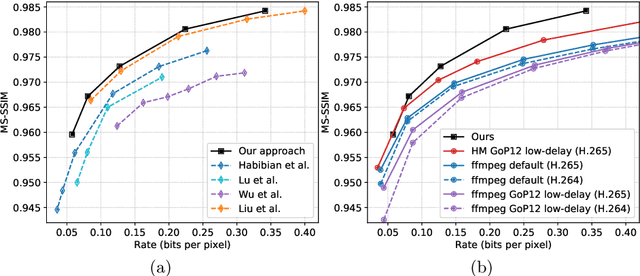
Recent advances in deep generative modeling have enabled efficient modeling of high dimensional data distributions and opened up a new horizon for solving data compression problems. Specifically, autoencoder based learned image or video compression solutions are emerging as strong competitors to traditional approaches. In this work, We propose a new network architecture, based on common and well studied components, for learned video compression operating in low latency mode. Our method yields state of the art MS-SSIM/rate performance on the high-resolution UVG dataset, among both learned video compression approaches and classical video compression methods (H.265 and H.264) in the rate range of interest for streaming applications. Additionally, we provide an analysis of existing approaches through the lens of their underlying probabilistic graphical models. Finally, we point out issues with temporal consistency and color shift observed in empirical evaluation, and suggest directions forward to alleviate those.
Feedback Recurrent AutoEncoder
Nov 11, 2019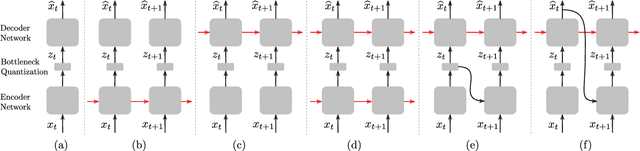
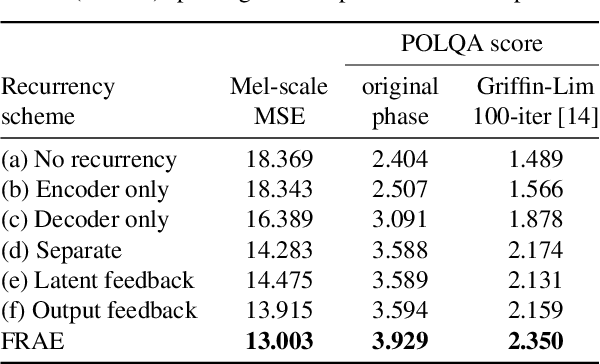
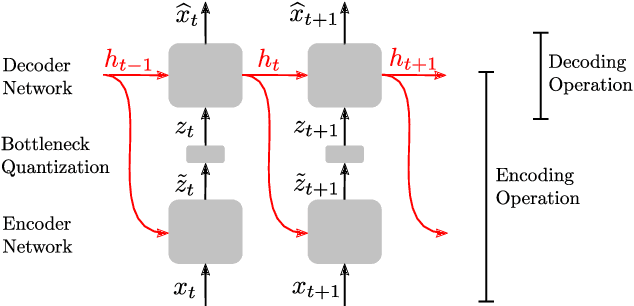
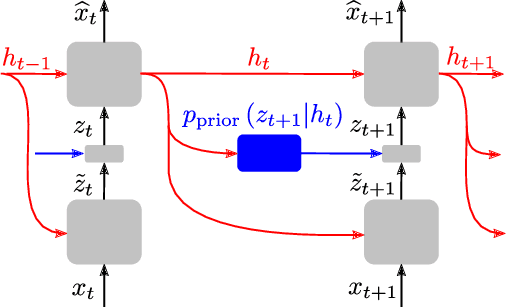
In this work, we propose a new recurrent autoencoder architecture, termed Feedback Recurrent AutoEncoder (FRAE), for online compression of sequential data with temporal dependency. The recurrent structure of FRAE is designed to efficiently extract the redundancy along the time dimension and allows a compact discrete representation of the data to be learned. We demonstrate its effectiveness in speech spectrogram compression. Specifically, we show that the FRAE, paired with a powerful neural vocoder, can produce high-quality speech waveforms at a low, fixed bitrate. We further show that by adding a learned prior for the latent space and using an entropy coder, we can achieve an even lower variable bitrate.
Visualizing Deep Neural Network Decisions: Prediction Difference Analysis
Feb 15, 2017


This article presents the prediction difference analysis method for visualizing the response of a deep neural network to a specific input. When classifying images, the method highlights areas in a given input image that provide evidence for or against a certain class. It overcomes several shortcoming of previous methods and provides great additional insight into the decision making process of classifiers. Making neural network decisions interpretable through visualization is important both to improve models and to accelerate the adoption of black-box classifiers in application areas such as medicine. We illustrate the method in experiments on natural images (ImageNet data), as well as medical images (MRI brain scans).