 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDA: Reward Design Agent for Reinforcement Learning
Jun 01, 2026Reinforcement learning has enabled the acquisition of impressive robotic skills, but typically requires hand-crafted reward functions that are slow to design and difficult to align with human intentions. Recent work, such as Eureka, automates reward design by using an LLM to iteratively generate and refine reward code from task descriptions. However, they rely on coarse feedback signals such as success rate, which provide little semantic insight into the learned behavior. As a result, their trained policies achieve the final goal but are frequently poorly aligned with task instructions. We introduce the Reward Design Agent (RDA), a VLM-based agentic framework that injects semantic understanding into reward design. RDA decomposes tasks, visually evaluates trajectories, summarizes failure modes, and iteratively revises reward code to better align with task instructions. Across 12 tabletop manipulation tasks from ManiSkill and 4 whole-body manipulation tasks from HumanoidBench, RDA produces policies substantially more instruction-aligned than those of other baselines, while achieving comparable task success rates. Videos and the generated reward code are available on https://nitinkamra1992.github.io/reward-design-agent.
FlashSAC: Fast and Stable Off-Policy Reinforcement Learning for High-Dimensional Robot Control
Apr 06, 2026Reinforcement learning (RL) is a core approach for robot control when expert demonstrations are unavailable. On-policy methods such as Proximal Policy Optimization (PPO) are widely used for their stability, but their reliance on narrowly distributed on-policy data limits accurate policy evaluation in high-dimensional state and action spaces. Off-policy methods can overcome this limitation by learning from a broader state-action distribution, yet suffer from slow convergence and instability, as fitting a value function over diverse data requires many gradient updates, causing critic errors to accumulate through bootstrapping. We present FlashSAC, a fast and stable off-policy RL algorithm built on Soft Actor-Critic. Motivated by scaling laws observed in supervised learning, FlashSAC sharply reduces gradient updates while compensating with larger models and higher data throughput. To maintain stability at increased scale, FlashSAC explicitly bounds weight, feature, and gradient norms, curbing critic error accumulation. Across over 60 tasks in 10 simulators, FlashSAC consistently outperforms PPO and strong off-policy baselines in both final performance and training efficiency, with the largest gains on high-dimensional tasks such as dexterous manipulation. In sim-to-real humanoid locomotion, FlashSAC reduces training time from hours to minutes, demonstrating the promise of off-policy RL for sim-to-real transfer.
FIRE: Frobenius-Isometry Reinitialization for Balancing the Stability-Plasticity Tradeoff
Feb 08, 2026Deep neural networks trained on nonstationary data must balance stability (i.e., retaining prior knowledge) and plasticity (i.e., adapting to new tasks). Standard reinitialization methods, which reinitialize weights toward their original values, are widely used but difficult to tune: conservative reinitializations fail to restore plasticity, while aggressive ones erase useful knowledge. We propose FIRE, a principled reinitialization method that explicitly balances the stability-plasticity tradeoff. FIRE quantifies stability through Squared Frobenius Error (SFE), measuring proximity to past weights, and plasticity through Deviation from Isometry (DfI), reflecting weight isotropy. The reinitialization point is obtained by solving a constrained optimization problem, minimizing SFE subject to DfI being zero, which is efficiently approximated by Newton-Schulz iteration. FIRE is evaluated on continual visual learning (CIFAR-10 with ResNet-18), language modeling (OpenWebText with GPT-0.1B), and reinforcement learning (HumanoidBench with SAC and Atari games with DQN). Across all domains, FIRE consistently outperforms both naive training without intervention and standard reinitialization methods, demonstrating effective balancing of the stability-plasticity tradeoff.
Instance-Aware Test-Time Segmentation for Continual Domain Shifts
Dec 09, 2025Continual Test-Time Adaptation (CTTA) enables pre-trained models to adapt to continuously evolving domains. Existing methods have improved robustness but typically rely on fixed or batch-level thresholds, which cannot account for varying difficulty across classes and instances. This limitation is especially problematic in semantic segmentation, where each image requires dense, multi-class predictions. We propose an approach that adaptively adjusts pseudo labels to reflect the confidence distribution within each image and dynamically balances learning toward classes most affected by domain shifts. This fine-grained, class- and instance-aware adaptation produces more reliable supervision and mitigates error accumulation throughout continual adaptation. Extensive experiments across eight CTTA and TTA scenarios, including synthetic-to-real and long-term shifts, show that our method consistently outperforms state-of-the-art techniques, setting a new standard for semantic segmentation under evolving conditions.
PHUMA: Physically-Grounded Humanoid Locomotion Dataset
Oct 30, 2025



Motion imitation is a promising approach for humanoid locomotion, enabling agents to acquire humanlike behaviors. Existing methods typically rely on high-quality motion capture datasets such as AMASS, but these are scarce and expensive, limiting scalability and diversity. Recent studies attempt to scale data collection by converting large-scale internet videos, exemplified by Humanoid-X. However, they often introduce physical artifacts such as floating, penetration, and foot skating, which hinder stable imitation. In response, we introduce PHUMA, a Physically-grounded HUMAnoid locomotion dataset that leverages human video at scale, while addressing physical artifacts through careful data curation and physics-constrained retargeting. PHUMA enforces joint limits, ensures ground contact, and eliminates foot skating, producing motions that are both large-scale and physically reliable. We evaluated PHUMA in two sets of conditions: (i) imitation of unseen motion from self-recorded test videos and (ii) path following with pelvis-only guidance. In both cases, PHUMA-trained policies outperform Humanoid-X and AMASS, achieving significant gains in imitating diverse motions. The code is available at https://davian-robotics.github.io/PHUMA.
A Champion-level Vision-based Reinforcement Learning Agent for Competitive Racing in Gran Turismo 7
Apr 12, 2025Deep reinforcement learning has achieved superhuman racing performance in high-fidelity simulators like Gran Turismo 7 (GT7). It typically utilizes global features that require instrumentation external to a car, such as precise localization of agents and opponents, limiting real-world applicability. To address this limitation, we introduce a vision-based autonomous racing agent that relies solely on ego-centric camera views and onboard sensor data, eliminating the need for precise localization during inference. This agent employs an asymmetric actor-critic framework: the actor uses a recurrent neural network with the sensor data local to the car to retain track layouts and opponent positions, while the critic accesses the global features during training. Evaluated in GT7, our agent consistently outperforms GT7's built-drivers. To our knowledge, this work presents the first vision-based autonomous racing agent to demonstrate champion-level performance in competitive racing scenarios.
Hyperspherical Normalization for Scalable Deep Reinforcement Learning
Feb 21, 2025Scaling up the model size and computation has brought consistent performance improvements in supervised learning. However, this lesson often fails to apply to reinforcement learning (RL) because training the model on non-stationary data easily leads to overfitting and unstable optimization. In response, we introduce SimbaV2, a novel RL architecture designed to stabilize optimization by (i) constraining the growth of weight and feature norm by hyperspherical normalization; and (ii) using a distributional value estimation with reward scaling to maintain stable gradients under varying reward magnitudes. Using the soft actor-critic as a base algorithm, SimbaV2 scales up effectively with larger models and greater compute, achieving state-of-the-art performance on 57 continuous control tasks across 4 domains. The code is available at https://dojeon-ai.github.io/SimbaV2.
SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning
Oct 13, 2024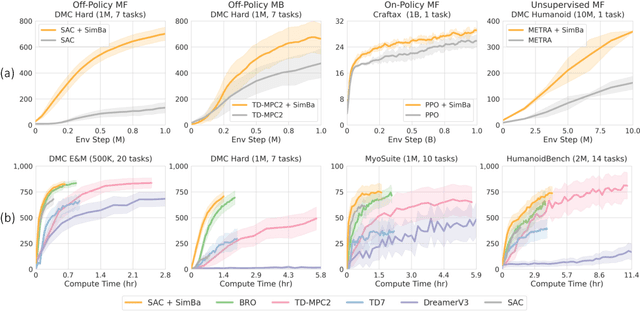

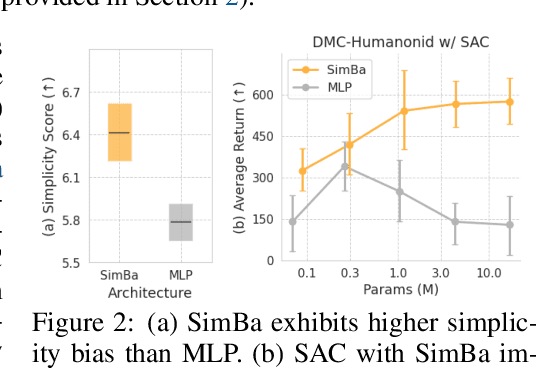
Recent advances in CV and NLP have been largely driven by scaling up the number of network parameters, despite traditional theories suggesting that larger networks are prone to overfitting. These large networks avoid overfitting by integrating components that induce a simplicity bias, guiding models toward simple and generalizable solutions. However, in deep RL, designing and scaling up networks have been less explored. Motivated by this opportunity, we present SimBa, an architecture designed to scale up parameters in deep RL by injecting a simplicity bias. SimBa consists of three components: (i) an observation normalization layer that standardizes inputs with running statistics, (ii) a residual feedforward block to provide a linear pathway from the input to output, and (iii) a layer normalization to control feature magnitudes. By scaling up parameters with SimBa, the sample efficiency of various deep RL algorithms-including off-policy, on-policy, and unsupervised methods-is consistently improved. Moreover, solely by integrating SimBa architecture into SAC, it matches or surpasses state-of-the-art deep RL methods with high computational efficiency across DMC, MyoSuite, and HumanoidBench. These results demonstrate SimBa's broad applicability and effectiveness across diverse RL algorithms and environments.
Investigating Pre-Training Objectives for Generalization in Vision-Based Reinforcement Learning
Jun 10, 2024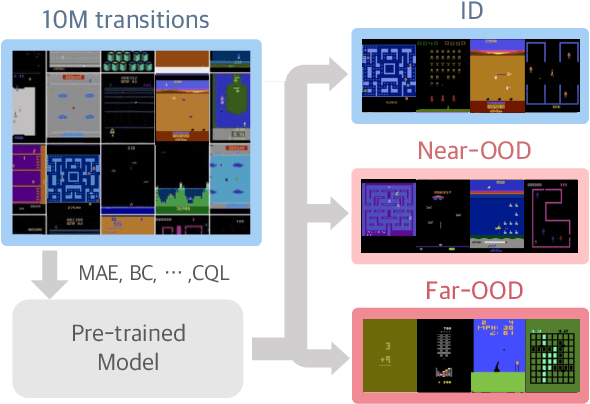



Recently, various pre-training methods have been introduced in vision-based Reinforcement Learning (RL). However, their generalization ability remains unclear due to evaluations being limited to in-distribution environments and non-unified experimental setups. To address this, we introduce the Atari Pre-training Benchmark (Atari-PB), which pre-trains a ResNet-50 model on 10 million transitions from 50 Atari games and evaluates it across diverse environment distributions. Our experiments show that pre-training objectives focused on learning task-agnostic features (e.g., identifying objects and understanding temporal dynamics) enhance generalization across different environments. In contrast, objectives focused on learning task-specific knowledge (e.g., identifying agents and fitting reward functions) improve performance in environments similar to the pre-training dataset but not in varied ones. We publicize our codes, datasets, and model checkpoints at https://github.com/dojeon-ai/Atari-PB.
Adapting Pretrained ViTs with Convolution Injector for Visuo-Motor Control
Jun 10, 2024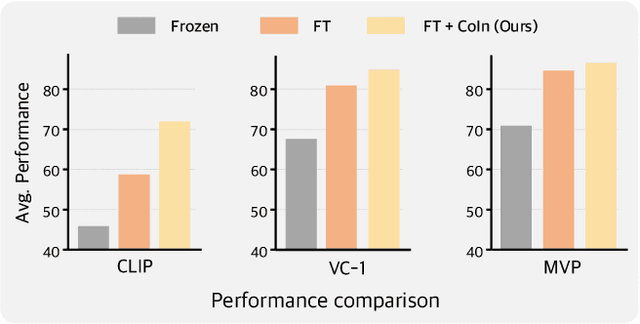
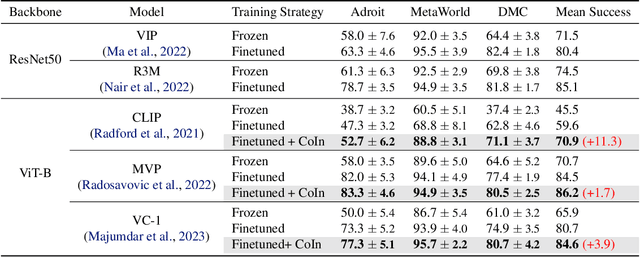
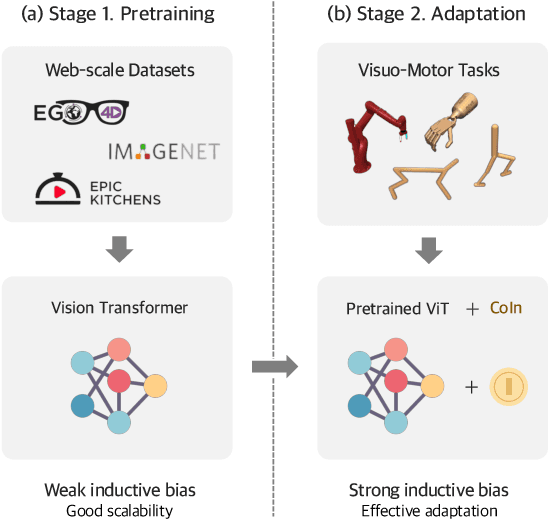
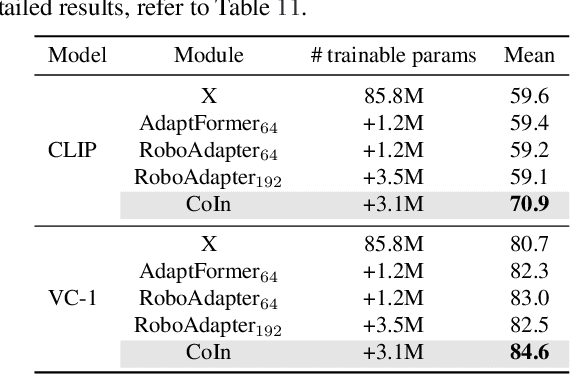
Vision Transformers (ViT), when paired with large-scale pretraining, have shown remarkable performance across various computer vision tasks, primarily due to their weak inductive bias. However, while such weak inductive bias aids in pretraining scalability, this may hinder the effective adaptation of ViTs for visuo-motor control tasks as a result of the absence of control-centric inductive biases. Such absent inductive biases include spatial locality and translation equivariance bias which convolutions naturally offer. To this end, we introduce Convolution Injector (CoIn), an add-on module that injects convolutions which are rich in locality and equivariance biases into a pretrained ViT for effective adaptation in visuo-motor control. We evaluate CoIn with three distinct types of pretrained ViTs (CLIP, MVP, VC-1) across 12 varied control tasks within three separate domains (Adroit, MetaWorld, DMC), and demonstrate that CoIn consistently enhances control task performance across all experimented environments and models, validating the effectiveness of providing pretrained ViTs with control-centric biases.