 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Meta-Learning via Mixed-Mode Differentiation
May 01, 2025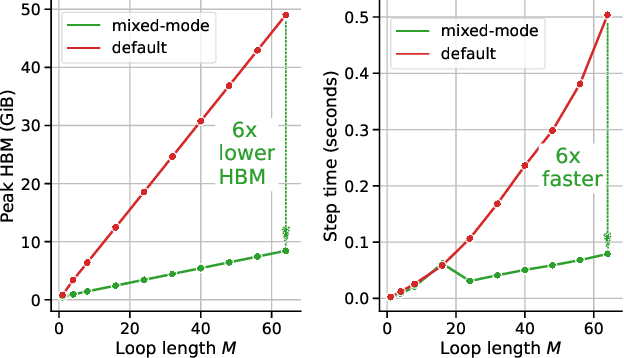
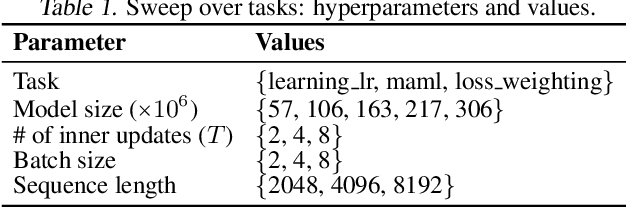
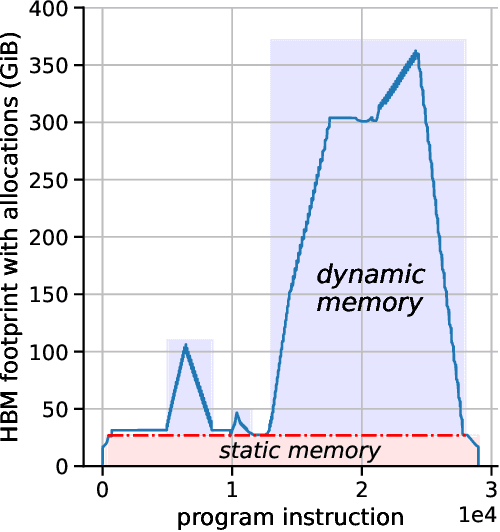
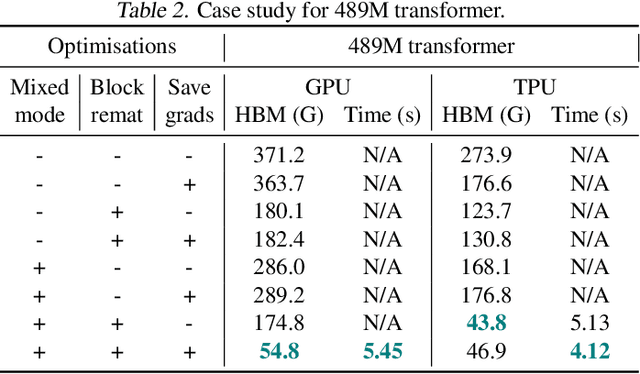
Gradient-based bilevel optimisation is a powerful technique with applications in hyperparameter optimisation, task adaptation, algorithm discovery, meta-learning more broadly, and beyond. It often requires differentiating through the gradient-based optimisation process itself, leading to "gradient-of-a-gradient" calculations with computationally expensive second-order and mixed derivatives. While modern automatic differentiation libraries provide a convenient way to write programs for calculating these derivatives, they oftentimes cannot fully exploit the specific structure of these problems out-of-the-box, leading to suboptimal performance. In this paper, we analyse such cases and propose Mixed-Flow Meta-Gradients, or MixFlow-MG -- a practical algorithm that uses mixed-mode differentiation to construct more efficient and scalable computational graphs yielding over 10x memory and up to 25% wall-clock time improvements over standard implementations in modern meta-learning setups.
Prospect Pruning: Finding Trainable Weights at Initialization using Meta-Gradients
Feb 16, 2022
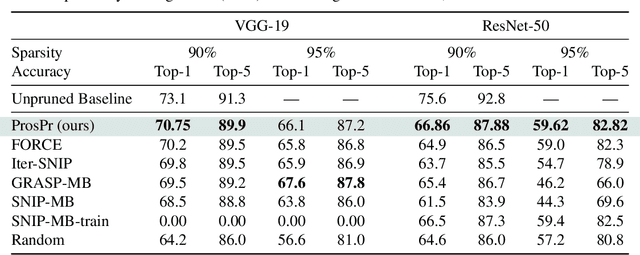
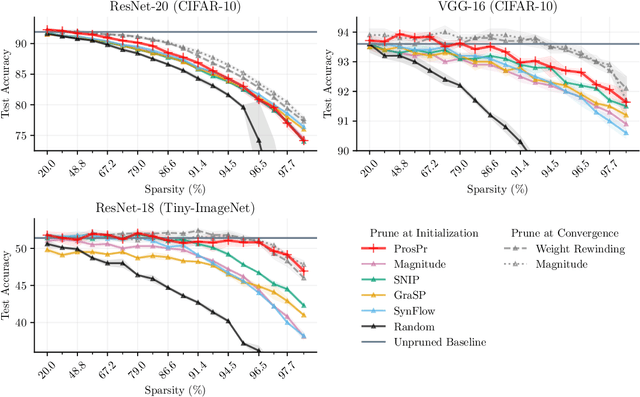
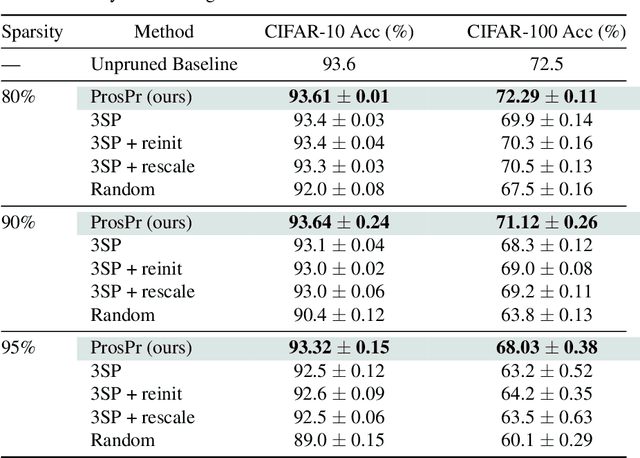
Pruning neural networks at initialization would enable us to find sparse models that retain the accuracy of the original network while consuming fewer computational resources for training and inference. However, current methods are insufficient to enable this optimization and lead to a large degradation in model performance. In this paper, we identify a fundamental limitation in the formulation of current methods, namely that their saliency criteria look at a single step at the start of training without taking into account the trainability of the network. While pruning iteratively and gradually has been shown to improve pruning performance, explicit consideration of the training stage that will immediately follow pruning has so far been absent from the computation of the saliency criterion. To overcome the short-sightedness of existing methods, we propose Prospect Pruning (ProsPr), which uses meta-gradients through the first few steps of optimization to determine which weights to prune. ProsPr combines an estimate of the higher-order effects of pruning on the loss and the optimization trajectory to identify the trainable sub-network. Our method achieves state-of-the-art pruning performance on a variety of vision classification tasks, with less data and in a single shot compared to existing pruning-at-initialization methods.
CAML: Fast Context Adaptation via Meta-Learning
Oct 12, 2018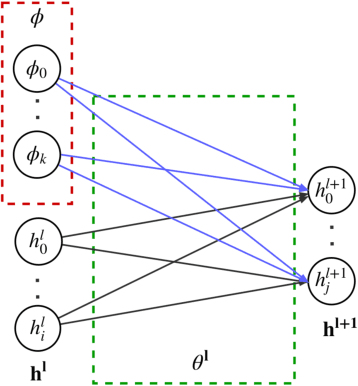

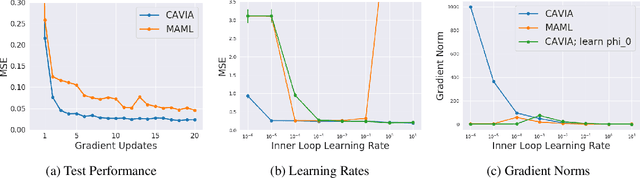
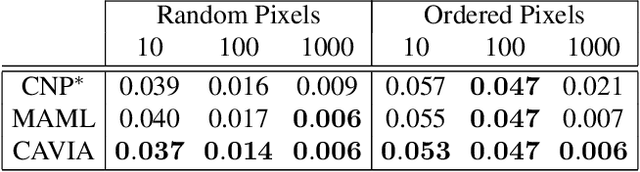
We propose CAML, a meta-learning method for fast adaptation that partitions the model parameters into two parts: context parameters that serve as additional input to the model and are adapted on individual tasks, and shared parameters that are meta-trained and shared across tasks. At test time, the context parameters are updated with one or several gradient steps on a task-specific loss that is backpropagated through the shared part of the network. Compared to approaches that adjust all parameters on a new task (e.g., MAML), our method can be scaled up to larger networks without overfitting on a single task, is easier to implement, and saves memory writes during training and network communication at test time for distributed machine learning systems. We show empirically that this approach outperforms MAML, is less sensitive to the task-specific learning rate, can capture meaningful task embeddings with the context parameters, and outperforms alternative partitionings of the parameter vectors.
Ordered Preference Elicitation Strategies for Supporting Multi-Objective Decision Making
Feb 21, 2018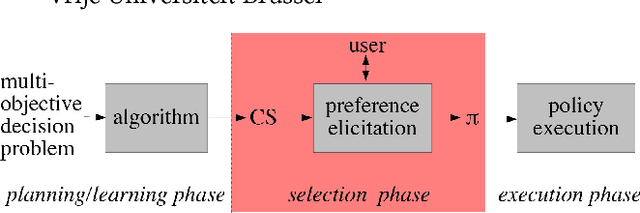

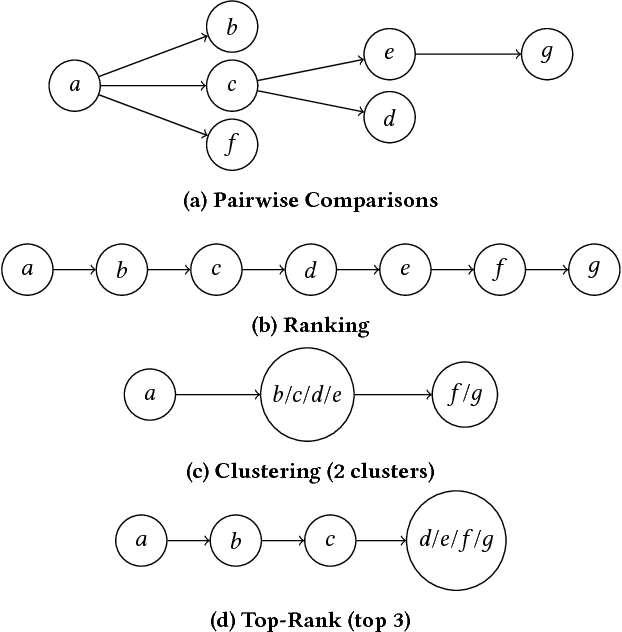
In multi-objective decision planning and learning, much attention is paid to producing optimal solution sets that contain an optimal policy for every possible user preference profile. We argue that the step that follows, i.e, determining which policy to execute by maximising the user's intrinsic utility function over this (possibly infinite) set, is under-studied. This paper aims to fill this gap. We build on previous work on Gaussian processes and pairwise comparisons for preference modelling, extend it to the multi-objective decision support scenario, and propose new ordered preference elicitation strategies based on ranking and clustering. Our main contribution is an in-depth evaluation of these strategies using computer and human-based experiments. We show that our proposed elicitation strategies outperform the currently used pairwise methods, and found that users prefer ranking most. Our experiments further show that utilising monotonicity information in GPs by using a linear prior mean at the start and virtual comparisons to the nadir and ideal points, increases performance. We demonstrate our decision support framework in a real-world study on traffic regulation, conducted with the city of Amsterdam.
Visualizing Deep Neural Network Decisions: Prediction Difference Analysis
Feb 15, 2017
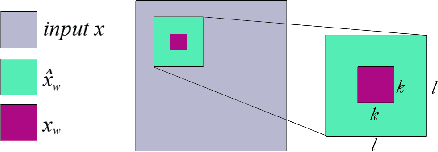


This article presents the prediction difference analysis method for visualizing the response of a deep neural network to a specific input. When classifying images, the method highlights areas in a given input image that provide evidence for or against a certain class. It overcomes several shortcoming of previous methods and provides great additional insight into the decision making process of classifiers. Making neural network decisions interpretable through visualization is important both to improve models and to accelerate the adoption of black-box classifiers in application areas such as medicine. We illustrate the method in experiments on natural images (ImageNet data), as well as medical images (MRI brain scans).