 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Champion-level Vision-based Reinforcement Learning Agent for Competitive Racing in Gran Turismo 7
Apr 12, 2025Deep reinforcement learning has achieved superhuman racing performance in high-fidelity simulators like Gran Turismo 7 (GT7). It typically utilizes global features that require instrumentation external to a car, such as precise localization of agents and opponents, limiting real-world applicability. To address this limitation, we introduce a vision-based autonomous racing agent that relies solely on ego-centric camera views and onboard sensor data, eliminating the need for precise localization during inference. This agent employs an asymmetric actor-critic framework: the actor uses a recurrent neural network with the sensor data local to the car to retain track layouts and opponent positions, while the critic accesses the global features during training. Evaluated in GT7, our agent consistently outperforms GT7's built-drivers. To our knowledge, this work presents the first vision-based autonomous racing agent to demonstrate champion-level performance in competitive racing scenarios.
SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning
Oct 13, 2024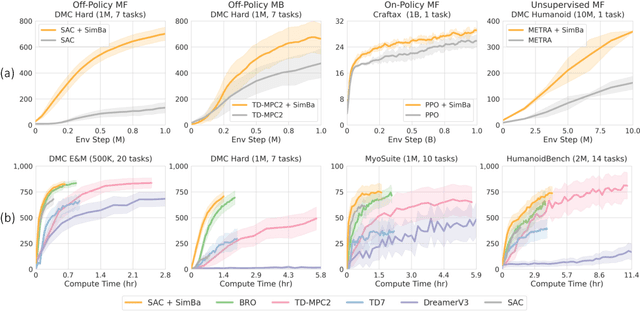

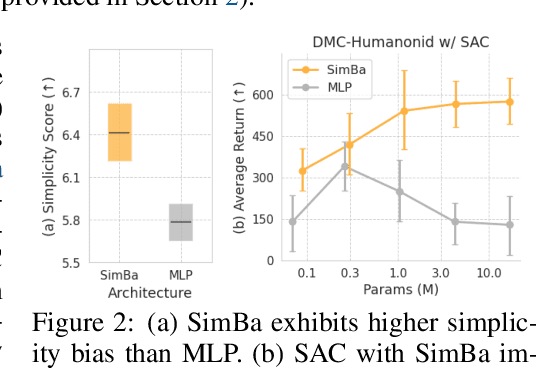
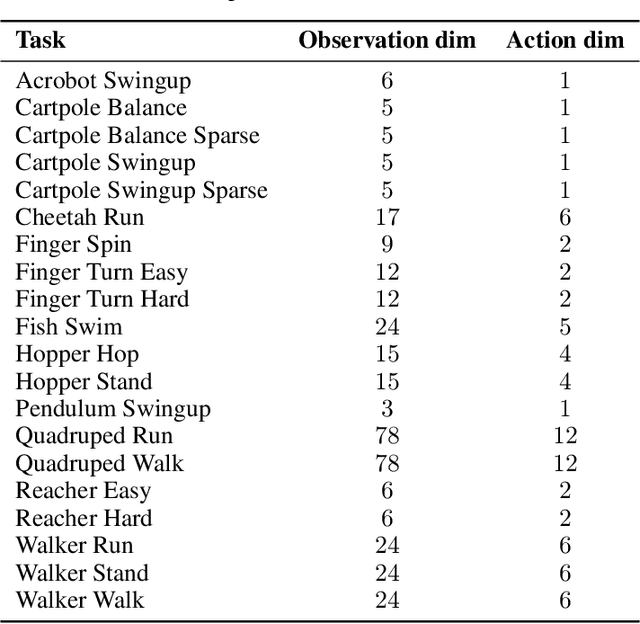
Recent advances in CV and NLP have been largely driven by scaling up the number of network parameters, despite traditional theories suggesting that larger networks are prone to overfitting. These large networks avoid overfitting by integrating components that induce a simplicity bias, guiding models toward simple and generalizable solutions. However, in deep RL, designing and scaling up networks have been less explored. Motivated by this opportunity, we present SimBa, an architecture designed to scale up parameters in deep RL by injecting a simplicity bias. SimBa consists of three components: (i) an observation normalization layer that standardizes inputs with running statistics, (ii) a residual feedforward block to provide a linear pathway from the input to output, and (iii) a layer normalization to control feature magnitudes. By scaling up parameters with SimBa, the sample efficiency of various deep RL algorithms-including off-policy, on-policy, and unsupervised methods-is consistently improved. Moreover, solely by integrating SimBa architecture into SAC, it matches or surpasses state-of-the-art deep RL methods with high computational efficiency across DMC, MyoSuite, and HumanoidBench. These results demonstrate SimBa's broad applicability and effectiveness across diverse RL algorithms and environments.
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Jul 24, 2024
Gymnasium is an open-source library providing an API for reinforcement learning environments. Its main contribution is a central abstraction for wide interoperability between benchmark environments and training algorithms. Gymnasium comes with various built-in environments and utilities to simplify researchers' work along with being supported by most training libraries. This paper outlines the main design decisions for Gymnasium, its key features, and the differences to alternative APIs.
PyFlyt -- UAV Simulation Environments for Reinforcement Learning Research
Apr 03, 2023
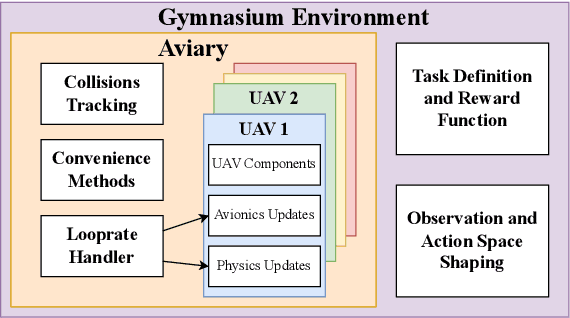

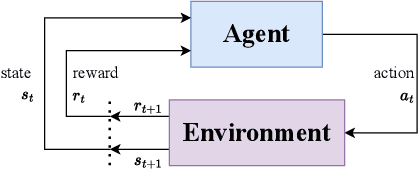
Unmanned aerial vehicles (UAVs) have numerous applications, but their efficient and optimal flight can be a challenge. Reinforcement Learning (RL) has emerged as a promising approach to address this challenge, yet there is no standardized library for testing and benchmarking RL algorithms on UAVs. In this paper, we introduce PyFlyt, a platform built on the Bullet physics engine with native Gymnasium API support. PyFlyt provides modular implementations of simple components, such as motors and lifting surfaces, allowing for the implementation of UAVs of arbitrary configurations. Additionally, PyFlyt includes various task definitions and multiple reward function settings for each vehicle type. We demonstrate the effectiveness of PyFlyt by training various RL agents for two UAV models: quadrotor and fixed-wing. Our findings highlight the effectiveness of RL in UAV control and planning, and further show that it is possible to train agents in sparse reward settings for UAVs. PyFlyt fills a gap in existing literature by providing a flexible and standardised platform for testing RL algorithms on UAVs. We believe that this will inspire more standardised research in this direction.
Some Supervision Required: Incorporating Oracle Policies in Reinforcement Learning via Epistemic Uncertainty Metrics
Aug 22, 2022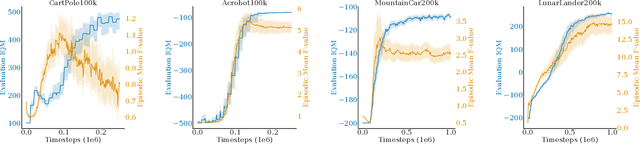


An inherent problem in reinforcement learning is coping with policies that are uncertain about what action to take (or the value of a state). Model uncertainty, more formally known as epistemic uncertainty, refers to the expected prediction error of a model beyond the sampling noise. In this paper, we propose a metric for epistemic uncertainty estimation in Q-value functions, which we term pathwise epistemic uncertainty. We further develop a method to compute its approximate upper bound, which we call F -value. We experimentally apply the latter to Deep Q-Networks (DQN) and show that uncertainty estimation in reinforcement learning serves as a useful indication of learning progress. We then propose a new approach to improving sample efficiency in actor-critic algorithms by learning from an existing (previously learned or hard-coded) oracle policy while uncertainty is high, aiming to avoid unproductive random actions during training. We term this Critic Confidence Guided Exploration (CCGE). We implement CCGE on Soft Actor-Critic (SAC) using our F-value metric, which we apply to a handful of popular Gym environments and show that it achieves better sample efficiency and total episodic reward than vanilla SAC in limited contexts.
FasteNet: A Fast Railway Fastener Detector
Dec 14, 2020



In this work, a novel high-speed railway fastener detector is introduced. This fully convolutional network, dubbed FasteNet, foregoes the notion of bounding boxes and performs detection directly on a predicted saliency map. Fastenet uses transposed convolutions and skip connections, the effective receptive field of the network is 1.5$\times$ larger than the average size of a fastener, enabling the network to make predictions with high confidence, without sacrificing output resolution. In addition, due to the saliency map approach, the network is able to vote for the presence of a fastener up to 30 times per fastener, boosting prediction accuracy. Fastenet is capable of running at 110 FPS on an Nvidia GTX 1080, while taking in inputs of 1600$\times$512 with an average of 14 fasteners per image. Our source is open here: https://github.com/jjshoots/DL\_FasteNet.git
BOBBY2: Buffer Based Robust High-Speed Object Tracking
Oct 18, 2019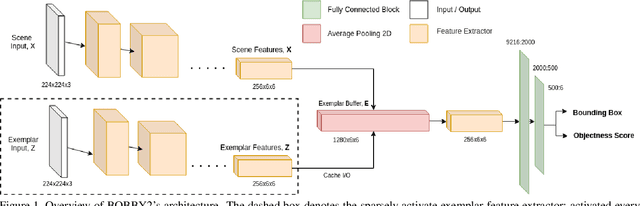



In this work, a novel high-speed single object tracker that is robust against non-semantic distractor exemplars is introduced; dubbed BOBBY2. It incorporates a novel exemplar buffer module that sparsely caches the target's appearance across time, enabling it to adapt to potential target deformation. As for training, an augmented ImageNet-VID dataset was used in conjunction with the one cycle policy, enabling it to reach convergence with less than 2 epoch worth of data. For validation, the model was benchmarked on the GOT-10k dataset and on an additional small, albeit challenging custom UAV dataset collected with the TU-3 UAV. We demonstrate that the exemplar buffer is capable of providing redundancies in case of unintended target drifts, a desirable trait in any middle to long term tracking. Even when the buffer is predominantly filled with distractors instead of valid exemplars, BOBBY2 is capable of maintaining a near-optimal level of accuracy. BOBBY2 manages to achieve a very competitive result on the GOT-10k dataset and to a lesser degree on the challenging custom TU-3 dataset, without fine-tuning, demonstrating its generalizability. In terms of speed, BOBBY2 utilizes a stripped down AlexNet as feature extractor with 63% less parameters than a vanilla AlexNet, thus being able to run at a competitive 85 FPS.