 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNASimJax: GPU-Accelerated Policy Learning Framework for Penetration Testing
Mar 20, 2026Penetration testing, the practice of simulating cyberattacks to identify vulnerabilities, is a complex sequential decision-making task that is inherently partially observable and features large action spaces. Training reinforcement learning (RL) policies for this domain faces a fundamental bottleneck: existing simulators are too slow to train on realistic network scenarios at scale, resulting in policies that fail to generalize. We present NASimJax, a complete JAX-based reimplementation of the Network Attack Simulator (NASim), achieving up to 100x higher environment throughput than the original simulator. By running the entire training pipeline on hardware accelerators, NASimJax enables experimentation on larger networks under fixed compute budgets that were previously infeasible. We formulate automated penetration testing as a Contextual POMDP and introduce a network generation pipeline that produces structurally diverse and guaranteed-solvable scenarios. Together, these provide a principled basis for studying zero-shot policy generalization. We use the framework to investigate action-space scaling and generalization across networks of up to 40 hosts. We find that Prioritized Level Replay better handles dense training distributions than Domain Randomization, particularly at larger scales, and that training on sparser topologies yields an implicit curriculum that improves out-of-distribution generalization, even on topologies denser than those seen during training. To handle linearly growing action spaces, we propose a two-stage action decomposition (2SAS) that substantially outperforms flat action masking at scale. Finally, we identify a failure mode arising from the interaction between Prioritized Level Replay's episode-reset behaviour and 2SAS's credit assignment structure. NASimJax thus provides a fast, flexible, and realistic platform for advancing RL-based penetration testing.
Fairness-Aware Reinforcement Learning (FAReL): A Framework for Transparent and Balanced Sequential Decision-Making
Sep 26, 2025Equity in real-world sequential decision problems can be enforced using fairness-aware methods. Therefore, we require algorithms that can make suitable and transparent trade-offs between performance and the desired fairness notions. As the desired performance-fairness trade-off is hard to specify a priori, we propose a framework where multiple trade-offs can be explored. Insights provided by the reinforcement learning algorithm regarding the obtainable performance-fairness trade-offs can then guide stakeholders in selecting the most appropriate policy. To capture fairness, we propose an extended Markov decision process, $f$MDP, that explicitly encodes individuals and groups. Given this $f$MDP, we formalise fairness notions in the context of sequential decision problems and formulate a fairness framework that computes fairness measures over time. We evaluate our framework in two scenarios with distinct fairness requirements: job hiring, where strong teams must be composed while treating applicants equally, and fraud detection, where fraudulent transactions must be detected while ensuring the burden on customers is fairly distributed. We show that our framework learns policies that are more fair across multiple scenarios, with only minor loss in performance reward. Moreover, we observe that group and individual fairness notions do not necessarily imply one another, highlighting the benefit of our framework in settings where both fairness types are desired. Finally, we provide guidelines on how to apply this framework across different problem settings.
Evaluating COVID-19 vaccine allocation policies using Bayesian $m$-top exploration
Jan 30, 2023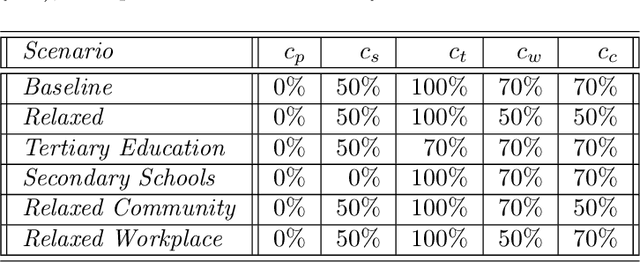
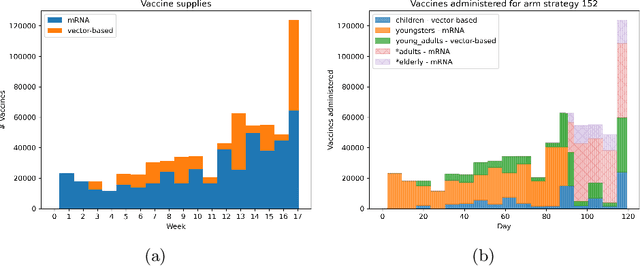
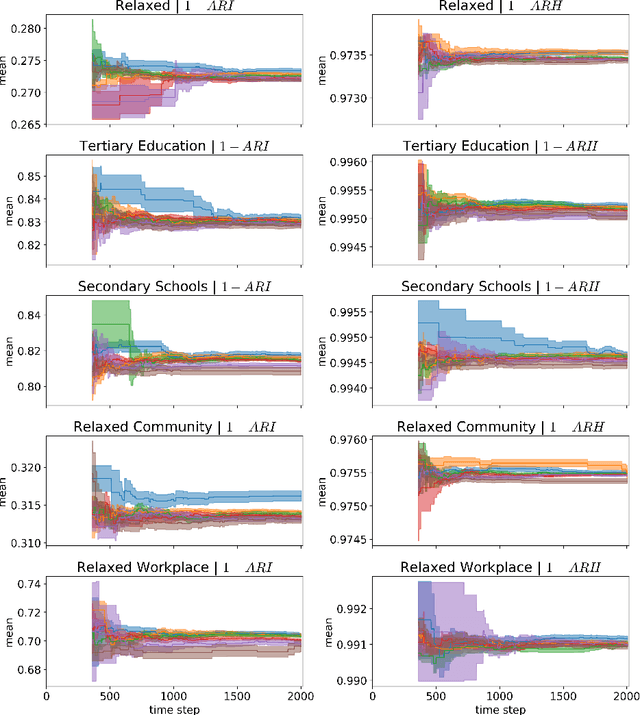
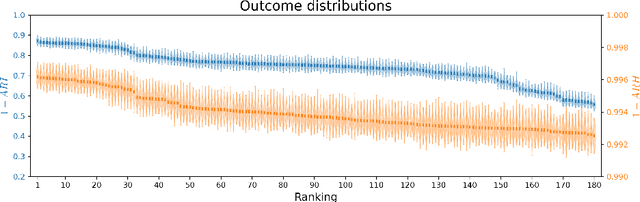
Individual-based epidemiological models support the study of fine-grained preventive measures, such as tailored vaccine allocation policies, in silico. As individual-based models are computationally intensive, it is pivotal to identify optimal strategies within a reasonable computational budget. Moreover, due to the high societal impact associated with the implementation of preventive strategies, uncertainty regarding decisions should be communicated to policy makers, which is naturally embedded in a Bayesian approach. We present a novel technique for evaluating vaccine allocation strategies using a multi-armed bandit framework in combination with a Bayesian anytime $m$-top exploration algorithm. $m$-top exploration allows the algorithm to learn $m$ policies for which it expects the highest utility, enabling experts to inspect this small set of alternative strategies, along with their quantified uncertainty. The anytime component provides policy advisors with flexibility regarding the computation time and the desired confidence, which is important as it is difficult to make this trade-off beforehand. We consider the Belgian COVID-19 epidemic using the individual-based model STRIDE, where we learn a set of vaccination policies that minimize the number of infections and hospitalisations. Through experiments we show that our method can efficiently identify the $m$-top policies, which is validated in a scenario where the ground truth is available. Finally, we explore how vaccination policies can best be organised under different contact reduction schemes. Through these experiments, we show that the top policies follow a clear trend regarding the prioritised age groups and assigned vaccine type, which provides insights for future vaccination campaigns.
Exploring the Pareto front of multi-objective COVID-19 mitigation policies using reinforcement learning
Apr 11, 2022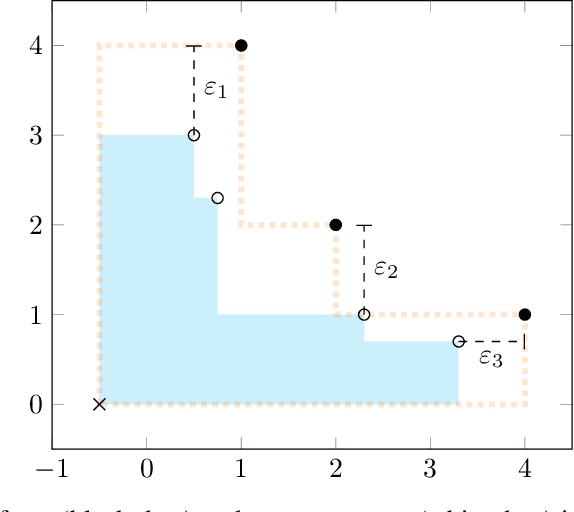

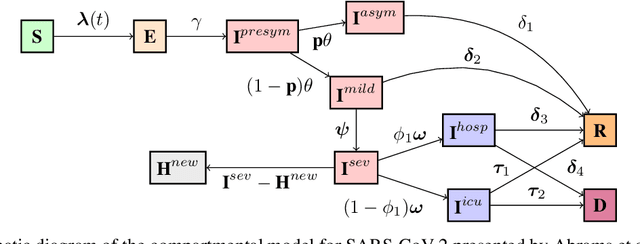
Infectious disease outbreaks can have a disruptive impact on public health and societal processes. As decision making in the context of epidemic mitigation is hard, reinforcement learning provides a methodology to automatically learn prevention strategies in combination with complex epidemic models. Current research focuses on optimizing policies w.r.t. a single objective, such as the pathogen's attack rate. However, as the mitigation of epidemics involves distinct, and possibly conflicting criteria (i.a., prevalence, mortality, morbidity, cost), a multi-objective approach is warranted to learn balanced policies. To lift this decision-making process to real-world epidemic models, we apply deep multi-objective reinforcement learning and build upon a state-of-the-art algorithm, Pareto Conditioned Networks (PCN), to learn a set of solutions that approximates the Pareto front of the decision problem. We consider the first wave of the Belgian COVID-19 epidemic, which was mitigated by a lockdown, and study different deconfinement strategies, aiming to minimize both COVID-19 cases (i.e., infections and hospitalizations) and the societal burden that is induced by the applied mitigation measures. We contribute a multi-objective Markov decision process that encapsulates the stochastic compartment model that was used to inform policy makers during the COVID-19 epidemic. As these social mitigation measures are implemented in a continuous action space that modulates the contact matrix of the age-structured epidemic model, we extend PCN to this setting. We evaluate the solution returned by PCN, and observe that it correctly learns to reduce the social burden whenever the hospitalization rates are sufficiently low. In this work, we thus show that multi-objective reinforcement learning is attainable in complex epidemiological models and provides essential insights to balance complex mitigation policies.
Deep reinforcement learning for large-scale epidemic control
Mar 30, 2020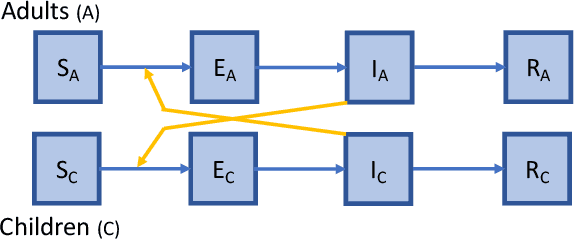
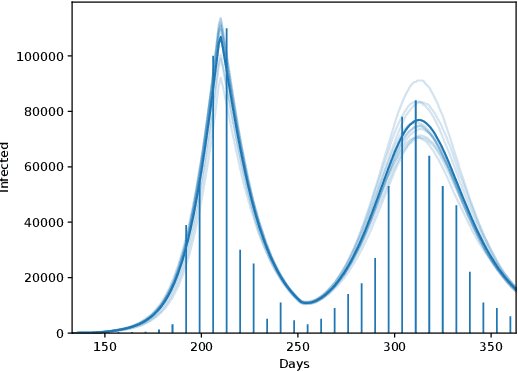

Epidemics of infectious diseases are an important threat to public health and global economies. Yet, the development of prevention strategies remains a challenging process, as epidemics are non-linear and complex processes. For this reason, we investigate a deep reinforcement learning approach to automatically learn prevention strategies in the context of pandemic influenza. Firstly, we construct a new epidemiological meta-population model, with 379 patches (one for each administrative district in Great Britain), that adequately captures the infection process of pandemic influenza. Our model balances complexity and computational efficiency such that the use of reinforcement learning techniques becomes attainable. Secondly, we set up a ground truth such that we can evaluate the performance of the 'Proximal Policy Optimization' algorithm to learn in a single district of this epidemiological model. Finally, we consider a large-scale problem, by conducting an experiment where we aim to learn a joint policy to control the districts in a community of 11 tightly coupled districts, for which no ground truth can be established. This experiment shows that deep reinforcement learning can be used to learn mitigation policies in complex epidemiological models with a large state space. Moreover, through this experiment, we demonstrate that there can be an advantage to consider collaboration between districts when designing prevention strategies.
IPC-Net: 3D point-cloud segmentation using deep inter-point convolutional layers
Sep 30, 2019



Over the last decade, the demand for better segmentation and classification algorithms in 3D spaces has significantly grown due to the popularity of new 3D sensor technologies and advancements in the field of robotics. Point-clouds are one of the most popular representations to store a digital description of 3D shapes. However, point-clouds are stored in irregular and unordered structures, which limits the direct use of segmentation algorithms such as Convolutional Neural Networks. The objective of our work is twofold: First, we aim to provide a full analysis of the PointNet architecture to illustrate which features are being extracted from the point-clouds. Second, to propose a new network architecture called IPC-Net to improve the state-of-the-art point cloud architectures. We show that IPC-Net extracts a larger set of unique features allowing the model to produce more accurate segmentations compared to the PointNet architecture. In general, our approach outperforms PointNet on every family of 3D geometries on which the models were tested. A high generalisation improvement was observed on every 3D shape, especially on the rockets dataset. Our experiments demonstrate that our main contribution, inter-point activation on the network's layers, is essential to accurately segment 3D point-clouds.
Bayesian Best-Arm Identification for Selecting Influenza Mitigation Strategies
Jun 15, 2018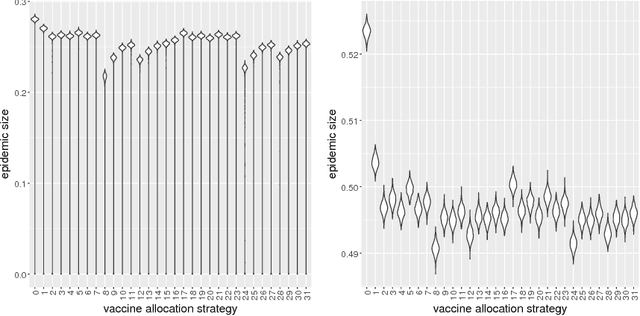
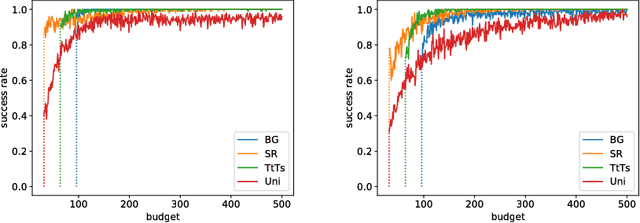
Pandemic influenza has the epidemic potential to kill millions of people. While various preventive measures exist (i.a., vaccination and school closures), deciding on strategies that lead to their most effective and efficient use remains challenging. To this end, individual-based epidemiological models are essential to assist decision makers in determining the best strategy to curb epidemic spread. However, individual-based models are computationally intensive and it is therefore pivotal to identify the optimal strategy using a minimal amount of model evaluations. Additionally, as epidemiological modeling experiments need to be planned, a computational budget needs to be specified a priori. Consequently, we present a new sampling technique to optimize the evaluation of preventive strategies using fixed budget best-arm identification algorithms. We use epidemiological modeling theory to derive knowledge about the reward distribution which we exploit using Bayesian best-arm identification algorithms (i.e., Top-two Thompson sampling and BayesGap). We evaluate these algorithms in a realistic experimental setting and demonstrate that it is possible to identify the optimal strategy using only a limited number of model evaluations, i.e., 2-to-3 times faster compared to the uniform sampling method, the predominant technique used for epidemiological decision making in the literature. Finally, we contribute and evaluate a statistic for Top-two Thompson sampling to inform the decision makers about the confidence of an arm recommendation.