 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinor First, Major Last: A Depth-Induced Implicit Bias of Sharpness-Aware Minimization
Mar 09, 2026We study the implicit bias of Sharpness-Aware Minimization (SAM) when training $L$-layer linear diagonal networks on linearly separable binary classification. For linear models ($L=1$), both $\ell_\infty$- and $\ell_2$-SAM recover the $\ell_2$ max-margin classifier, matching gradient descent (GD). However, for depth $L = 2$, the behavior changes drastically -- even on a single-example dataset. For $\ell_\infty$-SAM, the limit direction depends critically on initialization and can converge to $\mathbf{0}$ or to any standard basis vector, in stark contrast to GD, whose limit aligns with the basis vector of the dominant data coordinate. For $\ell_2$-SAM, we show that although its limit direction matches the $\ell_1$ max-margin solution as in the case of GD, its finite-time dynamics exhibit a phenomenon we call "sequential feature amplification", in which the predictor initially relies on minor coordinates and gradually shifts to larger ones as training proceeds or initialization increases. Our theoretical analysis attributes this phenomenon to $\ell_2$-SAM's gradient normalization factor applied in its perturbation, which amplifies minor coordinates early and allows major ones to dominate later, giving a concrete example where infinite-time implicit-bias analyses are insufficient. Synthetic and real-data experiments corroborate our findings.
Implicit Bias and Loss of Plasticity in Matrix Completion: Depth Promotes Low-Rankness
Mar 05, 2026We study matrix completion via deep matrix factorization (a.k.a. deep linear neural networks) as a simplified testbed to examine how network depth influences training dynamics. Despite the simplicity and importance of the problem, prior theory largely focuses on shallow (depth-2) models and does not fully explain the implicit low-rank bias observed in deeper networks. We identify coupled dynamics as a key mechanism behind this bias and show that it intensifies with increasing depth. Focusing on gradient flow under block-diagonal observations, we prove: (a) networks of depth $\geq 3$ exhibit coupling unless initialized diagonally, and (b) convergence to rank-1 occurs if and only if the dynamics is coupled -- resolving an open question by Menon (2024) for a family of initializations. We also revisit the loss of plasticity phenomenon in matrix completion (Kleinman et al., 2024), where pre-training on few observations and resuming with more degrades performance. We show that deep models avoid plasticity loss due to their low-rank bias, whereas depth-2 networks pre-trained under decoupled dynamics fail to converge to low-rank, even when resumed training (with additional data) satisfies the coupling condition -- shedding light on the mechanism behind this phenomenon.
Scaling Laws of SignSGD in Linear Regression: When Does It Outperform SGD?
Mar 02, 2026We study scaling laws of signSGD under a power-law random features (PLRF) model that accounts for both feature and target decay. We analyze the population risk of a linear model trained with one-pass signSGD on Gaussian-sketched features. We express the risk as a function of model size, training steps, learning rate, and the feature and target decay parameters. Comparing against the SGD risk analyzed by Paquette et al. (2024), we identify a drift-normalization effect and a noise-reshaping effect unique to signSGD. We then obtain compute-optimal scaling laws under the optimal choice of learning rate. Our analysis shows that the noise-reshaping effect can make the compute-optimal slope of signSGD steeper than that of SGD in regimes where noise is dominant. Finally, we observe that the widely used warmup-stable-decay (WSD) schedule further reduces the noise term and sharpens the compute-optimal slope, when feature decay is fast but target decay is slow.
Regularized Online RLHF with Generalized Bilinear Preferences
Feb 26, 2026We consider the problem of contextual online RLHF with general preferences, where the goal is to identify the Nash Equilibrium. We adopt the Generalized Bilinear Preference Model (GBPM) to capture potentially intransitive preferences via low-rank, skew-symmetric matrices. We investigate general preference learning with any strongly convex regularizer (where $η^{-1}$ is the regularization strength), generalizing beyond prior works limited to reverse KL-regularization. Central to our analysis is proving that the dual gap of the greedy policy is bounded by the square of the estimation error - a result derived solely from strong convexity and the skew-symmetricity of GBPM.Building on this insight and a feature diversity assumption, we establish two regret bounds via two simple algorithms: (1) Greedy Sampling achieves polylogarithmic, $e^{O(η)}$-free regret $\tilde{O}(ηd^4 (\log T)^2)$. (2) Explore-Then-Commit achieves $\mathrm{poly}(d)$-free regret $\tilde{O}(\sqrt{ηr T})$ by exploiting the low-rank structure; this is the first statistically efficient guarantee for online RLHF in high-dimensions.
Uniform Spectral Growth and Convergence of Muon in LoRA-Style Matrix Factorization
Feb 06, 2026Spectral gradient descent (SpecGD) orthogonalizes the matrix parameter updates and has inspired practical optimizers such as Muon. They often perform well in large language model (LLM) training, but their dynamics remain poorly understood. In the low-rank adaptation (LoRA) setting, where weight updates are parameterized as a product of two low-rank factors, we find a distinctive spectral phenomenon under Muon in LoRA fine-tuning of LLMs: singular values of the LoRA product show near-uniform growth across the spectrum, despite orthogonalization being performed on the two factors separately. Motivated by this observation, we analyze spectral gradient flow (SpecGF)-a continuous-time analogue of SpecGD-in a simplified LoRA-style matrix factorization setting and prove "equal-rate" dynamics: all singular values grow at equal rates up to small deviations. Consequently, smaller singular values attain their target values earlier than larger ones, sharply contrasting with the largest-first stepwise learning observed in standard gradient flow. Moreover, we prove that SpecGF in our setting converges to global minima from almost all initializations, provided the factor norms remain bounded; with $\ell_2$ regularization, we obtain global convergence. Lastly, we corroborate our theory with experiments in the same setting.
Implicit Bias of Per-sample Adam on Separable Data: Departure from the Full-batch Regime
Oct 30, 2025Adam [Kingma and Ba, 2015] is the de facto optimizer in deep learning, yet its theoretical understanding remains limited. Prior analyses show that Adam favors solutions aligned with $\ell_\infty$-geometry, but these results are restricted to the full-batch regime. In this work, we study the implicit bias of incremental Adam (using one sample per step) for logistic regression on linearly separable data, and we show that its bias can deviate from the full-batch behavior. To illustrate this, we construct a class of structured datasets where incremental Adam provably converges to the $\ell_2$-max-margin classifier, in contrast to the $\ell_\infty$-max-margin bias of full-batch Adam. For general datasets, we develop a proxy algorithm that captures the limiting behavior of incremental Adam as $\beta_2 \to 1$ and we characterize its convergence direction via a data-dependent dual fixed-point formulation. Finally, we prove that, unlike Adam, Signum [Bernstein et al., 2018] converges to the $\ell_\infty$-max-margin classifier for any batch size by taking $\beta$ close enough to 1. Overall, our results highlight that the implicit bias of Adam crucially depends on both the batching scheme and the dataset, while Signum remains invariant.
Understanding Sharpness Dynamics in NN Training with a Minimalist Example: The Effects of Dataset Difficulty, Depth, Stochasticity, and More
Jun 07, 2025When training deep neural networks with gradient descent, sharpness often increases -- a phenomenon known as progressive sharpening -- before saturating at the edge of stability. Although commonly observed in practice, the underlying mechanisms behind progressive sharpening remain poorly understood. In this work, we study this phenomenon using a minimalist model: a deep linear network with a single neuron per layer. We show that this simple model effectively captures the sharpness dynamics observed in recent empirical studies, offering a simple testbed to better understand neural network training. Moreover, we theoretically analyze how dataset properties, network depth, stochasticity of optimizers, and step size affect the degree of progressive sharpening in the minimalist model. We then empirically demonstrate how these theoretical insights extend to practical scenarios. This study offers a deeper understanding of sharpness dynamics in neural network training, highlighting the interplay between depth, training data, and optimizers.
Incremental Gradient Descent with Small Epoch Counts is Surprisingly Slow on Ill-Conditioned Problems
Jun 04, 2025Recent theoretical results demonstrate that the convergence rates of permutation-based SGD (e.g., random reshuffling SGD) are faster than uniform-sampling SGD; however, these studies focus mainly on the large epoch regime, where the number of epochs $K$ exceeds the condition number $\kappa$. In contrast, little is known when $K$ is smaller than $\kappa$, and it is still a challenging open question whether permutation-based SGD can converge faster in this small epoch regime (Safran and Shamir, 2021). As a step toward understanding this gap, we study the naive deterministic variant, Incremental Gradient Descent (IGD), on smooth and strongly convex functions. Our lower bounds reveal that for the small epoch regime, IGD can exhibit surprisingly slow convergence even when all component functions are strongly convex. Furthermore, when some component functions are allowed to be nonconvex, we prove that the optimality gap of IGD can be significantly worse throughout the small epoch regime. Our analyses reveal that the convergence properties of permutation-based SGD in the small epoch regime may vary drastically depending on the assumptions on component functions. Lastly, we supplement the paper with tight upper and lower bounds for IGD in the large epoch regime.
Convergence and Implicit Bias of Gradient Descent on Continual Linear Classification
Apr 17, 2025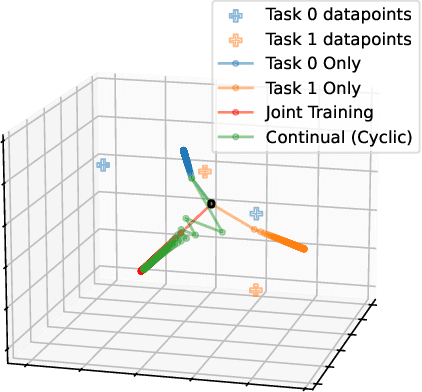
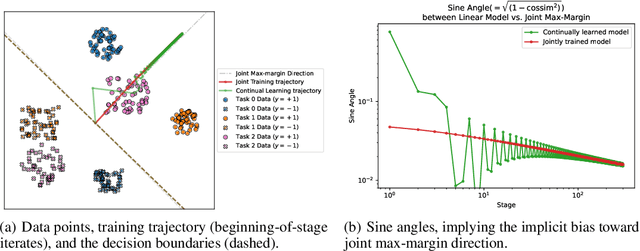
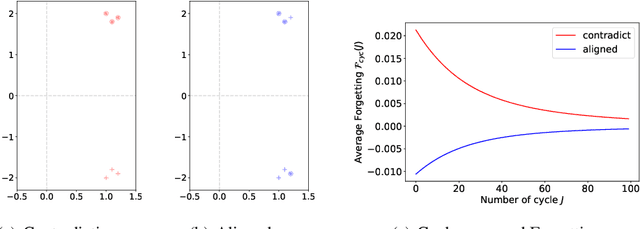
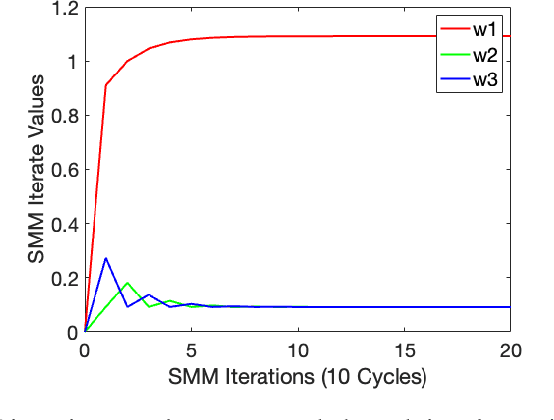
We study continual learning on multiple linear classification tasks by sequentially running gradient descent (GD) for a fixed budget of iterations per task. When all tasks are jointly linearly separable and are presented in a cyclic/random order, we show the directional convergence of the trained linear classifier to the joint (offline) max-margin solution. This is surprising because GD training on a single task is implicitly biased towards the individual max-margin solution for the task, and the direction of the joint max-margin solution can be largely different from these individual solutions. Additionally, when tasks are given in a cyclic order, we present a non-asymptotic analysis on cycle-averaged forgetting, revealing that (1) alignment between tasks is indeed closely tied to catastrophic forgetting and backward knowledge transfer and (2) the amount of forgetting vanishes to zero as the cycle repeats. Lastly, we analyze the case where the tasks are no longer jointly separable and show that the model trained in a cyclic order converges to the unique minimum of the joint loss function.
Lightweight Dataset Pruning without Full Training via Example Difficulty and Prediction Uncertainty
Feb 10, 2025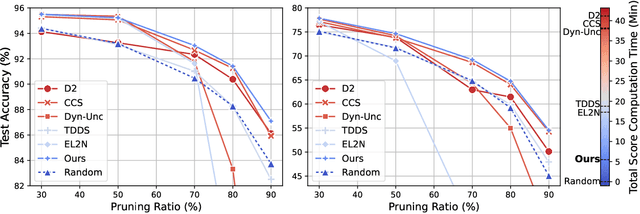
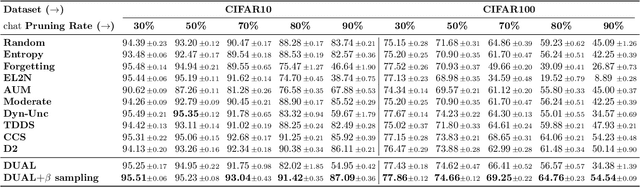
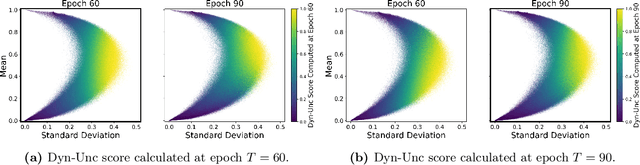
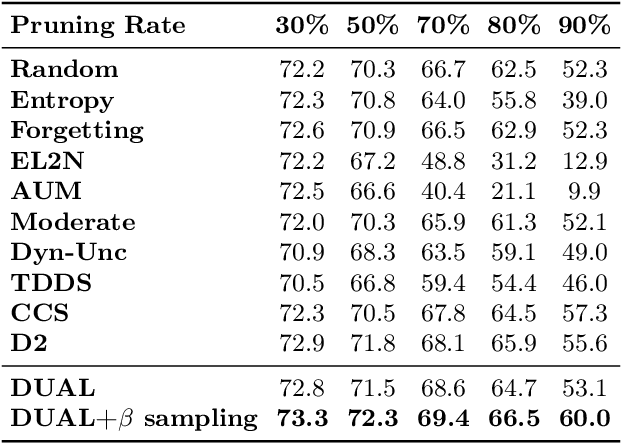
Recent advances in deep learning rely heavily on massive datasets, leading to substantial storage and training costs. Dataset pruning aims to alleviate this demand by discarding redundant examples. However, many existing methods require training a model with a full dataset over a large number of epochs before being able to prune the dataset, which ironically makes the pruning process more expensive than just training the model on the entire dataset. To overcome this limitation, we introduce a Difficulty and Uncertainty-Aware Lightweight (DUAL) score, which aims to identify important samples from the early training stage by considering both example difficulty and prediction uncertainty. To address a catastrophic accuracy drop at an extreme pruning, we further propose a ratio-adaptive sampling using Beta distribution. Experiments on various datasets and learning scenarios such as image classification with label noise and image corruption, and model architecture generalization demonstrate the superiority of our method over previous state-of-the-art (SOTA) approaches. Specifically, on ImageNet-1k, our method reduces the time cost for pruning to 66% compared to previous methods while achieving a SOTA, specifically 60% test accuracy at a 90% pruning ratio. On CIFAR datasets, the time cost is reduced to just 15% while maintaining SOTA performance.