 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy the Counterintuitive Phenomenon of Likelihood Rarely Appears in Tabular Anomaly Detection with Deep Generative Models?
Feb 10, 2026Deep generative models with tractable and analytically computable likelihoods, exemplified by normalizing flows, offer an effective basis for anomaly detection through likelihood-based scoring. We demonstrate that, unlike in the image domain where deep generative models frequently assign higher likelihoods to anomalous data, such counterintuitive behavior occurs far less often in tabular settings. We first introduce a domain-agnostic formulation that enables consistent detection and evaluation of the counterintuitive phenomenon, addressing the absence of precise definition. Through extensive experiments on 47 tabular datasets and 10 CV/NLP embedding datasets in ADBench, benchmarked against 13 baseline models, we demonstrate that the phenomenon, as defined, is consistently rare in general tabular data. We further investigate this phenomenon from both theoretical and empirical perspectives, focusing on the roles of data dimensionality and difference in feature correlation. Our results suggest that likelihood-only detection with normalizing flows offers a practical and reliable approach for anomaly detection in tabular domains.
Mitigating the Likelihood Paradox in Flow-based OOD Detection via Entropy Manipulation
Feb 10, 2026Deep generative models that can tractably compute input likelihoods, including normalizing flows, often assign unexpectedly high likelihoods to out-of-distribution (OOD) inputs. We mitigate this likelihood paradox by manipulating input entropy based on semantic similarity, applying stronger perturbations to inputs that are less similar to an in-distribution memory bank. We provide a theoretical analysis showing that entropy control increases the expected log-likelihood gap between in-distribution and OOD samples in favor of the in-distribution, and we explain why the procedure works without any additional training of the density model. We then evaluate our method against likelihood-based OOD detectors on standard benchmarks and find consistent AUROC improvements over baselines, supporting our explanation.
Cocoon: A System Architecture for Differentially Private Training with Correlated Noises
Oct 08, 2025Machine learning (ML) models memorize and leak training data, causing serious privacy issues to data owners. Training algorithms with differential privacy (DP), such as DP-SGD, have been gaining attention as a solution. However, DP-SGD adds a noise at each training iteration, which degrades the accuracy of the trained model. To improve accuracy, a new family of approaches adds carefully designed correlated noises, so that noises cancel out each other across iterations. We performed an extensive characterization study of these new mechanisms, for the first time to the best of our knowledge, and show they incur non-negligible overheads when the model is large or uses large embedding tables. Motivated by the analysis, we propose Cocoon, a hardware-software co-designed framework for efficient training with correlated noises. Cocoon accelerates models with embedding tables through pre-computing and storing correlated noises in a coalesced format (Cocoon-Emb), and supports large models through a custom near-memory processing device (Cocoon-NMP). On a real system with an FPGA-based NMP device prototype, Cocoon improves the performance by 2.33-10.82x(Cocoon-Emb) and 1.55-3.06x (Cocoon-NMP).
PARTE: Part-Guided Texturing for 3D Human Reconstruction from a Single Image
Jul 24, 2025The misaligned human texture across different human parts is one of the main limitations of existing 3D human reconstruction methods. Each human part, such as a jacket or pants, should maintain a distinct texture without blending into others. The structural coherence of human parts serves as a crucial cue to infer human textures in the invisible regions of a single image. However, most existing 3D human reconstruction methods do not explicitly exploit such part segmentation priors, leading to misaligned textures in their reconstructions. In this regard, we present PARTE, which utilizes 3D human part information as a key guide to reconstruct 3D human textures. Our framework comprises two core components. First, to infer 3D human part information from a single image, we propose a 3D part segmentation module (PartSegmenter) that initially reconstructs a textureless human surface and predicts human part labels based on the textureless surface. Second, to incorporate part information into texture reconstruction, we introduce a part-guided texturing module (PartTexturer), which acquires prior knowledge from a pre-trained image generation network on texture alignment of human parts. Extensive experiments demonstrate that our framework achieves state-of-the-art quality in 3D human reconstruction. The project page is available at https://hygenie1228.github.io/PARTE/.
DeClotH: Decomposable 3D Cloth and Human Body Reconstruction from a Single Image
Mar 25, 2025Most existing methods of 3D clothed human reconstruction from a single image treat the clothed human as a single object without distinguishing between cloth and human body. In this regard, we present DeClotH, which separately reconstructs 3D cloth and human body from a single image. This task remains largely unexplored due to the extreme occlusion between cloth and the human body, making it challenging to infer accurate geometries and textures. Moreover, while recent 3D human reconstruction methods have achieved impressive results using text-to-image diffusion models, directly applying such an approach to this problem often leads to incorrect guidance, particularly in reconstructing 3D cloth. To address these challenges, we propose two core designs in our framework. First, to alleviate the occlusion issue, we leverage 3D template models of cloth and human body as regularizations, which provide strong geometric priors to prevent erroneous reconstruction by the occlusion. Second, we introduce a cloth diffusion model specifically designed to provide contextual information about cloth appearance, thereby enhancing the reconstruction of 3D cloth. Qualitative and quantitative experiments demonstrate that our proposed approach is highly effective in reconstructing both 3D cloth and the human body. More qualitative results are provided at https://hygenie1228.github.io/DeClotH/.
Stochastic Extragradient with Flip-Flop Shuffling & Anchoring: Provable Improvements
Dec 31, 2024In minimax optimization, the extragradient (EG) method has been extensively studied because it outperforms the gradient descent-ascent method in convex-concave (C-C) problems. Yet, stochastic EG (SEG) has seen limited success in C-C problems, especially for unconstrained cases. Motivated by the recent progress of shuffling-based stochastic methods, we investigate the convergence of shuffling-based SEG in unconstrained finite-sum minimax problems, in search of convergent shuffling-based SEG. Our analysis reveals that both random reshuffling and the recently proposed flip-flop shuffling alone can suffer divergence in C-C problems. However, with an additional simple trick called anchoring, we develop the SEG with flip-flop anchoring (SEG-FFA) method which successfully converges in C-C problems. We also show upper and lower bounds in the strongly-convex-strongly-concave setting, demonstrating that SEG-FFA has a provably faster convergence rate compared to other shuffling-based methods.
Multi-hypotheses Conditioned Point Cloud Diffusion for 3D Human Reconstruction from Occluded Images
Sep 27, 2024



3D human shape reconstruction under severe occlusion due to human-object or human-human interaction is a challenging problem. Parametric models i.e., SMPL(-X), which are based on the statistics across human shapes, can represent whole human body shapes but are limited to minimally-clothed human shapes. Implicit-function-based methods extract features from the parametric models to employ prior knowledge of human bodies and can capture geometric details such as clothing and hair. However, they often struggle to handle misaligned parametric models and inpaint occluded regions given a single RGB image. In this work, we propose a novel pipeline, MHCDIFF, Multi-hypotheses Conditioned Point Cloud Diffusion, composed of point cloud diffusion conditioned on probabilistic distributions for pixel-aligned detailed 3D human reconstruction under occlusion. Compared to previous implicit-function-based methods, the point cloud diffusion model can capture the global consistent features to generate the occluded regions, and the denoising process corrects the misaligned SMPL meshes. The core of MHCDIFF is extracting local features from multiple hypothesized SMPL(-X) meshes and aggregating the set of features to condition the diffusion model. In the experiments on CAPE and MultiHuman datasets, the proposed method outperforms various SOTA methods based on SMPL, implicit functions, point cloud diffusion, and their combined, under synthetic and real occlusions.
Dense Hand-Object(HO) GraspNet with Full Grasping Taxonomy and Dynamics
Sep 06, 2024
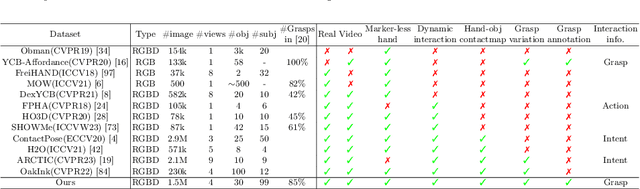
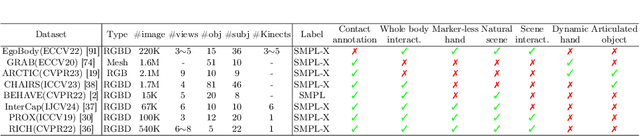
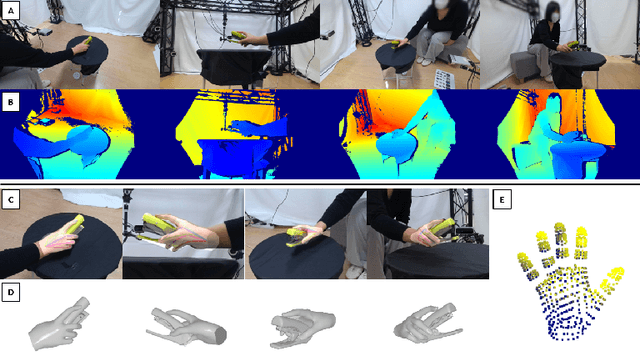
Existing datasets for 3D hand-object interaction are limited either in the data cardinality, data variations in interaction scenarios, or the quality of annotations. In this work, we present a comprehensive new training dataset for hand-object interaction called HOGraspNet. It is the only real dataset that captures full grasp taxonomies, providing grasp annotation and wide intraclass variations. Using grasp taxonomies as atomic actions, their space and time combinatorial can represent complex hand activities around objects. We select 22 rigid objects from the YCB dataset and 8 other compound objects using shape and size taxonomies, ensuring coverage of all hand grasp configurations. The dataset includes diverse hand shapes from 99 participants aged 10 to 74, continuous video frames, and a 1.5M RGB-Depth of sparse frames with annotations. It offers labels for 3D hand and object meshes, 3D keypoints, contact maps, and \emph{grasp labels}. Accurate hand and object 3D meshes are obtained by fitting the hand parametric model (MANO) and the hand implicit function (HALO) to multi-view RGBD frames, with the MoCap system only for objects. Note that HALO fitting does not require any parameter tuning, enabling scalability to the dataset's size with comparable accuracy to MANO. We evaluate HOGraspNet on relevant tasks: grasp classification and 3D hand pose estimation. The result shows performance variations based on grasp type and object class, indicating the potential importance of the interaction space captured by our dataset. The provided data aims at learning universal shape priors or foundation models for 3D hand-object interaction. Our dataset and code are available at https://hograspnet2024.github.io/.
Extending the Reach of First-Order Algorithms for Nonconvex Min-Max Problems with Cohypomonotonicity
Feb 07, 2024We focus on constrained, $L$-smooth, nonconvex-nonconcave min-max problems either satisfying $\rho$-cohypomonotonicity or admitting a solution to the $\rho$-weakly Minty Variational Inequality (MVI), where larger values of the parameter $\rho>0$ correspond to a greater degree of nonconvexity. These problem classes include examples in two player reinforcement learning, interaction dominant min-max problems, and certain synthetic test problems on which classical min-max algorithms fail. It has been conjectured that first-order methods can tolerate value of $\rho$ no larger than $\frac{1}{L}$, but existing results in the literature have stagnated at the tighter requirement $\rho < \frac{1}{2L}$. With a simple argument, we obtain optimal or best-known complexity guarantees with cohypomonotonicity or weak MVI conditions for $\rho < \frac{1}{L}$. The algorithms we analyze are inexact variants of Halpern and Krasnosel'ski\u{\i}-Mann (KM) iterations. We also provide algorithms and complexity guarantees in the stochastic case with the same range on $\rho$. Our main insight for the improvements in the convergence analyses is to harness the recently proposed "conic nonexpansiveness" property of operators. As byproducts, we provide a refined analysis for inexact Halpern iteration and propose a stochastic KM iteration with a multilevel Monte Carlo estimator.
Joint Downlink and Uplink Optimization for RIS-Aided FDD MIMO Communication Systems
Jan 21, 2024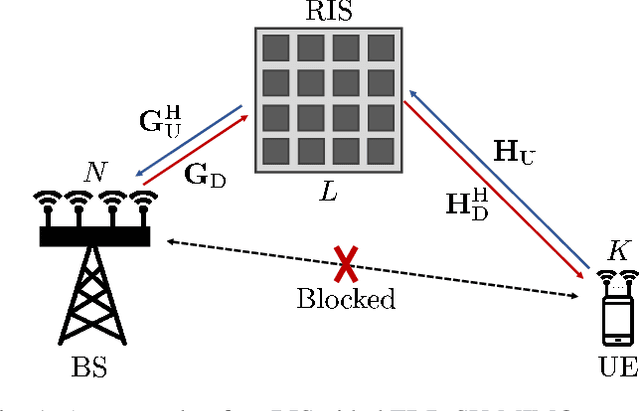
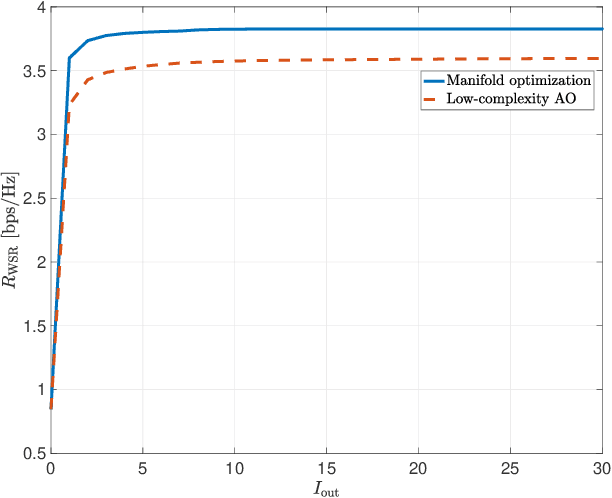
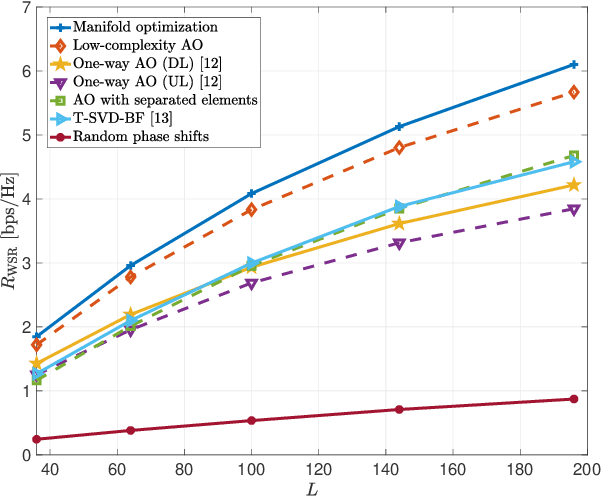
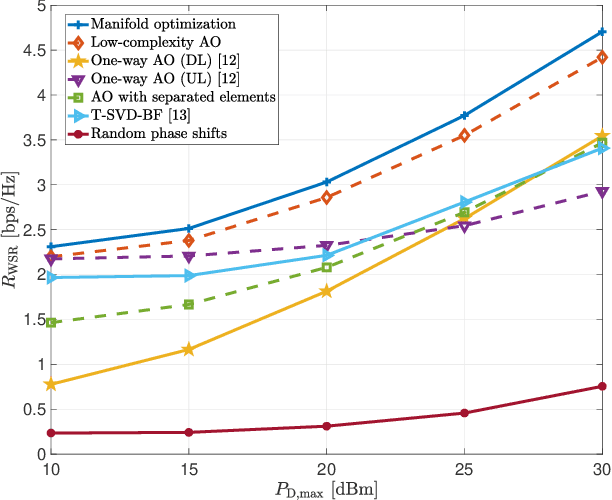
This paper investigates reconfigurable intelligent surface (RIS)-aided frequency division duplexing (FDD) communication systems. Since the downlink and uplink signals are simultaneously transmitted in FDD, the phase shifts at the RIS should be designed to support both transmissions. Considering a single-user multiple-input multiple-output system, we formulate a weighted sum-rate maximization problem to jointly maximize the downlink and uplink system performance. To tackle the non-convex optimization problem, we adopt an alternating optimization (AO) algorithm, in which two phase shift optimization techniques are developed to handle the unit-modulus constraints induced by the reflection coefficients at the RIS. The first technique exploits the manifold optimization-based algorithm, while the second uses a lower-complexity AO approach. Numerical results verify that the proposed techniques rapidly converge to local optima and significantly improve the overall system performance compared to existing benchmark schemes.