 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling for Factored Multi-Agent Bandits
Nov 22, 2019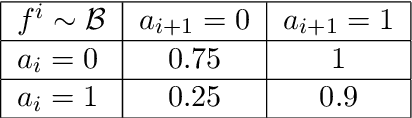
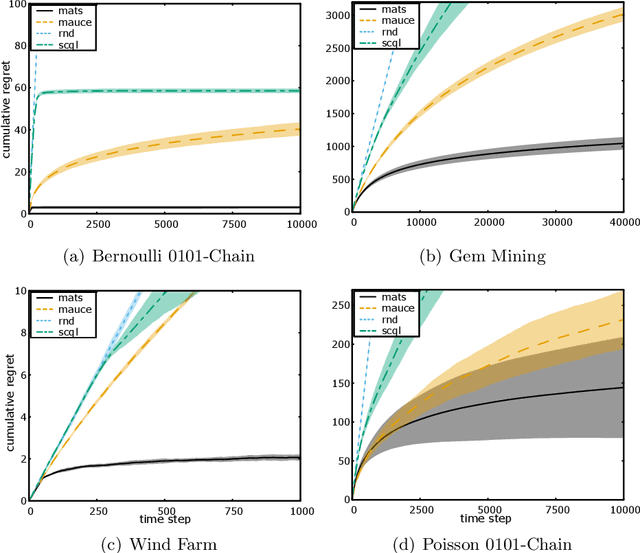
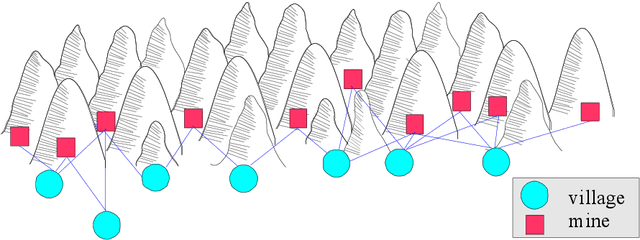
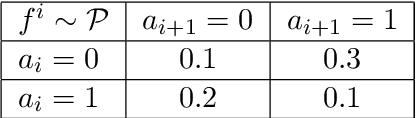
Multi-agent coordination is prevalent in many real-world applications. However, such coordination is challenging due to its combinatorial nature. An important observation in this regard is that agents in the real world often only directly affect a limited set of neighboring agents. Leveraging such loose couplings among agents is key to making coordination in multi-agent systems feasible. In this work, we focus on learning to coordinate. Specifically, we consider the multi-agent multi-armed bandit framework, in which fully cooperative loosely-coupled agents must learn to coordinate their decisions to optimize a common objective. As opposed to in the planning setting, for learning methods it is challenging to establish theoretical guarantees. We propose multi-agent Thompson sampling (MATS), a new Bayesian exploration-exploitation algorithm that leverages loose couplings. We provide a regret bound that is sublinear in time and low-order polynomial in the highest number of actions of a single agent for sparse coordination graphs. Finally, we empirically show that MATS outperforms the state-of-the-art algorithm, MAUCE, on two synthetic benchmarks, a realistic wind farm control task, and a novel benchmark with Poisson distributions.
Ordered Preference Elicitation Strategies for Supporting Multi-Objective Decision Making
Feb 21, 2018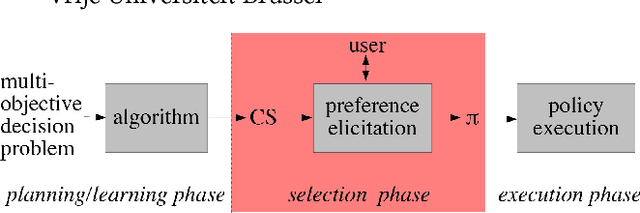

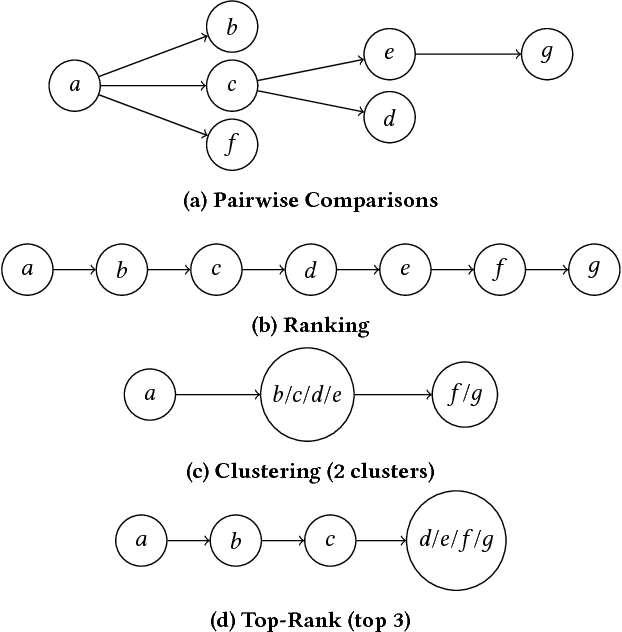
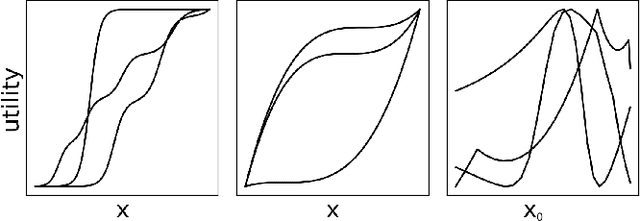
In multi-objective decision planning and learning, much attention is paid to producing optimal solution sets that contain an optimal policy for every possible user preference profile. We argue that the step that follows, i.e, determining which policy to execute by maximising the user's intrinsic utility function over this (possibly infinite) set, is under-studied. This paper aims to fill this gap. We build on previous work on Gaussian processes and pairwise comparisons for preference modelling, extend it to the multi-objective decision support scenario, and propose new ordered preference elicitation strategies based on ranking and clustering. Our main contribution is an in-depth evaluation of these strategies using computer and human-based experiments. We show that our proposed elicitation strategies outperform the currently used pairwise methods, and found that users prefer ranking most. Our experiments further show that utilising monotonicity information in GPs by using a linear prior mean at the start and virtual comparisons to the nadir and ideal points, increases performance. We demonstrate our decision support framework in a real-world study on traffic regulation, conducted with the city of Amsterdam.