 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving a Million-Step LLM Task with Zero Errors
Nov 12, 2025LLMs have achieved remarkable breakthroughs in reasoning, insights, and tool use, but chaining these abilities into extended processes at the scale of those routinely executed by humans, organizations, and societies has remained out of reach. The models have a persistent error rate that prevents scale-up: for instance, recent experiments in the Towers of Hanoi benchmark domain showed that the process inevitably becomes derailed after at most a few hundred steps. Thus, although LLM research is often still benchmarked on tasks with relatively few dependent logical steps, there is increasing attention on the ability (or inability) of LLMs to perform long range tasks. This paper describes MAKER, the first system that successfully solves a task with over one million LLM steps with zero errors, and, in principle, scales far beyond this level. The approach relies on an extreme decomposition of a task into subtasks, each of which can be tackled by focused microagents. The high level of modularity resulting from the decomposition allows error correction to be applied at each step through an efficient multi-agent voting scheme. This combination of extreme decomposition and error correction makes scaling possible. Thus, the results suggest that instead of relying on continual improvement of current LLMs, massively decomposed agentic processes (MDAPs) may provide a way to efficiently solve problems at the level of organizations and societies.
Deep Symbolic Optimization: Reinforcement Learning for Symbolic Mathematics
May 16, 2025Deep Symbolic Optimization (DSO) is a novel computational framework that enables symbolic optimization for scientific discovery, particularly in applications involving the search for intricate symbolic structures. One notable example is equation discovery, which aims to automatically derive mathematical models expressed in symbolic form. In DSO, the discovery process is formulated as a sequential decision-making task. A generative neural network learns a probabilistic model over a vast space of candidate symbolic expressions, while reinforcement learning strategies guide the search toward the most promising regions. This approach integrates gradient-based optimization with evolutionary and local search techniques, and it incorporates in-situ constraints, domain-specific priors, and advanced policy optimization methods. The result is a robust framework capable of efficiently exploring extensive search spaces to identify interpretable and physically meaningful models. Extensive evaluations on benchmark problems have demonstrated that DSO achieves state-of-the-art performance in both accuracy and interpretability. In this chapter, we provide a comprehensive overview of the DSO framework and illustrate its transformative potential for automating symbolic optimization in scientific discovery.
Utility-Based Reinforcement Learning: Unifying Single-objective and Multi-objective Reinforcement Learning
Feb 05, 2024Research in multi-objective reinforcement learning (MORL) has introduced the utility-based paradigm, which makes use of both environmental rewards and a function that defines the utility derived by the user from those rewards. In this paper we extend this paradigm to the context of single-objective reinforcement learning (RL), and outline multiple potential benefits including the ability to perform multi-policy learning across tasks relating to uncertain objectives, risk-aware RL, discounting, and safe RL. We also examine the algorithmic implications of adopting a utility-based approach.
Distributional Multi-Objective Decision Making
May 19, 2023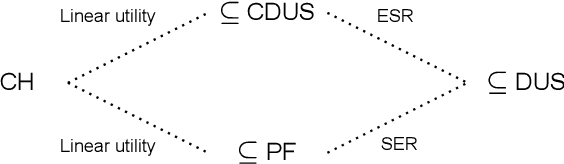

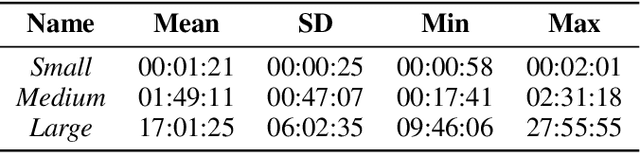
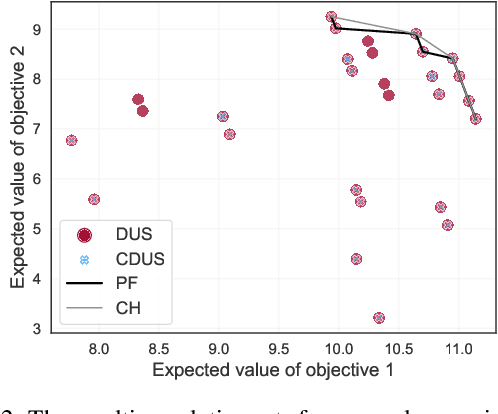
For effective decision support in scenarios with conflicting objectives, sets of potentially optimal solutions can be presented to the decision maker. We explore both what policies these sets should contain and how such sets can be computed efficiently. With this in mind, we take a distributional approach and introduce a novel dominance criterion relating return distributions of policies directly. Based on this criterion, we present the distributional undominated set and show that it contains optimal policies otherwise ignored by the Pareto front. In addition, we propose the convex distributional undominated set and prove that it comprises all policies that maximise expected utility for multivariate risk-averse decision makers. We propose a novel algorithm to learn the distributional undominated set and further contribute pruning operators to reduce the set to the convex distributional undominated set. Through experiments, we demonstrate the feasibility and effectiveness of these methods, making this a valuable new approach for decision support in real-world problems.
Monte Carlo Tree Search Algorithms for Risk-Aware and Multi-Objective Reinforcement Learning
Dec 06, 2022In many risk-aware and multi-objective reinforcement learning settings, the utility of the user is derived from a single execution of a policy. In these settings, making decisions based on the average future returns is not suitable. For example, in a medical setting a patient may only have one opportunity to treat their illness. Making decisions using just the expected future returns -- known in reinforcement learning as the value -- cannot account for the potential range of adverse or positive outcomes a decision may have. Therefore, we should use the distribution over expected future returns differently to represent the critical information that the agent requires at decision time by taking both the future and accrued returns into consideration. In this paper, we propose two novel Monte Carlo tree search algorithms. Firstly, we present a Monte Carlo tree search algorithm that can compute policies for nonlinear utility functions (NLU-MCTS) by optimising the utility of the different possible returns attainable from individual policy executions, resulting in good policies for both risk-aware and multi-objective settings. Secondly, we propose a distributional Monte Carlo tree search algorithm (DMCTS) which extends NLU-MCTS. DMCTS computes an approximate posterior distribution over the utility of the returns, and utilises Thompson sampling during planning to compute policies in risk-aware and multi-objective settings. Both algorithms outperform the state-of-the-art in multi-objective reinforcement learning for the expected utility of the returns.
Multi-Objective Coordination Graphs for the Expected Scalarised Returns with Generative Flow Models
Jul 01, 2022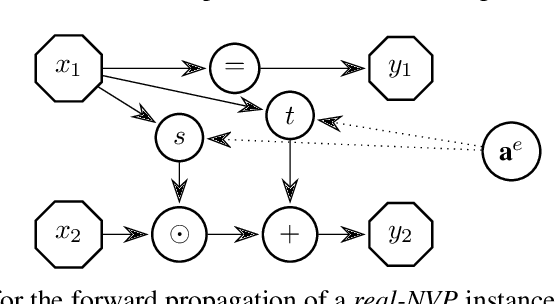

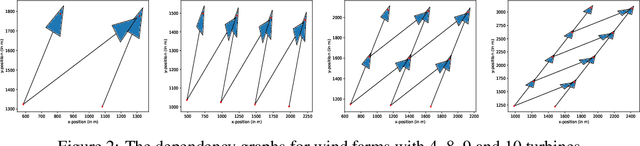

Many real-world problems contain multiple objectives and agents, where a trade-off exists between objectives. Key to solving such problems is to exploit sparse dependency structures that exist between agents. For example, in wind farm control a trade-off exists between maximising power and minimising stress on the systems components. Dependencies between turbines arise due to the wake effect. We model such sparse dependencies between agents as a multi-objective coordination graph (MO-CoG). In multi-objective reinforcement learning a utility function is typically used to model a users preferences over objectives, which may be unknown a priori. In such settings a set of optimal policies must be computed. Which policies are optimal depends on which optimality criterion applies. If the utility function of a user is derived from multiple executions of a policy, the scalarised expected returns (SER) must be optimised. If the utility of a user is derived from a single execution of a policy, the expected scalarised returns (ESR) criterion must be optimised. For example, wind farms are subjected to constraints and regulations that must be adhered to at all times, therefore the ESR criterion must be optimised. For MO-CoGs, the state-of-the-art algorithms can only compute a set of optimal policies for the SER criterion, leaving the ESR criterion understudied. To compute a set of optimal polices under the ESR criterion, also known as the ESR set, distributions over the returns must be maintained. Therefore, to compute a set of optimal policies under the ESR criterion for MO-CoGs, we present a novel distributional multi-objective variable elimination (DMOVE) algorithm. We evaluate DMOVE in realistic wind farm simulations. Given the returns in real-world wind farm settings are continuous, we utilise a model known as real-NVP to learn the continuous return distributions to calculate the ESR set.
Exploring the Pareto front of multi-objective COVID-19 mitigation policies using reinforcement learning
Apr 11, 2022

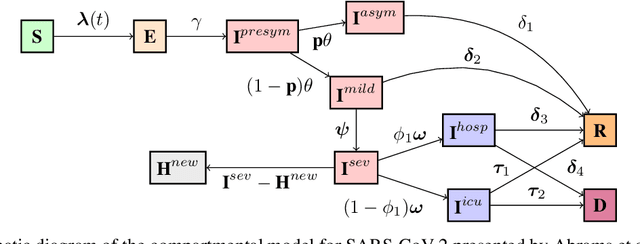
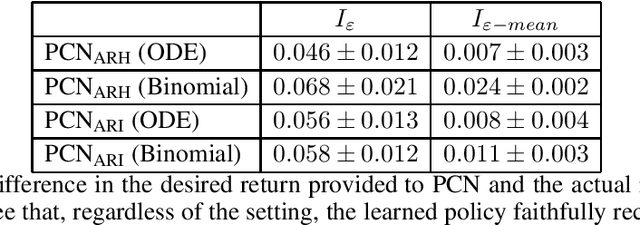
Infectious disease outbreaks can have a disruptive impact on public health and societal processes. As decision making in the context of epidemic mitigation is hard, reinforcement learning provides a methodology to automatically learn prevention strategies in combination with complex epidemic models. Current research focuses on optimizing policies w.r.t. a single objective, such as the pathogen's attack rate. However, as the mitigation of epidemics involves distinct, and possibly conflicting criteria (i.a., prevalence, mortality, morbidity, cost), a multi-objective approach is warranted to learn balanced policies. To lift this decision-making process to real-world epidemic models, we apply deep multi-objective reinforcement learning and build upon a state-of-the-art algorithm, Pareto Conditioned Networks (PCN), to learn a set of solutions that approximates the Pareto front of the decision problem. We consider the first wave of the Belgian COVID-19 epidemic, which was mitigated by a lockdown, and study different deconfinement strategies, aiming to minimize both COVID-19 cases (i.e., infections and hospitalizations) and the societal burden that is induced by the applied mitigation measures. We contribute a multi-objective Markov decision process that encapsulates the stochastic compartment model that was used to inform policy makers during the COVID-19 epidemic. As these social mitigation measures are implemented in a continuous action space that modulates the contact matrix of the age-structured epidemic model, we extend PCN to this setting. We evaluate the solution returned by PCN, and observe that it correctly learns to reduce the social burden whenever the hospitalization rates are sufficiently low. In this work, we thus show that multi-objective reinforcement learning is attainable in complex epidemiological models and provides essential insights to balance complex mitigation policies.
Expected Scalarised Returns Dominance: A New Solution Concept for Multi-Objective Decision Making
Jun 02, 2021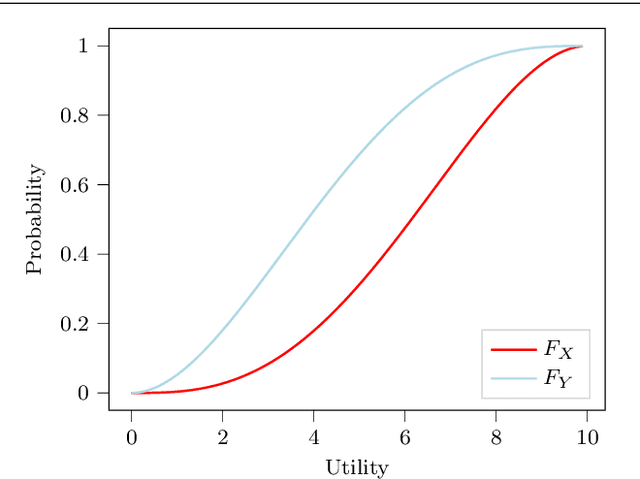

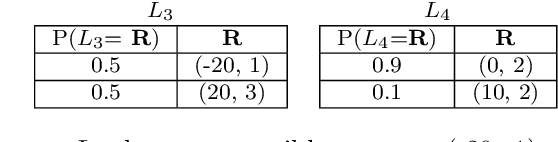
In many real-world scenarios, the utility of a user is derived from the single execution of a policy. In this case, to apply multi-objective reinforcement learning, the expected utility of the returns must be optimised. Various scenarios exist where a user's preferences over objectives (also known as the utility function) are unknown or difficult to specify. In such scenarios, a set of optimal policies must be learned. However, settings where the expected utility must be maximised have been largely overlooked by the multi-objective reinforcement learning community and, as a consequence, a set of optimal solutions has yet to be defined. In this paper we address this challenge by proposing first-order stochastic dominance as a criterion to build solution sets to maximise expected utility. We also propose a new dominance criterion, known as expected scalarised returns (ESR) dominance, that extends first-order stochastic dominance to allow a set of optimal policies to be learned in practice. We then define a new solution concept called the ESR set, which is a set of policies that are ESR dominant. Finally, we define a new multi-objective distributional tabular reinforcement learning (MOT-DRL) algorithm to learn the ESR set in a multi-objective multi-armed bandit setting.
A Practical Guide to Multi-Objective Reinforcement Learning and Planning
Mar 17, 2021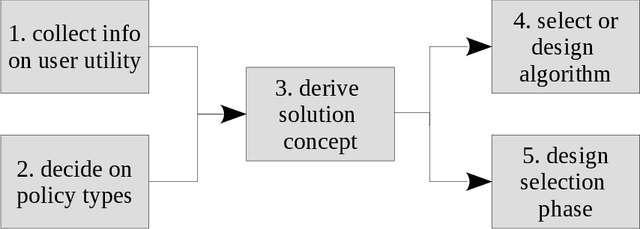

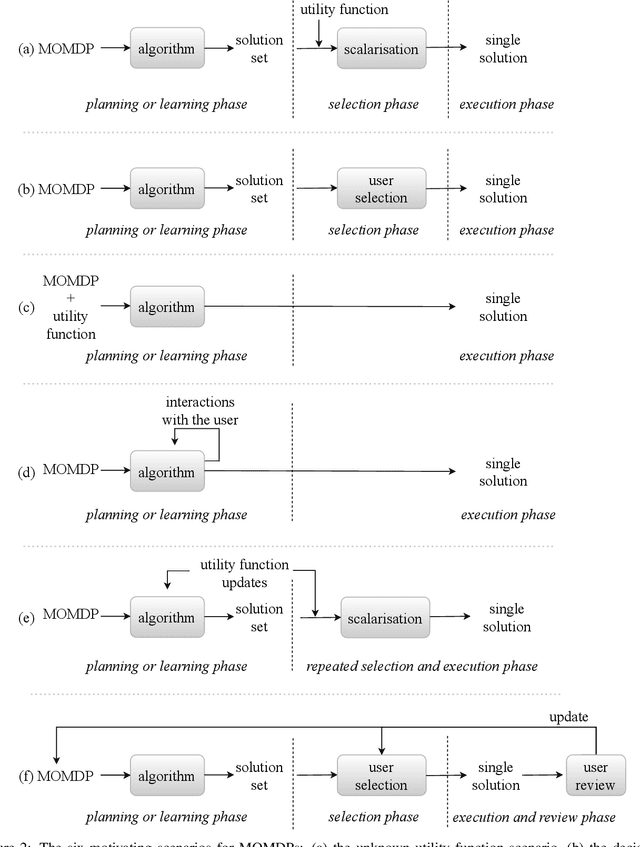
Real-world decision-making tasks are generally complex, requiring trade-offs between multiple, often conflicting, objectives. Despite this, the majority of research in reinforcement learning and decision-theoretic planning either assumes only a single objective, or that multiple objectives can be adequately handled via a simple linear combination. Such approaches may oversimplify the underlying problem and hence produce suboptimal results. This paper serves as a guide to the application of multi-objective methods to difficult problems, and is aimed at researchers who are already familiar with single-objective reinforcement learning and planning methods who wish to adopt a multi-objective perspective on their research, as well as practitioners who encounter multi-objective decision problems in practice. It identifies the factors that may influence the nature of the desired solution, and illustrates by example how these influence the design of multi-objective decision-making systems for complex problems.
Risk Aware and Multi-Objective Decision Making with Distributional Monte Carlo Tree Search
Feb 02, 2021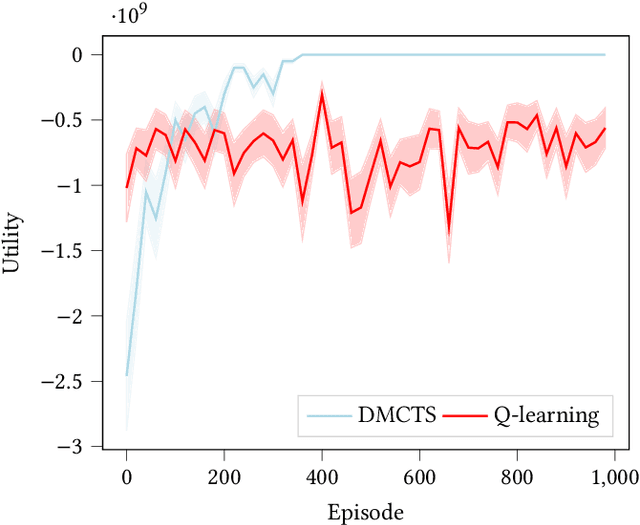
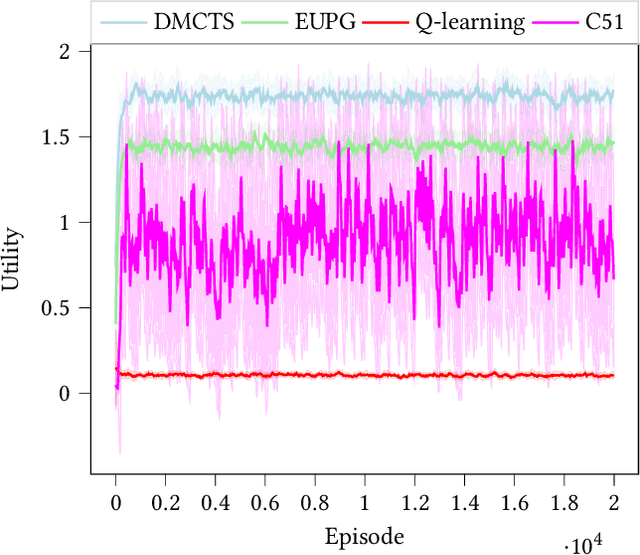
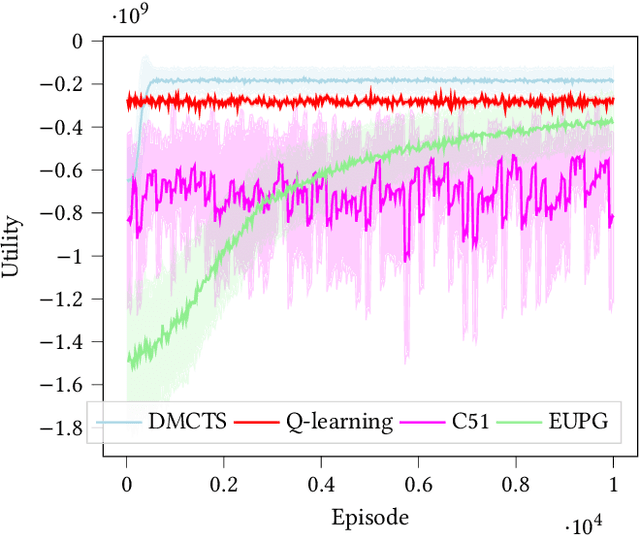
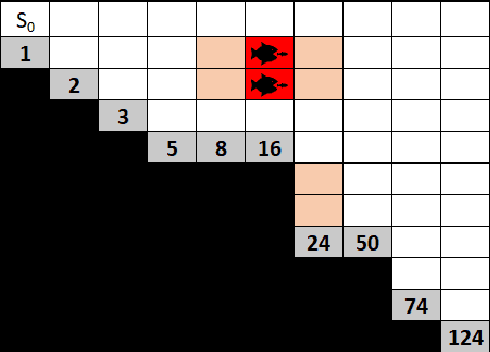
In many risk-aware and multi-objective reinforcement learning settings, the utility of the user is derived from the single execution of a policy. In these settings, making decisions based on the average future returns is not suitable. For example, in a medical setting a patient may only have one opportunity to treat their illness. When making a decision, just the expected return -- known in reinforcement learning as the value -- cannot account for the potential range of adverse or positive outcomes a decision may have. Our key insight is that we should use the distribution over expected future returns differently to represent the critical information that the agent requires at decision time. In this paper, we propose Distributional Monte Carlo Tree Search, an algorithm that learns a posterior distribution over the utility of the different possible returns attainable from individual policy executions, resulting in good policies for both risk-aware and multi-objective settings. Moreover, our algorithm outperforms the state-of-the-art in multi-objective reinforcement learning for the expected utility of the returns.