 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyFlyt -- UAV Simulation Environments for Reinforcement Learning Research
Apr 03, 2023
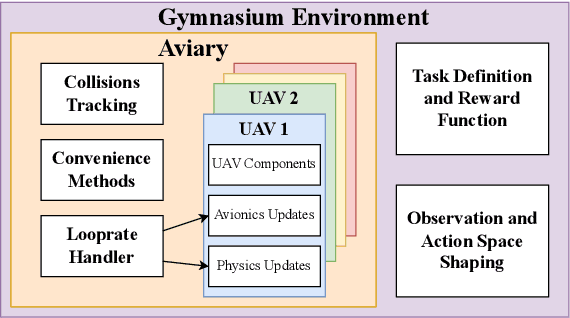

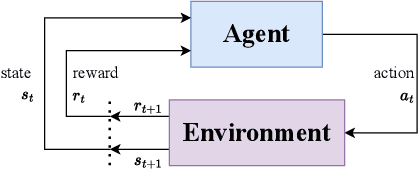
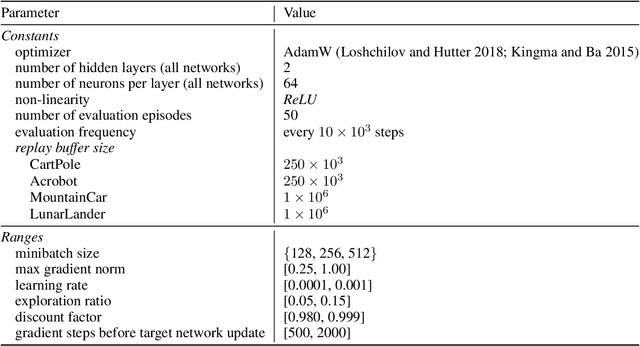
Unmanned aerial vehicles (UAVs) have numerous applications, but their efficient and optimal flight can be a challenge. Reinforcement Learning (RL) has emerged as a promising approach to address this challenge, yet there is no standardized library for testing and benchmarking RL algorithms on UAVs. In this paper, we introduce PyFlyt, a platform built on the Bullet physics engine with native Gymnasium API support. PyFlyt provides modular implementations of simple components, such as motors and lifting surfaces, allowing for the implementation of UAVs of arbitrary configurations. Additionally, PyFlyt includes various task definitions and multiple reward function settings for each vehicle type. We demonstrate the effectiveness of PyFlyt by training various RL agents for two UAV models: quadrotor and fixed-wing. Our findings highlight the effectiveness of RL in UAV control and planning, and further show that it is possible to train agents in sparse reward settings for UAVs. PyFlyt fills a gap in existing literature by providing a flexible and standardised platform for testing RL algorithms on UAVs. We believe that this will inspire more standardised research in this direction.
Some Supervision Required: Incorporating Oracle Policies in Reinforcement Learning via Epistemic Uncertainty Metrics
Aug 22, 2022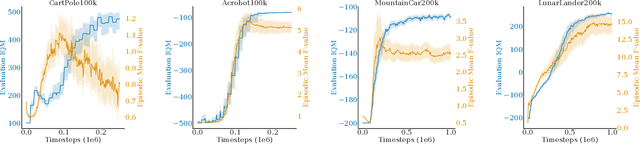


An inherent problem in reinforcement learning is coping with policies that are uncertain about what action to take (or the value of a state). Model uncertainty, more formally known as epistemic uncertainty, refers to the expected prediction error of a model beyond the sampling noise. In this paper, we propose a metric for epistemic uncertainty estimation in Q-value functions, which we term pathwise epistemic uncertainty. We further develop a method to compute its approximate upper bound, which we call F -value. We experimentally apply the latter to Deep Q-Networks (DQN) and show that uncertainty estimation in reinforcement learning serves as a useful indication of learning progress. We then propose a new approach to improving sample efficiency in actor-critic algorithms by learning from an existing (previously learned or hard-coded) oracle policy while uncertainty is high, aiming to avoid unproductive random actions during training. We term this Critic Confidence Guided Exploration (CCGE). We implement CCGE on Soft Actor-Critic (SAC) using our F-value metric, which we apply to a handful of popular Gym environments and show that it achieves better sample efficiency and total episodic reward than vanilla SAC in limited contexts.