 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHUMA: Physically-Grounded Humanoid Locomotion Dataset
Oct 30, 2025



Motion imitation is a promising approach for humanoid locomotion, enabling agents to acquire humanlike behaviors. Existing methods typically rely on high-quality motion capture datasets such as AMASS, but these are scarce and expensive, limiting scalability and diversity. Recent studies attempt to scale data collection by converting large-scale internet videos, exemplified by Humanoid-X. However, they often introduce physical artifacts such as floating, penetration, and foot skating, which hinder stable imitation. In response, we introduce PHUMA, a Physically-grounded HUMAnoid locomotion dataset that leverages human video at scale, while addressing physical artifacts through careful data curation and physics-constrained retargeting. PHUMA enforces joint limits, ensures ground contact, and eliminates foot skating, producing motions that are both large-scale and physically reliable. We evaluated PHUMA in two sets of conditions: (i) imitation of unseen motion from self-recorded test videos and (ii) path following with pelvis-only guidance. In both cases, PHUMA-trained policies outperform Humanoid-X and AMASS, achieving significant gains in imitating diverse motions. The code is available at https://davian-robotics.github.io/PHUMA.
SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning
Oct 13, 2024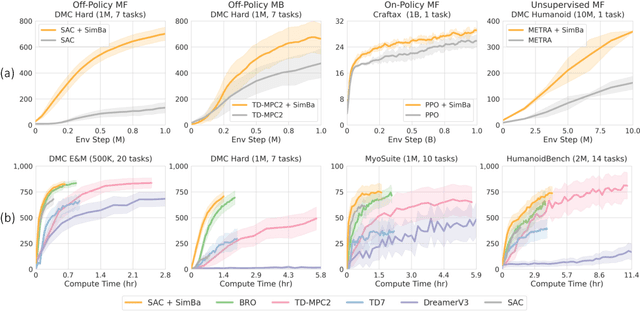

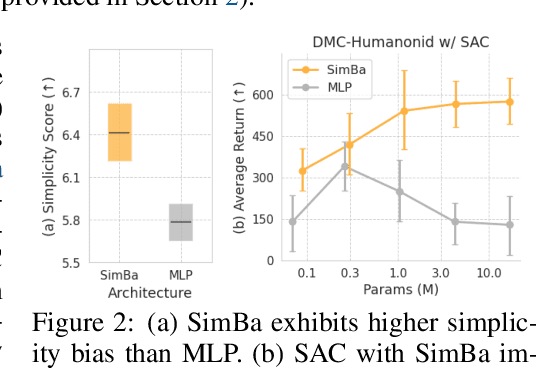
Recent advances in CV and NLP have been largely driven by scaling up the number of network parameters, despite traditional theories suggesting that larger networks are prone to overfitting. These large networks avoid overfitting by integrating components that induce a simplicity bias, guiding models toward simple and generalizable solutions. However, in deep RL, designing and scaling up networks have been less explored. Motivated by this opportunity, we present SimBa, an architecture designed to scale up parameters in deep RL by injecting a simplicity bias. SimBa consists of three components: (i) an observation normalization layer that standardizes inputs with running statistics, (ii) a residual feedforward block to provide a linear pathway from the input to output, and (iii) a layer normalization to control feature magnitudes. By scaling up parameters with SimBa, the sample efficiency of various deep RL algorithms-including off-policy, on-policy, and unsupervised methods-is consistently improved. Moreover, solely by integrating SimBa architecture into SAC, it matches or surpasses state-of-the-art deep RL methods with high computational efficiency across DMC, MyoSuite, and HumanoidBench. These results demonstrate SimBa's broad applicability and effectiveness across diverse RL algorithms and environments.
Scalable Multi-Task Transfer Learning for Molecular Property Prediction
Oct 01, 2024



Molecules have a number of distinct properties whose importance and application vary. Often, in reality, labels for some properties are hard to achieve despite their practical importance. A common solution to such data scarcity is to use models of good generalization with transfer learning. This involves domain experts for designing source and target tasks whose features are shared. However, this approach has limitations: i). Difficulty in accurate design of source-target task pairs due to the large number of tasks, and ii). corresponding computational burden verifying many trials and errors of transfer learning design, thereby iii). constraining the potential of foundation modeling of multi-task molecular property prediction. We address the limitations of the manual design of transfer learning via data-driven bi-level optimization. The proposed method enables scalable multi-task transfer learning for molecular property prediction by automatically obtaining the optimal transfer ratios. Empirically, the proposed method improved the prediction performance of 40 molecular properties and accelerated training convergence.
Task Addition in Multi-Task Learning by Geometrical Alignment
Sep 25, 2024



Training deep learning models on limited data while maintaining generalization is one of the fundamental challenges in molecular property prediction. One effective solution is transferring knowledge extracted from abundant datasets to those with scarce data. Recently, a novel algorithm called Geometrically Aligned Transfer Encoder (GATE) has been introduced, which uses soft parameter sharing by aligning the geometrical shapes of task-specific latent spaces. However, GATE faces limitations in scaling to multiple tasks due to computational costs. In this study, we propose a task addition approach for GATE to improve performance on target tasks with limited data while minimizing computational complexity. It is achieved through supervised multi-task pre-training on a large dataset, followed by the addition and training of task-specific modules for each target task. Our experiments demonstrate the superior performance of the task addition strategy for GATE over conventional multi-task methods, with comparable computational costs.
Adapting Pretrained ViTs with Convolution Injector for Visuo-Motor Control
Jun 10, 2024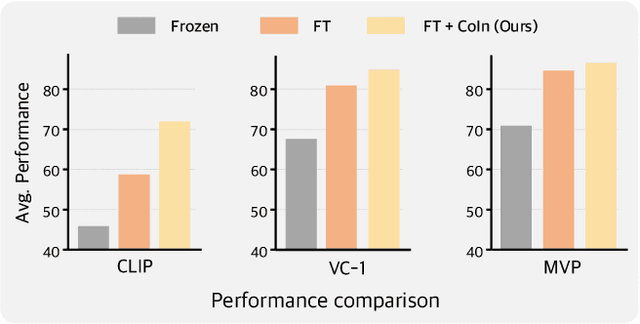
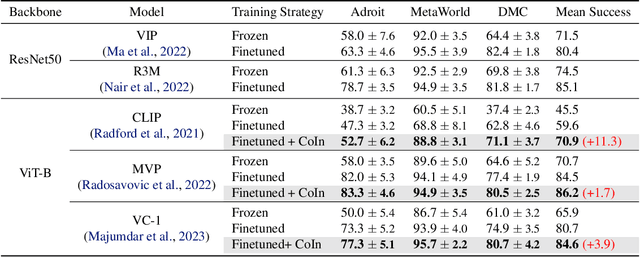
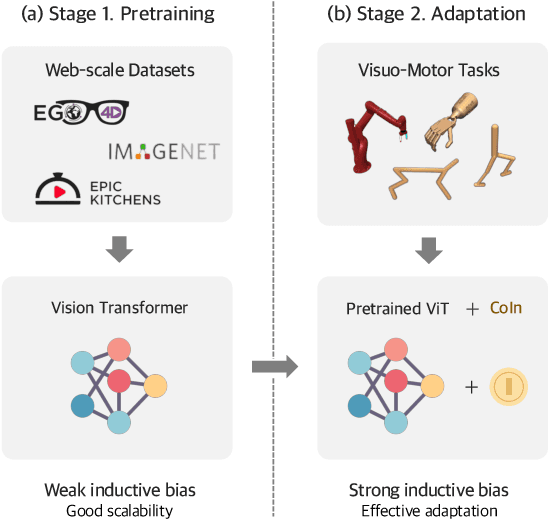
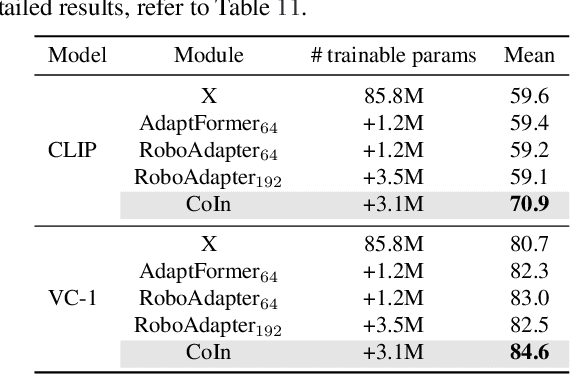
Vision Transformers (ViT), when paired with large-scale pretraining, have shown remarkable performance across various computer vision tasks, primarily due to their weak inductive bias. However, while such weak inductive bias aids in pretraining scalability, this may hinder the effective adaptation of ViTs for visuo-motor control tasks as a result of the absence of control-centric inductive biases. Such absent inductive biases include spatial locality and translation equivariance bias which convolutions naturally offer. To this end, we introduce Convolution Injector (CoIn), an add-on module that injects convolutions which are rich in locality and equivariance biases into a pretrained ViT for effective adaptation in visuo-motor control. We evaluate CoIn with three distinct types of pretrained ViTs (CLIP, MVP, VC-1) across 12 varied control tasks within three separate domains (Adroit, MetaWorld, DMC), and demonstrate that CoIn consistently enhances control task performance across all experimented environments and models, validating the effectiveness of providing pretrained ViTs with control-centric biases.
Do's and Don'ts: Learning Desirable Skills with Instruction Videos
Jun 01, 2024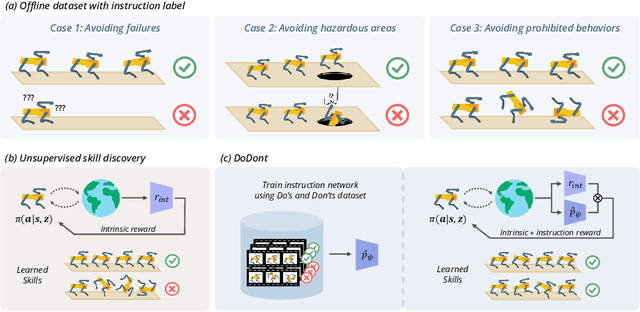


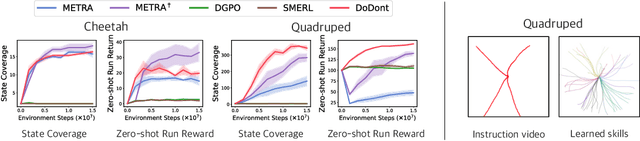
Unsupervised skill discovery is a learning paradigm that aims to acquire diverse behaviors without explicit rewards. However, it faces challenges in learning complex behaviors and often leads to learning unsafe or undesirable behaviors. For instance, in various continuous control tasks, current unsupervised skill discovery methods succeed in learning basic locomotions like standing but struggle with learning more complex movements such as walking and running. Moreover, they may acquire unsafe behaviors like tripping and rolling or navigate to undesirable locations such as pitfalls or hazardous areas. In response, we present DoDont (Do's and Don'ts), an instruction-based skill discovery algorithm composed of two stages. First, in an instruction learning stage, DoDont leverages action-free instruction videos to train an instruction network to distinguish desirable transitions from undesirable ones. Then, in the skill learning stage, the instruction network adjusts the reward function of the skill discovery algorithm to weight the desired behaviors. Specifically, we integrate the instruction network into a distance-maximizing skill discovery algorithm, where the instruction network serves as the distance function. Empirically, with less than 8 instruction videos, DoDont effectively learns desirable behaviors and avoids undesirable ones across complex continuous control tasks. Code and videos are available at https://mynsng.github.io/dodont/
Slow and Steady Wins the Race: Maintaining Plasticity with Hare and Tortoise Networks
Jun 01, 2024This study investigates the loss of generalization ability in neural networks, revisiting warm-starting experiments from Ash & Adams. Our empirical analysis reveals that common methods designed to enhance plasticity by maintaining trainability provide limited benefits to generalization. While reinitializing the network can be effective, it also risks losing valuable prior knowledge. To this end, we introduce the Hare & Tortoise, inspired by the brain's complementary learning system. Hare & Tortoise consists of two components: the Hare network, which rapidly adapts to new information analogously to the hippocampus, and the Tortoise network, which gradually integrates knowledge akin to the neocortex. By periodically reinitializing the Hare network to the Tortoise's weights, our method preserves plasticity while retaining general knowledge. Hare & Tortoise can effectively maintain the network's ability to generalize, which improves advanced reinforcement learning algorithms on the Atari-100k benchmark. The code is available at https://github.com/dojeon-ai/hare-tortoise.
Multitask Extension of Geometrically Aligned Transfer Encoder
May 03, 2024



Molecular datasets often suffer from a lack of data. It is well-known that gathering data is difficult due to the complexity of experimentation or simulation involved. Here, we leverage mutual information across different tasks in molecular data to address this issue. We extend an algorithm that utilizes the geometric characteristics of the encoding space, known as the Geometrically Aligned Transfer Encoder (GATE), to a multi-task setup. Thus, we connect multiple molecular tasks by aligning the curved coordinates onto locally flat coordinates, ensuring the flow of information from source tasks to support performance on target data.
Learning to Discover Skills through Guidance
Nov 01, 2023In the field of unsupervised skill discovery (USD), a major challenge is limited exploration, primarily due to substantial penalties when skills deviate from their initial trajectories. To enhance exploration, recent methodologies employ auxiliary rewards to maximize the epistemic uncertainty or entropy of states. However, we have identified that the effectiveness of these rewards declines as the environmental complexity rises. Therefore, we present a novel USD algorithm, skill discovery with guidance (DISCO-DANCE), which (1) selects the guide skill that possesses the highest potential to reach unexplored states, (2) guides other skills to follow guide skill, then (3) the guided skills are dispersed to maximize their discriminability in unexplored states. Empirical evaluation demonstrates that DISCO-DANCE outperforms other USD baselines in challenging environments, including two navigation benchmarks and a continuous control benchmark. Qualitative visualizations and code of DISCO-DANCE are available at https://mynsng.github.io/discodance.
Enhancing Generalization and Plasticity for Sample Efficient Reinforcement Learning
Jun 19, 2023



In Reinforcement Learning (RL), enhancing sample efficiency is crucial, particularly in scenarios when data acquisition is costly and risky. In principle, off-policy RL algorithms can improve sample efficiency by allowing multiple updates per environment interaction. However, these multiple updates often lead to overfitting, which decreases the network's ability to adapt to new data. We conduct an empirical analysis of this challenge and find that generalizability and plasticity constitute different roles in improving the model's adaptability. In response, we propose a combined usage of Sharpness-Aware Minimization (SAM) and a reset mechanism. SAM seeks wide, smooth minima, improving generalization, while the reset mechanism, through periodic reinitialization of the last few layers, consistently injects plasticity into the model. Through extensive empirical studies, we demonstrate that this combined usage improves sample efficiency and computational cost on the Atari-100k and DeepMind Control Suite benchmarks.