 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSome Supervision Required: Incorporating Oracle Policies in Reinforcement Learning via Epistemic Uncertainty Metrics
Paper and Code
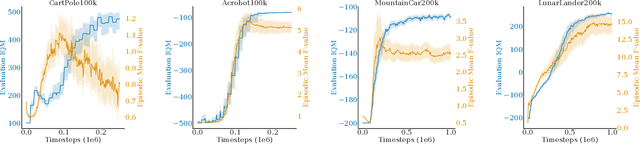


An inherent problem in reinforcement learning is coping with policies that are uncertain about what action to take (or the value of a state). Model uncertainty, more formally known as epistemic uncertainty, refers to the expected prediction error of a model beyond the sampling noise. In this paper, we propose a metric for epistemic uncertainty estimation in Q-value functions, which we term pathwise epistemic uncertainty. We further develop a method to compute its approximate upper bound, which we call F -value. We experimentally apply the latter to Deep Q-Networks (DQN) and show that uncertainty estimation in reinforcement learning serves as a useful indication of learning progress. We then propose a new approach to improving sample efficiency in actor-critic algorithms by learning from an existing (previously learned or hard-coded) oracle policy while uncertainty is high, aiming to avoid unproductive random actions during training. We term this Critic Confidence Guided Exploration (CCGE). We implement CCGE on Soft Actor-Critic (SAC) using our F-value metric, which we apply to a handful of popular Gym environments and show that it achieves better sample efficiency and total episodic reward than vanilla SAC in limited contexts.