 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2Perf: Real-World Autonomous Agents Benchmark
Mar 04, 2025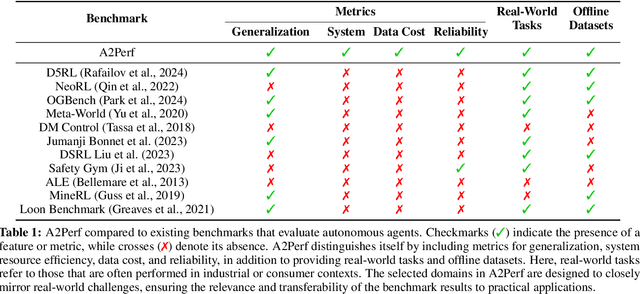

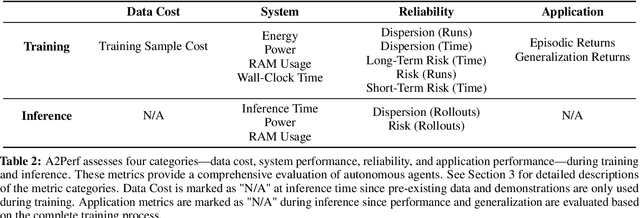

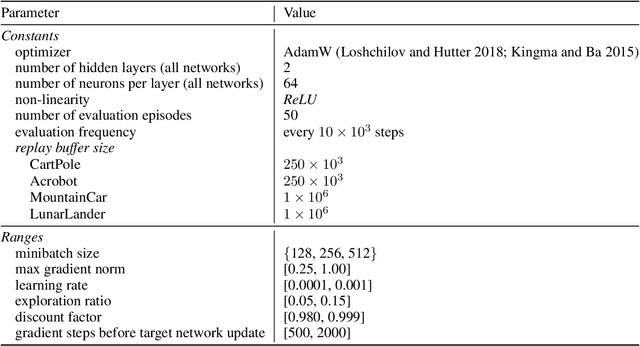
Autonomous agents and systems cover a number of application areas, from robotics and digital assistants to combinatorial optimization, all sharing common, unresolved research challenges. It is not sufficient for agents to merely solve a given task; they must generalize to out-of-distribution tasks, perform reliably, and use hardware resources efficiently during training and inference, among other requirements. Several methods, such as reinforcement learning and imitation learning, are commonly used to tackle these problems, each with different trade-offs. However, there is a lack of benchmarking suites that define the environments, datasets, and metrics which can be used to provide a meaningful way for the community to compare progress on applying these methods to real-world problems. We introduce A2Perf--a benchmark with three environments that closely resemble real-world domains: computer chip floorplanning, web navigation, and quadruped locomotion. A2Perf provides metrics that track task performance, generalization, system resource efficiency, and reliability, which are all critical to real-world applications. Using A2Perf, we demonstrate that web navigation agents can achieve latencies comparable to human reaction times on consumer hardware, reveal reliability trade-offs between algorithms for quadruped locomotion, and quantify the energy costs of different learning approaches for computer chip-design. In addition, we propose a data cost metric to account for the cost incurred acquiring offline data for imitation learning and hybrid algorithms, which allows us to better compare these approaches. A2Perf also contains several standard baselines, enabling apples-to-apples comparisons across methods and facilitating progress in real-world autonomy. As an open-source benchmark, A2Perf is designed to remain accessible, up-to-date, and useful to the research community over the long term.
MOMAland: A Set of Benchmarks for Multi-Objective Multi-Agent Reinforcement Learning
Jul 23, 2024



Many challenging tasks such as managing traffic systems, electricity grids, or supply chains involve complex decision-making processes that must balance multiple conflicting objectives and coordinate the actions of various independent decision-makers (DMs). One perspective for formalising and addressing such tasks is multi-objective multi-agent reinforcement learning (MOMARL). MOMARL broadens reinforcement learning (RL) to problems with multiple agents each needing to consider multiple objectives in their learning process. In reinforcement learning research, benchmarks are crucial in facilitating progress, evaluation, and reproducibility. The significance of benchmarks is underscored by the existence of numerous benchmark frameworks developed for various RL paradigms, including single-agent RL (e.g., Gymnasium), multi-agent RL (e.g., PettingZoo), and single-agent multi-objective RL (e.g., MO-Gymnasium). To support the advancement of the MOMARL field, we introduce MOMAland, the first collection of standardised environments for multi-objective multi-agent reinforcement learning. MOMAland addresses the need for comprehensive benchmarking in this emerging field, offering over 10 diverse environments that vary in the number of agents, state representations, reward structures, and utility considerations. To provide strong baselines for future research, MOMAland also includes algorithms capable of learning policies in such settings.
Some Supervision Required: Incorporating Oracle Policies in Reinforcement Learning via Epistemic Uncertainty Metrics
Aug 22, 2022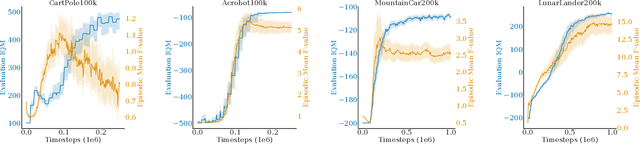


An inherent problem in reinforcement learning is coping with policies that are uncertain about what action to take (or the value of a state). Model uncertainty, more formally known as epistemic uncertainty, refers to the expected prediction error of a model beyond the sampling noise. In this paper, we propose a metric for epistemic uncertainty estimation in Q-value functions, which we term pathwise epistemic uncertainty. We further develop a method to compute its approximate upper bound, which we call F -value. We experimentally apply the latter to Deep Q-Networks (DQN) and show that uncertainty estimation in reinforcement learning serves as a useful indication of learning progress. We then propose a new approach to improving sample efficiency in actor-critic algorithms by learning from an existing (previously learned or hard-coded) oracle policy while uncertainty is high, aiming to avoid unproductive random actions during training. We term this Critic Confidence Guided Exploration (CCGE). We implement CCGE on Soft Actor-Critic (SAC) using our F-value metric, which we apply to a handful of popular Gym environments and show that it achieves better sample efficiency and total episodic reward than vanilla SAC in limited contexts.