 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Guided Iterated Pareto Referent Optimisation for Accessible Route Planning
Apr 01, 2026We propose the Preference Guided Iterated Pareto Referent Optimisation (PG-IPRO) for urban route planning for people with different accessibility requirements and preferences. With this algorithm the user can interact with the system by giving feedback on a route, i.e., the user can say which objective should be further minimized, or conversely can be relaxed. This leads to intuitive user interaction, that is especially effective during early iterations compared to information-gain-based interaction. Furthermore, due to PG-IPRO's iterative nature, the full set of alternative, possibly optimal policies (the Pareto front), is never computed, leading to higher computational efficiency and shorter waiting times for users.
DéjàQ: Open-Ended Evolution of Diverse, Learnable and Verifiable Problems
Jan 05, 2026Recent advances in reasoning models have yielded impressive results in mathematics and coding. However, most approaches rely on static datasets, which have been suggested to encourage memorisation and limit generalisation. We introduce DéjàQ, a framework that departs from this paradigm by jointly evolving a diverse set of synthetic mathematical problems alongside model training. This evolutionary process adapts to the model's ability throughout training, optimising problems for learnability. We propose two LLM-driven mutation strategies in which the model itself mutates the training data, either by altering contextual details or by directly modifying problem structure. We find that the model can generate novel and meaningful problems, and that these LLM-driven mutations improve RL training. We analyse key aspects of DéjàQ, including the validity of generated problems and computational overhead. Our results underscore the potential of dynamically evolving training data to enhance mathematical reasoning and indicate broader applicability, which we will support by open-sourcing our code.
Scalable Multi-Objective Reinforcement Learning with Fairness Guarantees using Lorenz Dominance
Nov 27, 2024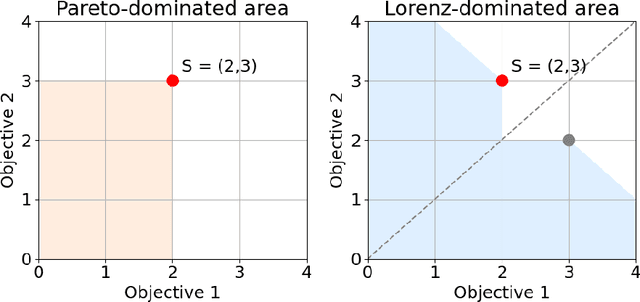

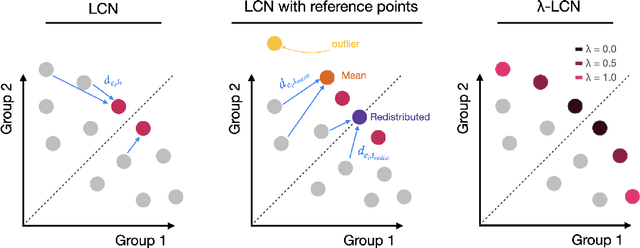
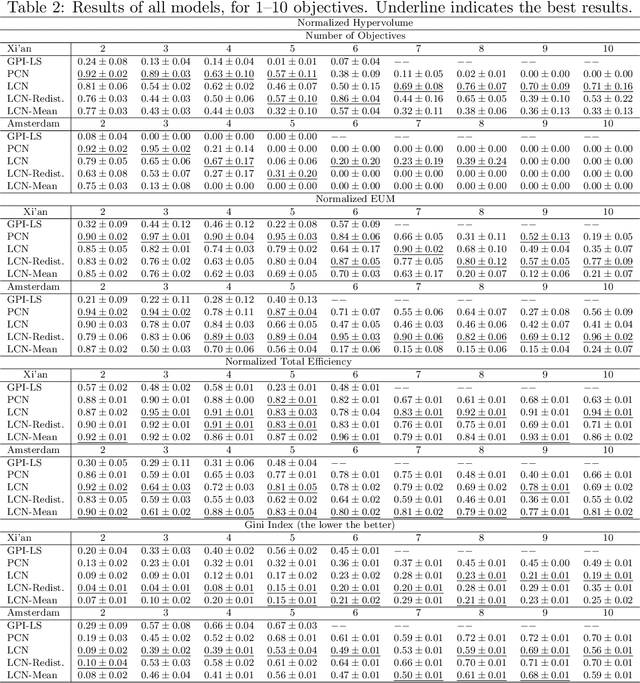
Multi-Objective Reinforcement Learning (MORL) aims to learn a set of policies that optimize trade-offs between multiple, often conflicting objectives. MORL is computationally more complex than single-objective RL, particularly as the number of objectives increases. Additionally, when objectives involve the preferences of agents or groups, ensuring fairness is socially desirable. This paper introduces a principled algorithm that incorporates fairness into MORL while improving scalability to many-objective problems. We propose using Lorenz dominance to identify policies with equitable reward distributions and introduce {\lambda}-Lorenz dominance to enable flexible fairness preferences. We release a new, large-scale real-world transport planning environment and demonstrate that our method encourages the discovery of fair policies, showing improved scalability in two large cities (Xi'an and Amsterdam). Our methods outperform common multi-objective approaches, particularly in high-dimensional objective spaces.
MOMAland: A Set of Benchmarks for Multi-Objective Multi-Agent Reinforcement Learning
Jul 23, 2024



Many challenging tasks such as managing traffic systems, electricity grids, or supply chains involve complex decision-making processes that must balance multiple conflicting objectives and coordinate the actions of various independent decision-makers (DMs). One perspective for formalising and addressing such tasks is multi-objective multi-agent reinforcement learning (MOMARL). MOMARL broadens reinforcement learning (RL) to problems with multiple agents each needing to consider multiple objectives in their learning process. In reinforcement learning research, benchmarks are crucial in facilitating progress, evaluation, and reproducibility. The significance of benchmarks is underscored by the existence of numerous benchmark frameworks developed for various RL paradigms, including single-agent RL (e.g., Gymnasium), multi-agent RL (e.g., PettingZoo), and single-agent multi-objective RL (e.g., MO-Gymnasium). To support the advancement of the MOMARL field, we introduce MOMAland, the first collection of standardised environments for multi-objective multi-agent reinforcement learning. MOMAland addresses the need for comprehensive benchmarking in this emerging field, offering over 10 diverse environments that vary in the number of agents, state representations, reward structures, and utility considerations. To provide strong baselines for future research, MOMAland also includes algorithms capable of learning policies in such settings.
Divide and Conquer: Provably Unveiling the Pareto Front with Multi-Objective Reinforcement Learning
Feb 11, 2024A significant challenge in multi-objective reinforcement learning is obtaining a Pareto front of policies that attain optimal performance under different preferences. We introduce Iterated Pareto Referent Optimisation (IPRO), a principled algorithm that decomposes the task of finding the Pareto front into a sequence of single-objective problems for which various solution methods exist. This enables us to establish convergence guarantees while providing an upper bound on the distance to undiscovered Pareto optimal solutions at each step. Empirical evaluations demonstrate that IPRO matches or outperforms methods that require additional domain knowledge. By leveraging problem-specific single-objective solvers, our approach also holds promise for applications beyond multi-objective reinforcement learning, such as in pathfinding and optimisation.
Utility-Based Reinforcement Learning: Unifying Single-objective and Multi-objective Reinforcement Learning
Feb 05, 2024Research in multi-objective reinforcement learning (MORL) has introduced the utility-based paradigm, which makes use of both environmental rewards and a function that defines the utility derived by the user from those rewards. In this paper we extend this paradigm to the context of single-objective reinforcement learning (RL), and outline multiple potential benefits including the ability to perform multi-policy learning across tasks relating to uncertain objectives, risk-aware RL, discounting, and safe RL. We also examine the algorithmic implications of adopting a utility-based approach.
Distributional Multi-Objective Decision Making
May 19, 2023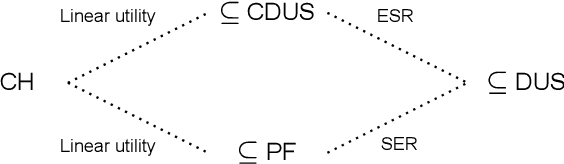

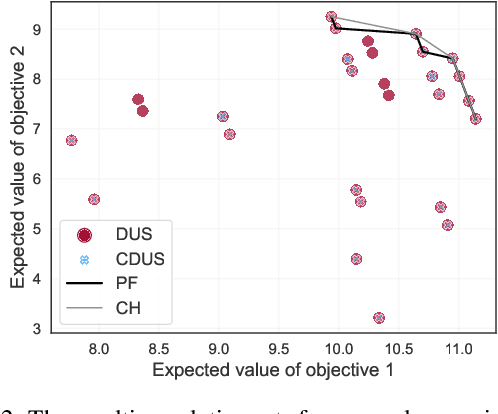
For effective decision support in scenarios with conflicting objectives, sets of potentially optimal solutions can be presented to the decision maker. We explore both what policies these sets should contain and how such sets can be computed efficiently. With this in mind, we take a distributional approach and introduce a novel dominance criterion relating return distributions of policies directly. Based on this criterion, we present the distributional undominated set and show that it contains optimal policies otherwise ignored by the Pareto front. In addition, we propose the convex distributional undominated set and prove that it comprises all policies that maximise expected utility for multivariate risk-averse decision makers. We propose a novel algorithm to learn the distributional undominated set and further contribute pruning operators to reduce the set to the convex distributional undominated set. Through experiments, we demonstrate the feasibility and effectiveness of these methods, making this a valuable new approach for decision support in real-world problems.
Preference Communication in Multi-Objective Normal-Form Games
Nov 17, 2021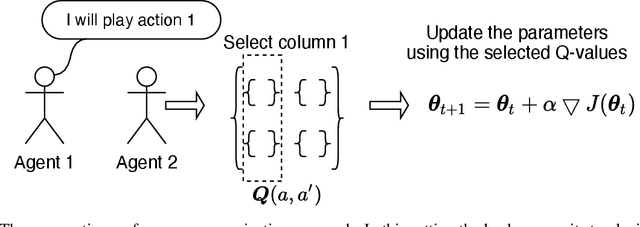
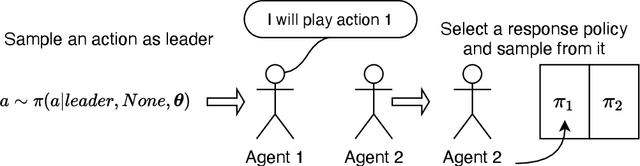

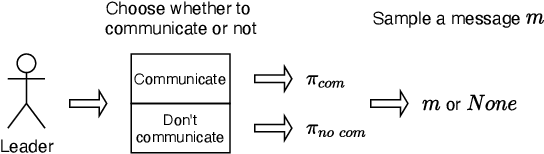
We study the problem of multiple agents learning concurrently in a multi-objective environment. Specifically, we consider two agents that repeatedly play a multi-objective normal-form game. In such games, the payoffs resulting from joint actions are vector valued. Taking a utility-based approach, we assume a utility function exists that maps vectors to scalar utilities and consider agents that aim to maximise the utility of expected payoff vectors. As agents do not necessarily know their opponent's utility function or strategy, they must learn optimal policies to interact with each other. To aid agents in arriving at adequate solutions, we introduce four novel preference communication protocols for both cooperative as well as self-interested communication. Each approach describes a specific protocol for one agent communicating preferences over their actions and how another agent responds. These protocols are subsequently evaluated on a set of five benchmark games against baseline agents that do not communicate. We find that preference communication can drastically alter the learning process and lead to the emergence of cyclic Nash equilibria which had not been previously observed in this setting. Additionally, we introduce a communication scheme where agents must learn when to communicate. For agents in games with Nash equilibria, we find that communication can be beneficial but difficult to learn when agents have different preferred equilibria. When this is not the case, agents become indifferent to communication. In games without Nash equilibria, our results show differences across learning rates. When using faster learners, we observe that explicit communication becomes more prevalent at around 50% of the time, as it helps them in learning a compromise joint policy. Slower learners retain this pattern to a lesser degree, but show increased indifference.