 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating COVID-19 vaccine allocation policies using Bayesian $m$-top exploration
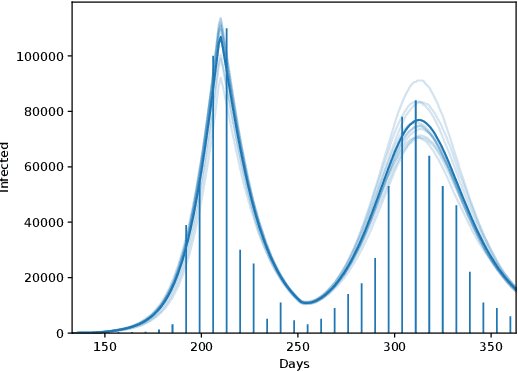
Jan 30, 2023Individual-based epidemiological models support the study of fine-grained preventive measures, such as tailored vaccine allocation policies, in silico. As individual-based models are computationally intensive, it is pivotal to identify optimal strategies within a reasonable computational budget. Moreover, due to the high societal impact associated with the implementation of preventive strategies, uncertainty regarding decisions should be communicated to policy makers, which is naturally embedded in a Bayesian approach. We present a novel technique for evaluating vaccine allocation strategies using a multi-armed bandit framework in combination with a Bayesian anytime $m$-top exploration algorithm. $m$-top exploration allows the algorithm to learn $m$ policies for which it expects the highest utility, enabling experts to inspect this small set of alternative strategies, along with their quantified uncertainty. The anytime component provides policy advisors with flexibility regarding the computation time and the desired confidence, which is important as it is difficult to make this trade-off beforehand. We consider the Belgian COVID-19 epidemic using the individual-based model STRIDE, where we learn a set of vaccination policies that minimize the number of infections and hospitalisations. Through experiments we show that our method can efficiently identify the $m$-top policies, which is validated in a scenario where the ground truth is available. Finally, we explore how vaccination policies can best be organised under different contact reduction schemes. Through these experiments, we show that the top policies follow a clear trend regarding the prioritised age groups and assigned vaccine type, which provides insights for future vaccination campaigns.
Multi-Objective Coordination Graphs for the Expected Scalarised Returns with Generative Flow Models
Jul 01, 2022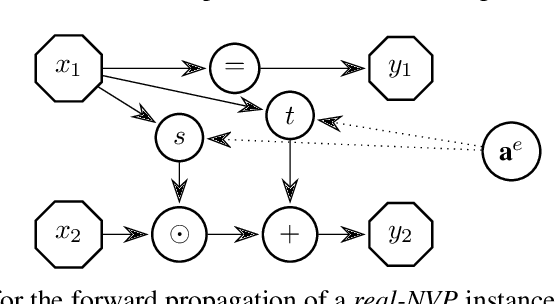

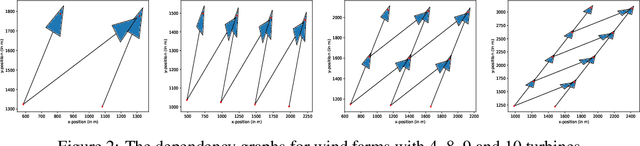

Many real-world problems contain multiple objectives and agents, where a trade-off exists between objectives. Key to solving such problems is to exploit sparse dependency structures that exist between agents. For example, in wind farm control a trade-off exists between maximising power and minimising stress on the systems components. Dependencies between turbines arise due to the wake effect. We model such sparse dependencies between agents as a multi-objective coordination graph (MO-CoG). In multi-objective reinforcement learning a utility function is typically used to model a users preferences over objectives, which may be unknown a priori. In such settings a set of optimal policies must be computed. Which policies are optimal depends on which optimality criterion applies. If the utility function of a user is derived from multiple executions of a policy, the scalarised expected returns (SER) must be optimised. If the utility of a user is derived from a single execution of a policy, the expected scalarised returns (ESR) criterion must be optimised. For example, wind farms are subjected to constraints and regulations that must be adhered to at all times, therefore the ESR criterion must be optimised. For MO-CoGs, the state-of-the-art algorithms can only compute a set of optimal policies for the SER criterion, leaving the ESR criterion understudied. To compute a set of optimal polices under the ESR criterion, also known as the ESR set, distributions over the returns must be maintained. Therefore, to compute a set of optimal policies under the ESR criterion for MO-CoGs, we present a novel distributional multi-objective variable elimination (DMOVE) algorithm. We evaluate DMOVE in realistic wind farm simulations. Given the returns in real-world wind farm settings are continuous, we utilise a model known as real-NVP to learn the continuous return distributions to calculate the ESR set.
Expected Scalarised Returns Dominance: A New Solution Concept for Multi-Objective Decision Making
Jun 02, 2021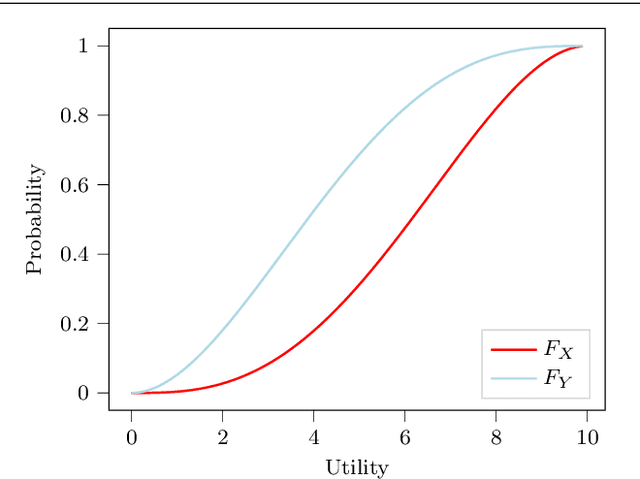

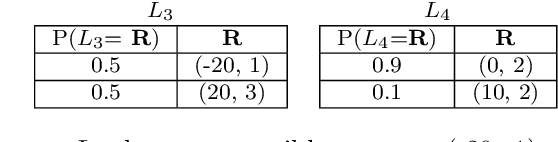
In many real-world scenarios, the utility of a user is derived from the single execution of a policy. In this case, to apply multi-objective reinforcement learning, the expected utility of the returns must be optimised. Various scenarios exist where a user's preferences over objectives (also known as the utility function) are unknown or difficult to specify. In such scenarios, a set of optimal policies must be learned. However, settings where the expected utility must be maximised have been largely overlooked by the multi-objective reinforcement learning community and, as a consequence, a set of optimal solutions has yet to be defined. In this paper we address this challenge by proposing first-order stochastic dominance as a criterion to build solution sets to maximise expected utility. We also propose a new dominance criterion, known as expected scalarised returns (ESR) dominance, that extends first-order stochastic dominance to allow a set of optimal policies to be learned in practice. We then define a new solution concept called the ESR set, which is a set of policies that are ESR dominant. Finally, we define a new multi-objective distributional tabular reinforcement learning (MOT-DRL) algorithm to learn the ESR set in a multi-objective multi-armed bandit setting.
A Practical Guide to Multi-Objective Reinforcement Learning and Planning
Mar 17, 2021

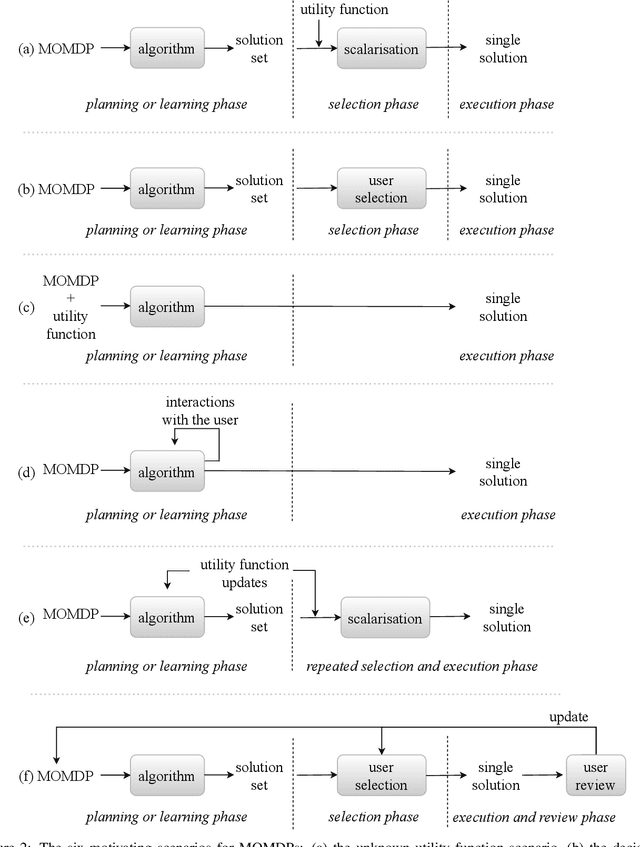
Real-world decision-making tasks are generally complex, requiring trade-offs between multiple, often conflicting, objectives. Despite this, the majority of research in reinforcement learning and decision-theoretic planning either assumes only a single objective, or that multiple objectives can be adequately handled via a simple linear combination. Such approaches may oversimplify the underlying problem and hence produce suboptimal results. This paper serves as a guide to the application of multi-objective methods to difficult problems, and is aimed at researchers who are already familiar with single-objective reinforcement learning and planning methods who wish to adopt a multi-objective perspective on their research, as well as practitioners who encounter multi-objective decision problems in practice. It identifies the factors that may influence the nature of the desired solution, and illustrates by example how these influence the design of multi-objective decision-making systems for complex problems.
Scalable Optimization for Wind Farm Control using Coordination Graphs
Jan 19, 2021
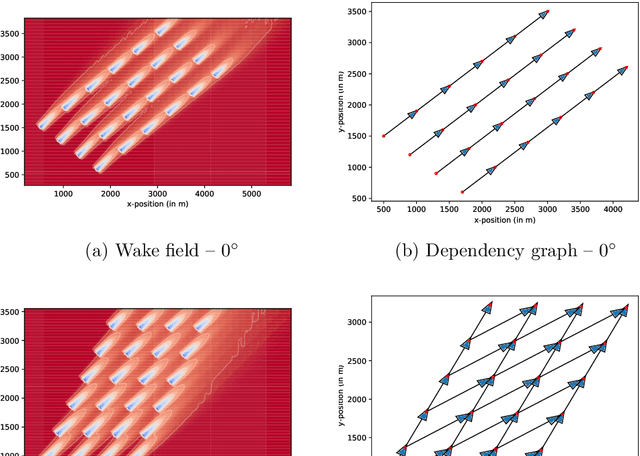
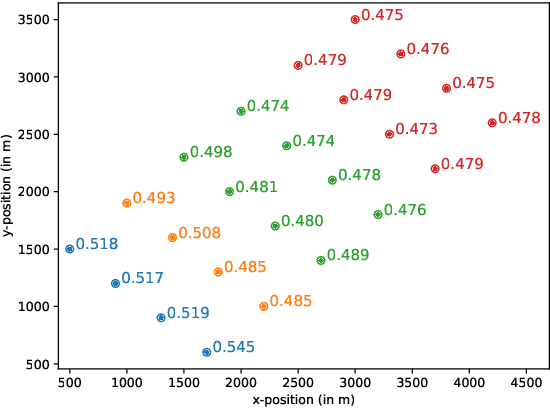
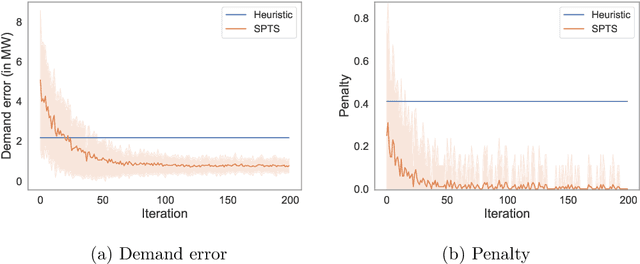
Wind farms are a crucial driver toward the generation of ecological and renewable energy. Due to their rapid increase in capacity, contemporary wind farms need to adhere to strict constraints on power output to ensure stability of the electricity grid. Specifically, a wind farm controller is required to match the farm's power production with a power demand imposed by the grid operator. This is a non-trivial optimization problem, as complex dependencies exist between the wind turbines. State-of-the-art wind farm control typically relies on physics-based heuristics that fail to capture the full load spectrum that defines a turbine's health status. When this is not taken into account, the long-term viability of the farm's turbines is put at risk. Given the complex dependencies that determine a turbine's lifetime, learning a flexible and optimal control strategy requires a data-driven approach. However, as wind farms are large-scale multi-agent systems, optimizing control strategies over the full joint action space is intractable. We propose a new learning method for wind farm control that leverages the sparse wind farm structure to factorize the optimization problem. Using a Bayesian approach, based on multi-agent Thompson sampling, we explore the factored joint action space for configurations that match the demand, while considering the lifetime of turbines. We apply our method to a grid-like wind farm layout, and evaluate configurations using a state-of-the-art wind flow simulator. Our results are competitive with a physics-based heuristic approach in terms of demand error, while, contrary to the heuristic, our method prolongs the lifetime of high-risk turbines.
Opponent Learning Awareness and Modelling in Multi-Objective Normal Form Games
Nov 14, 2020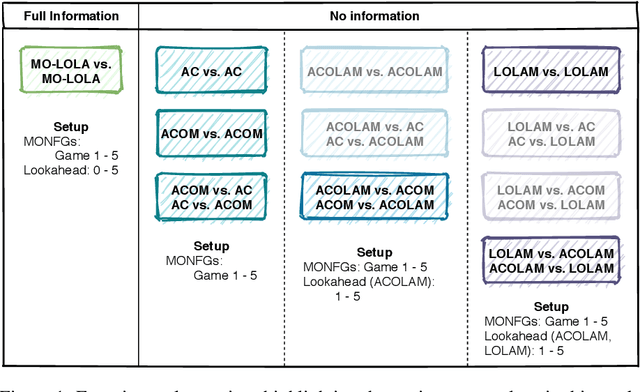
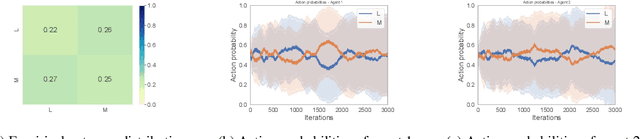
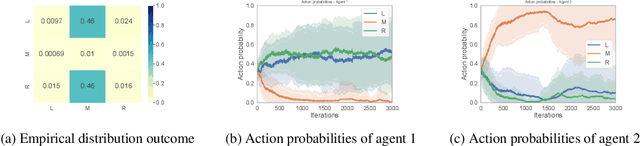
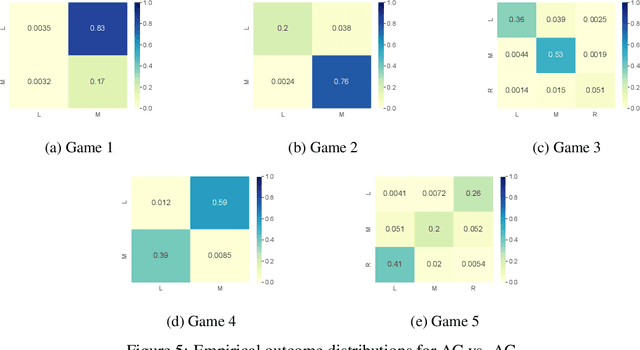
Many real-world multi-agent interactions consider multiple distinct criteria, i.e. the payoffs are multi-objective in nature. However, the same multi-objective payoff vector may lead to different utilities for each participant. Therefore, it is essential for an agent to learn about the behaviour of other agents in the system. In this work, we present the first study of the effects of such opponent modelling on multi-objective multi-agent interactions with non-linear utilities. Specifically, we consider two-player multi-objective normal form games with non-linear utility functions under the scalarised expected returns optimisation criterion. We contribute novel actor-critic and policy gradient formulations to allow reinforcement learning of mixed strategies in this setting, along with extensions that incorporate opponent policy reconstruction and learning with opponent learning awareness (i.e., learning while considering the impact of one's policy when anticipating the opponent's learning step). Empirical results in five different MONFGs demonstrate that opponent learning awareness and modelling can drastically alter the learning dynamics in this setting. When equilibria are present, opponent modelling can confer significant benefits on agents that implement it. When there are no Nash equilibria, opponent learning awareness and modelling allows agents to still converge to meaningful solutions that approximate equilibria.
Deep reinforcement learning for large-scale epidemic control
Mar 30, 2020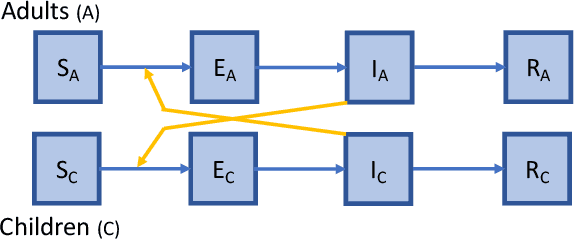

Epidemics of infectious diseases are an important threat to public health and global economies. Yet, the development of prevention strategies remains a challenging process, as epidemics are non-linear and complex processes. For this reason, we investigate a deep reinforcement learning approach to automatically learn prevention strategies in the context of pandemic influenza. Firstly, we construct a new epidemiological meta-population model, with 379 patches (one for each administrative district in Great Britain), that adequately captures the infection process of pandemic influenza. Our model balances complexity and computational efficiency such that the use of reinforcement learning techniques becomes attainable. Secondly, we set up a ground truth such that we can evaluate the performance of the 'Proximal Policy Optimization' algorithm to learn in a single district of this epidemiological model. Finally, we consider a large-scale problem, by conducting an experiment where we aim to learn a joint policy to control the districts in a community of 11 tightly coupled districts, for which no ground truth can be established. This experiment shows that deep reinforcement learning can be used to learn mitigation policies in complex epidemiological models with a large state space. Moreover, through this experiment, we demonstrate that there can be an advantage to consider collaboration between districts when designing prevention strategies.
Model-based Multi-Agent Reinforcement Learning with Cooperative Prioritized Sweeping
Jan 15, 2020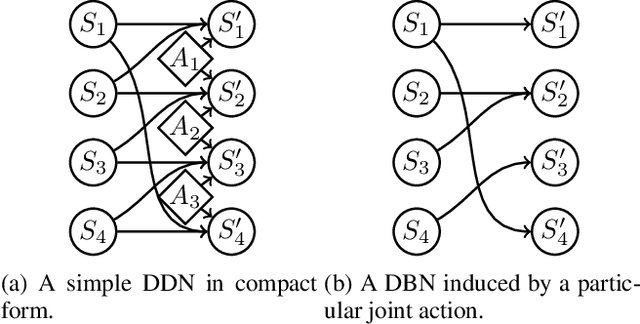
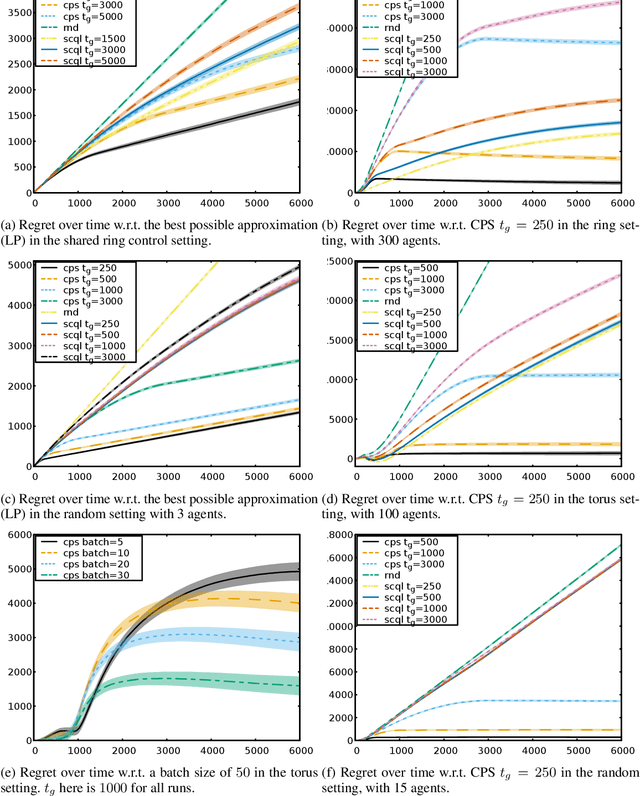
We present a new model-based reinforcement learning algorithm, Cooperative Prioritized Sweeping, for efficient learning in multi-agent Markov decision processes. The algorithm allows for sample-efficient learning on large problems by exploiting a factorization to approximate the value function. Our approach only requires knowledge about the structure of the problem in the form of a dynamic decision network. Using this information, our method learns a model of the environment and performs temporal difference updates which affect multiple joint states and actions at once. Batch updates are additionally performed which efficiently back-propagate knowledge throughout the factored Q-function. Our method outperforms the state-of-the-art algorithm sparse cooperative Q-learning algorithm, both on the well-known SysAdmin benchmark and randomized environments.
Fleet Control using Coregionalized Gaussian Process Policy Iteration
Nov 22, 2019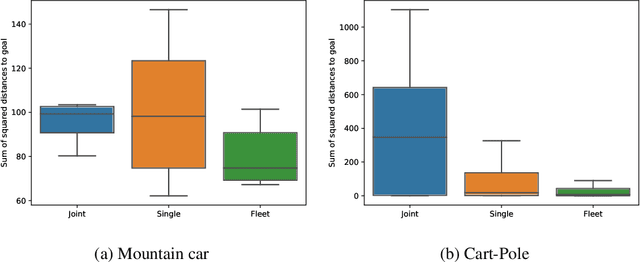
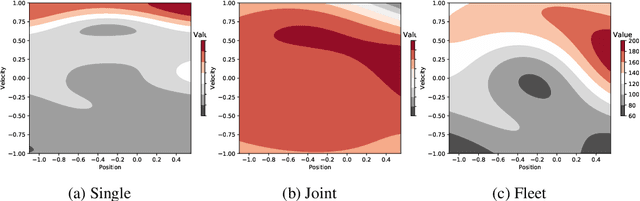
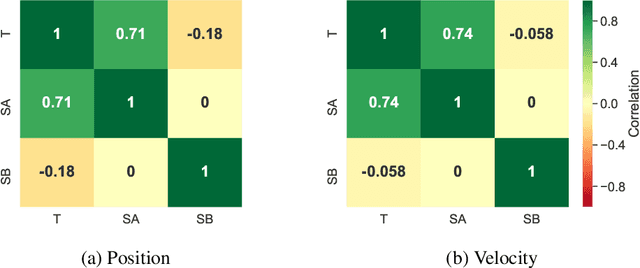
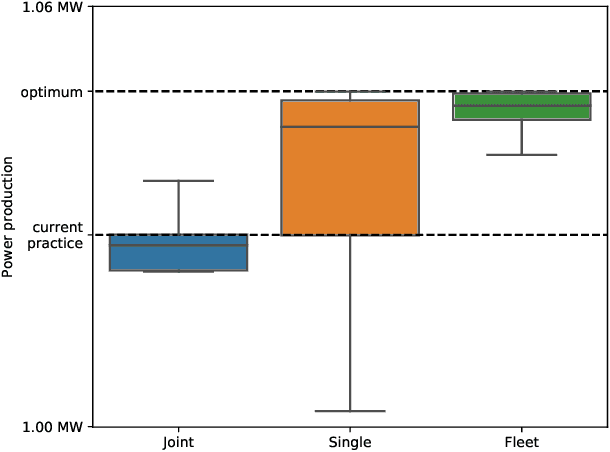
In many settings, as for example wind farms, multiple machines are instantiated to perform the same task, which is called a fleet. The recent advances with respect to the Internet of Things allow control devices and/or machines to connect through cloud-based architectures in order to share information about their status and environment. Such an infrastructure allows seamless data sharing between fleet members, which could greatly improve the sample-efficiency of reinforcement learning techniques. However in practice, these machines, while almost identical in design, have small discrepancies due to production errors or degradation, preventing control algorithms to simply aggregate and employ all fleet data. We propose a novel reinforcement learning method that learns to transfer knowledge between similar fleet members and creates member-specific dynamics models for control. Our algorithm uses Gaussian processes to establish cross-member covariances. This is significantly different from standard transfer learning methods, as the focus is not on sharing information over tasks, but rather over system specifications. We demonstrate our approach on two benchmarks and a realistic wind farm setting. Our method significantly outperforms two baseline approaches, namely individual learning and joint learning where all samples are aggregated, in terms of the median and variance of the results.
Thompson Sampling for Factored Multi-Agent Bandits
Nov 22, 2019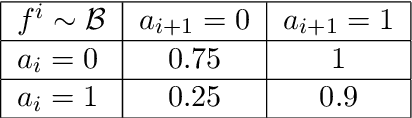
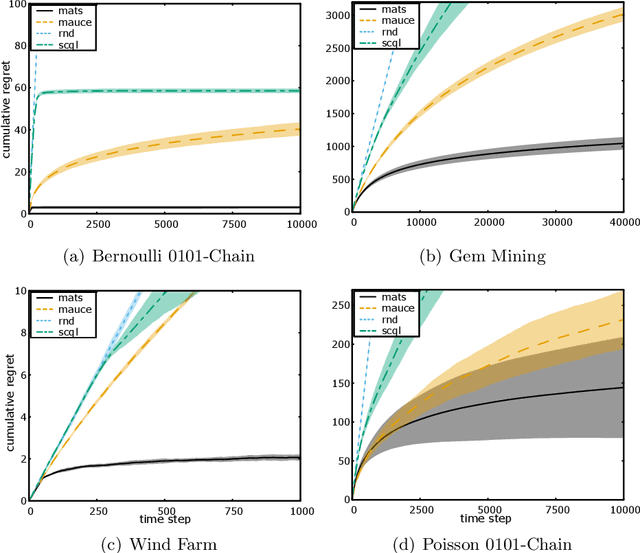
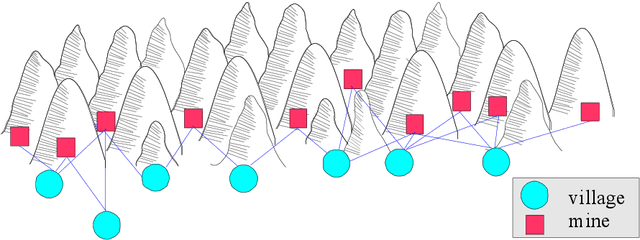
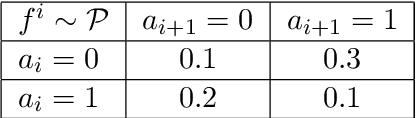
Multi-agent coordination is prevalent in many real-world applications. However, such coordination is challenging due to its combinatorial nature. An important observation in this regard is that agents in the real world often only directly affect a limited set of neighboring agents. Leveraging such loose couplings among agents is key to making coordination in multi-agent systems feasible. In this work, we focus on learning to coordinate. Specifically, we consider the multi-agent multi-armed bandit framework, in which fully cooperative loosely-coupled agents must learn to coordinate their decisions to optimize a common objective. As opposed to in the planning setting, for learning methods it is challenging to establish theoretical guarantees. We propose multi-agent Thompson sampling (MATS), a new Bayesian exploration-exploitation algorithm that leverages loose couplings. We provide a regret bound that is sublinear in time and low-order polynomial in the highest number of actions of a single agent for sparse coordination graphs. Finally, we empirically show that MATS outperforms the state-of-the-art algorithm, MAUCE, on two synthetic benchmarks, a realistic wind farm control task, and a novel benchmark with Poisson distributions.