 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Planning in POMDPs with State-Requests
Jul 26, 2024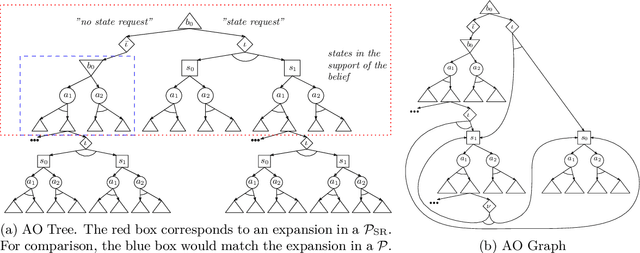
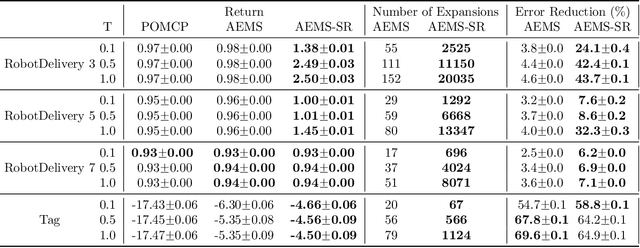
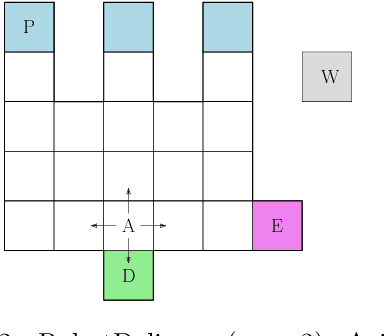
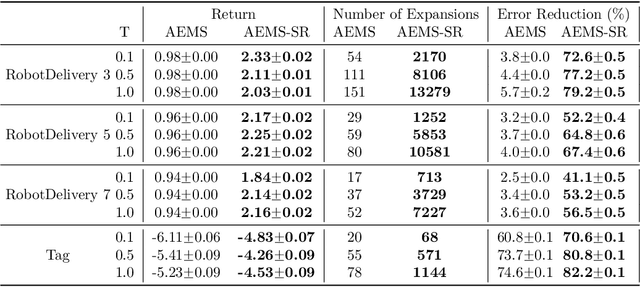
In key real-world problems, full state information is sometimes available but only at a high cost, like activating precise yet energy-intensive sensors or consulting humans, thereby compelling the agent to operate under partial observability. For this scenario, we propose AEMS-SR (Anytime Error Minimization Search with State Requests), a principled online planning algorithm tailored for POMDPs with state requests. By representing the search space as a graph instead of a tree, AEMS-SR avoids the exponential growth of the search space originating from state requests. Theoretical analysis demonstrates AEMS-SR's $\varepsilon$-optimality, ensuring solution quality, while empirical evaluations illustrate its effectiveness compared with AEMS and POMCP, two SOTA online planning algorithms. AEMS-SR enables efficient planning in domains characterized by partial observability and costly state requests offering practical benefits across various applications.
Pareto Conditioned Networks
Apr 11, 2022

In multi-objective optimization, learning all the policies that reach Pareto-efficient solutions is an expensive process. The set of optimal policies can grow exponentially with the number of objectives, and recovering all solutions requires an exhaustive exploration of the entire state space. We propose Pareto Conditioned Networks (PCN), a method that uses a single neural network to encompass all non-dominated policies. PCN associates every past transition with its episode's return. It trains the network such that, when conditioned on this same return, it should reenact said transition. In doing so we transform the optimization problem into a classification problem. We recover a concrete policy by conditioning the network on the desired Pareto-efficient solution. Our method is stable as it learns in a supervised fashion, thus avoiding moving target issues. Moreover, by using a single network, PCN scales efficiently with the number of objectives. Finally, it makes minimal assumptions on the shape of the Pareto front, which makes it suitable to a wider range of problems than previous state-of-the-art multi-objective reinforcement learning algorithms.
A Practical Guide to Multi-Objective Reinforcement Learning and Planning
Mar 17, 2021

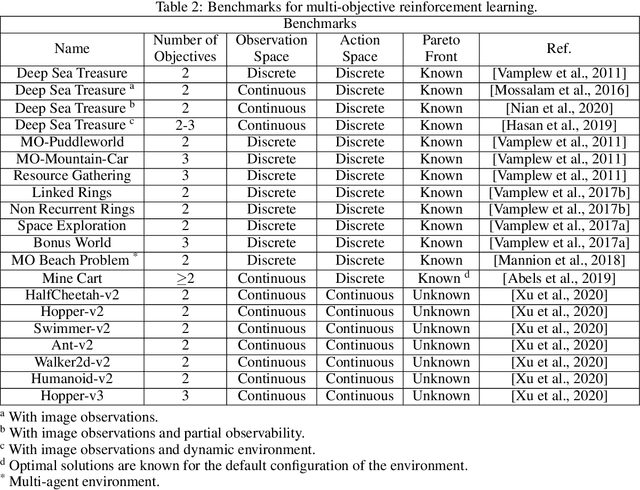
Real-world decision-making tasks are generally complex, requiring trade-offs between multiple, often conflicting, objectives. Despite this, the majority of research in reinforcement learning and decision-theoretic planning either assumes only a single objective, or that multiple objectives can be adequately handled via a simple linear combination. Such approaches may oversimplify the underlying problem and hence produce suboptimal results. This paper serves as a guide to the application of multi-objective methods to difficult problems, and is aimed at researchers who are already familiar with single-objective reinforcement learning and planning methods who wish to adopt a multi-objective perspective on their research, as well as practitioners who encounter multi-objective decision problems in practice. It identifies the factors that may influence the nature of the desired solution, and illustrates by example how these influence the design of multi-objective decision-making systems for complex problems.
Scalable Optimization for Wind Farm Control using Coordination Graphs
Jan 19, 2021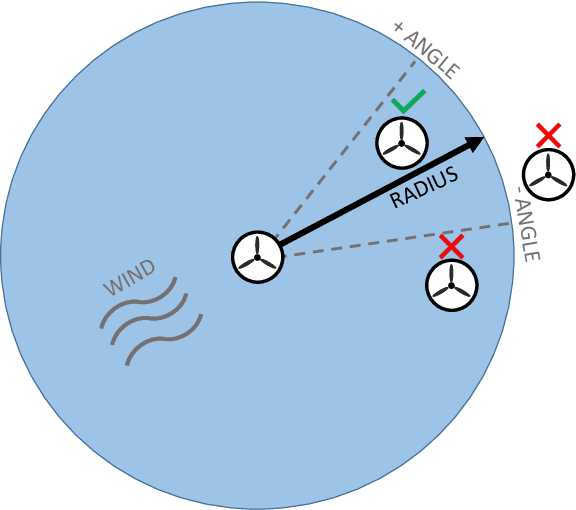
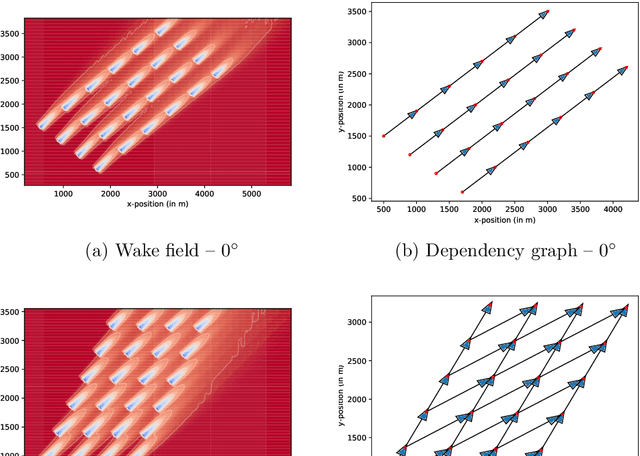
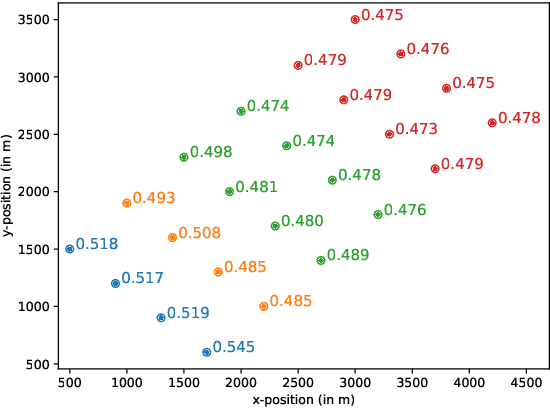
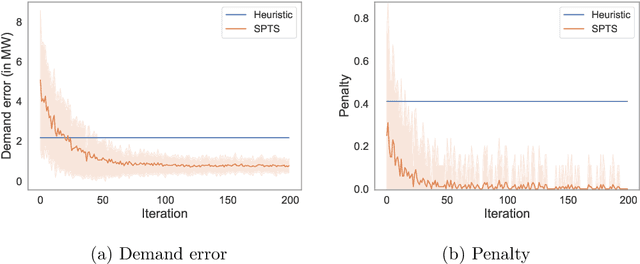
Wind farms are a crucial driver toward the generation of ecological and renewable energy. Due to their rapid increase in capacity, contemporary wind farms need to adhere to strict constraints on power output to ensure stability of the electricity grid. Specifically, a wind farm controller is required to match the farm's power production with a power demand imposed by the grid operator. This is a non-trivial optimization problem, as complex dependencies exist between the wind turbines. State-of-the-art wind farm control typically relies on physics-based heuristics that fail to capture the full load spectrum that defines a turbine's health status. When this is not taken into account, the long-term viability of the farm's turbines is put at risk. Given the complex dependencies that determine a turbine's lifetime, learning a flexible and optimal control strategy requires a data-driven approach. However, as wind farms are large-scale multi-agent systems, optimizing control strategies over the full joint action space is intractable. We propose a new learning method for wind farm control that leverages the sparse wind farm structure to factorize the optimization problem. Using a Bayesian approach, based on multi-agent Thompson sampling, we explore the factored joint action space for configurations that match the demand, while considering the lifetime of turbines. We apply our method to a grid-like wind farm layout, and evaluate configurations using a state-of-the-art wind flow simulator. Our results are competitive with a physics-based heuristic approach in terms of demand error, while, contrary to the heuristic, our method prolongs the lifetime of high-risk turbines.
Model-based Multi-Agent Reinforcement Learning with Cooperative Prioritized Sweeping
Jan 15, 2020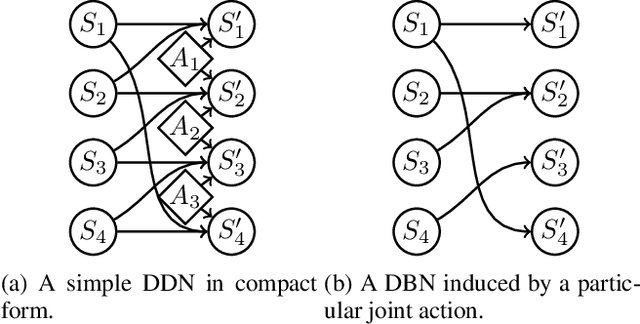
We present a new model-based reinforcement learning algorithm, Cooperative Prioritized Sweeping, for efficient learning in multi-agent Markov decision processes. The algorithm allows for sample-efficient learning on large problems by exploiting a factorization to approximate the value function. Our approach only requires knowledge about the structure of the problem in the form of a dynamic decision network. Using this information, our method learns a model of the environment and performs temporal difference updates which affect multiple joint states and actions at once. Batch updates are additionally performed which efficiently back-propagate knowledge throughout the factored Q-function. Our method outperforms the state-of-the-art algorithm sparse cooperative Q-learning algorithm, both on the well-known SysAdmin benchmark and randomized environments.
Thompson Sampling for Factored Multi-Agent Bandits
Nov 22, 2019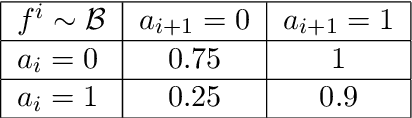
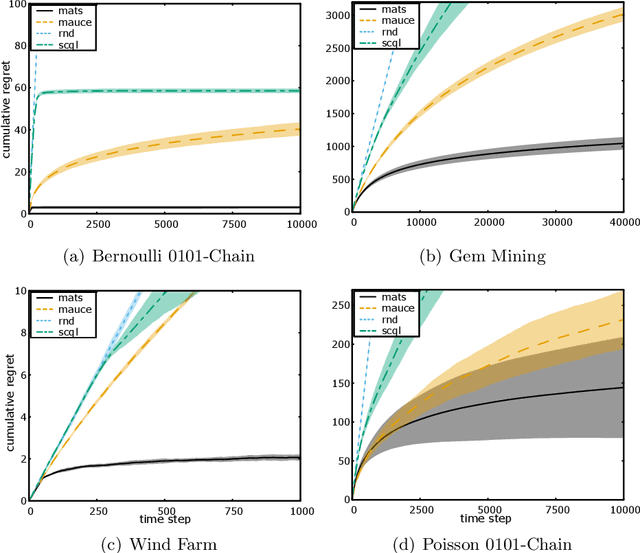
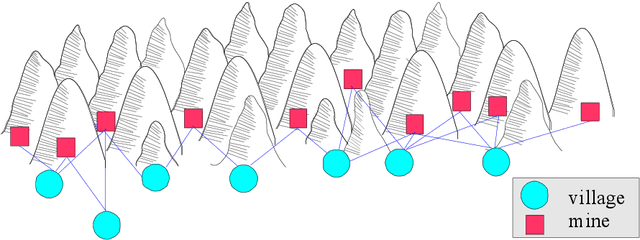
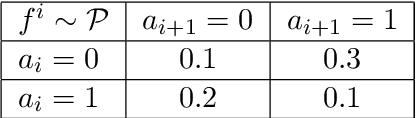
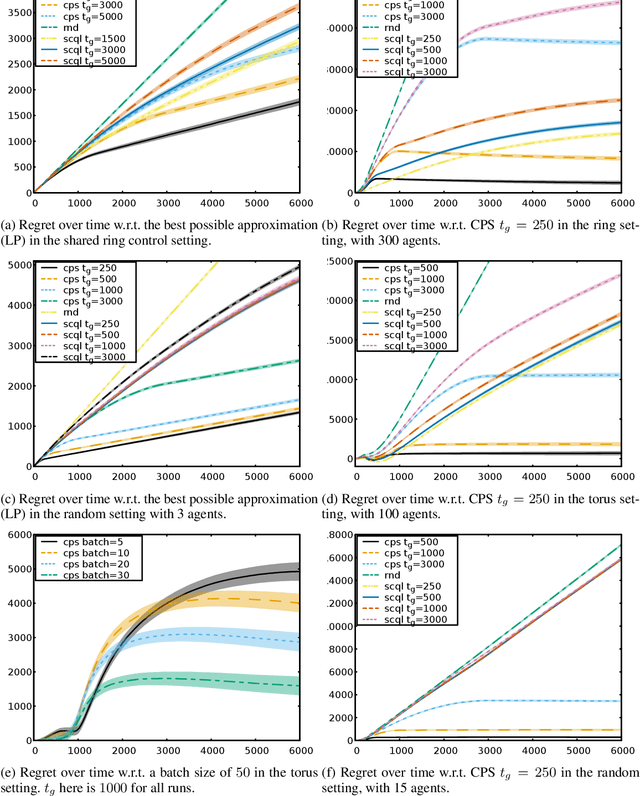
Multi-agent coordination is prevalent in many real-world applications. However, such coordination is challenging due to its combinatorial nature. An important observation in this regard is that agents in the real world often only directly affect a limited set of neighboring agents. Leveraging such loose couplings among agents is key to making coordination in multi-agent systems feasible. In this work, we focus on learning to coordinate. Specifically, we consider the multi-agent multi-armed bandit framework, in which fully cooperative loosely-coupled agents must learn to coordinate their decisions to optimize a common objective. As opposed to in the planning setting, for learning methods it is challenging to establish theoretical guarantees. We propose multi-agent Thompson sampling (MATS), a new Bayesian exploration-exploitation algorithm that leverages loose couplings. We provide a regret bound that is sublinear in time and low-order polynomial in the highest number of actions of a single agent for sparse coordination graphs. Finally, we empirically show that MATS outperforms the state-of-the-art algorithm, MAUCE, on two synthetic benchmarks, a realistic wind farm control task, and a novel benchmark with Poisson distributions.