 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInt3DNet: Scene-Motion Cross Attention Network for 3D Intention Prediction in Mixed Reality
Mar 09, 2026We propose Int3DNet, a scene-aware network that predicts 3D intention areas directly from scene geometry and head-hand motion cues, enabling robust human intention prediction without explicit object-level perception. In Mixed Reality (MR), intention prediction is critical as it enables the system to anticipate user actions and respond proactively, reducing interaction delays and ensuring seamless user experiences. Our method employs a cross attention fusion of sparse motion cues and scene point clouds, offering a novel approach that directly interprets the user's spatial intention within the scene. We evaluated Int3DNet on MoGaze and CIRCLE datasets, which are public datasets for full-body human-scene interactions, showing consistent performance across time horizons of up to 1500 ms and outperforming the baselines, even in diverse and unseen scenes. Moreover, we demonstrate the usability of proposed method through a demonstration of efficient visual question answering (VQA) based on intention areas. Int3DNet provides reliable 3D intention areas derived from head-hand motion and scene geometry, thus enabling seamless interaction between humans and MR systems through proactive processing of intention areas.
Escaping Spectral Bias without Backpropagation: Fast Implicit Neural Representations with Extreme Learning Machines
Feb 07, 2026Training implicit neural representations (INRs) to capture fine-scale details typically relies on iterative backpropagation and is often hindered by spectral bias when the target exhibits highly non-uniform frequency content. We propose ELM-INR, a backpropagation-free INR that decomposes the domain into overlapping subdomains and fits each local problem using an Extreme Learning Machine (ELM) in closed form, replacing iterative optimization with stable linear least-squares solutions. This design yields fast and numerically robust reconstruction by combining local predictors through a partition of unity. To understand where approximation becomes difficult under fixed local capacity, we analyze the method from a spectral Barron norm perspective, which reveals that global reconstruction error is dominated by regions with high spectral complexity. Building on this insight, we introduce BEAM, an adaptive mesh refinement strategy that balances spectral complexity across subdomains to improve reconstruction quality in capacity-constrained regimes.
SceneLinker: Compositional 3D Scene Generation via Semantic Scene Graph from RGB Sequences
Feb 03, 2026We introduce SceneLinker, a novel framework that generates compositional 3D scenes via semantic scene graph from RGB sequences. To adaptively experience Mixed Reality (MR) content based on each user's space, it is essential to generate a 3D scene that reflects the real-world layout by compactly capturing the semantic cues of the surroundings. Prior works struggled to fully capture the contextual relationship between objects or mainly focused on synthesizing diverse shapes, making it challenging to generate 3D scenes aligned with object arrangements. We address these challenges by designing a graph network with cross-check feature attention for scene graph prediction and constructing a graph-variational autoencoder (graph-VAE), which consists of a joint shape and layout block for 3D scene generation. Experiments on the 3RScan/3DSSG and SG-FRONT datasets demonstrate that our approach outperforms state-of-the-art methods in both quantitative and qualitative evaluations, even in complex indoor environments and under challenging scene graph constraints. Our work enables users to generate consistent 3D spaces from their physical environments via scene graphs, allowing them to create spatial MR content. Project page is https://scenelinker2026.github.io.
PDEfuncta: Spectrally-Aware Neural Representation for PDE Solution Modeling
Jun 15, 2025Scientific machine learning often involves representing complex solution fields that exhibit high-frequency features such as sharp transitions, fine-scale oscillations, and localized structures. While implicit neural representations (INRs) have shown promise for continuous function modeling, capturing such high-frequency behavior remains a challenge-especially when modeling multiple solution fields with a shared network. Prior work addressing spectral bias in INRs has primarily focused on single-instance settings, limiting scalability and generalization. In this work, we propose Global Fourier Modulation (GFM), a novel modulation technique that injects high-frequency information at each layer of the INR through Fourier-based reparameterization. This enables compact and accurate representation of multiple solution fields using low-dimensional latent vectors. Building upon GFM, we introduce PDEfuncta, a meta-learning framework designed to learn multi-modal solution fields and support generalization to new tasks. Through empirical studies on diverse scientific problems, we demonstrate that our method not only improves representational quality but also shows potential for forward and inverse inference tasks without the need for retraining.
Neural Functions for Learning Periodic Signal
Jun 11, 2025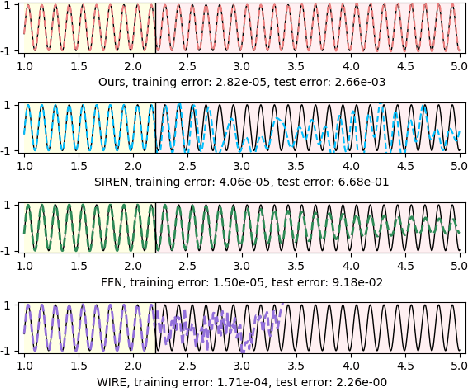
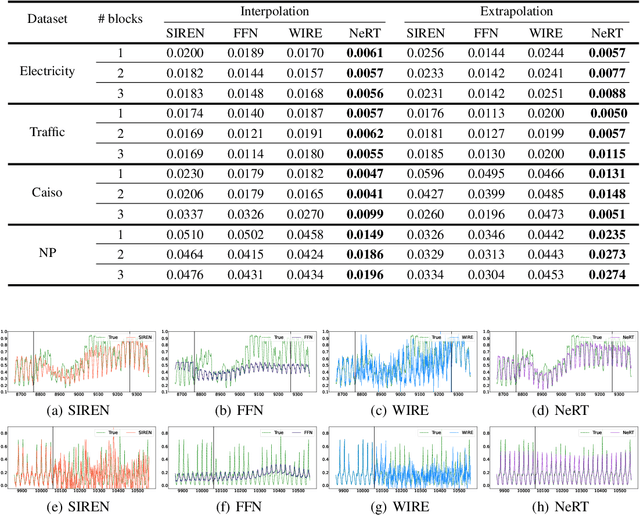
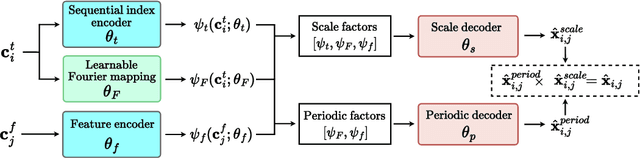
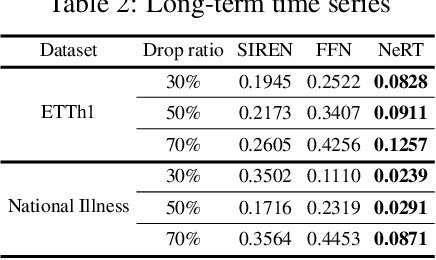
As function approximators, deep neural networks have served as an effective tool to represent various signal types. Recent approaches utilize multi-layer perceptrons (MLPs) to learn a nonlinear mapping from a coordinate to its corresponding signal, facilitating the learning of continuous neural representations from discrete data points. Despite notable successes in learning diverse signal types, coordinate-based MLPs often face issues of overfitting and limited generalizability beyond the training region, resulting in subpar extrapolation performance. This study addresses scenarios where the underlying true signals exhibit periodic properties, either spatially or temporally. We propose a novel network architecture, which extracts periodic patterns from measurements and leverages this information to represent the signal, thereby enhancing generalization and improving extrapolation performance. We demonstrate the efficacy of the proposed method through comprehensive experiments, including the learning of the periodic solutions for differential equations, and time series imputation (interpolation) and forecasting (extrapolation) on real-world datasets.
Unveiling the Potential of Superexpressive Networks in Implicit Neural Representations
Mar 27, 2025In this study, we examine the potential of one of the ``superexpressive'' networks in the context of learning neural functions for representing complex signals and performing machine learning downstream tasks. Our focus is on evaluating their performance on computer vision and scientific machine learning tasks including signal representation/inverse problems and solutions of partial differential equations. Through an empirical investigation in various benchmark tasks, we demonstrate that superexpressive networks, as proposed by [Zhang et al. NeurIPS, 2022], which employ a specialized network structure characterized by having an additional dimension, namely width, depth, and ``height'', can surpass recent implicit neural representations that use highly-specialized nonlinear activation functions.
Tackling Few-Shot Segmentation in Remote Sensing via Inpainting Diffusion Model
Mar 05, 2025Limited data is a common problem in remote sensing due to the high cost of obtaining annotated samples. In the few-shot segmentation task, models are typically trained on base classes with abundant annotations and later adapted to novel classes with limited examples. However, this often necessitates specialized model architectures or complex training strategies. Instead, we propose a simple approach that leverages diffusion models to generate diverse variations of novel-class objects within a given scene, conditioned by the limited examples of the novel classes. By framing the problem as an image inpainting task, we synthesize plausible instances of novel classes under various environments, effectively increasing the number of samples for the novel classes and mitigating overfitting. The generated samples are then assessed using a cosine similarity metric to ensure semantic consistency with the novel classes. Additionally, we employ Segment Anything Model (SAM) to segment the generated samples and obtain precise annotations. By using high-quality synthetic data, we can directly fine-tune off-the-shelf segmentation models. Experimental results demonstrate that our method significantly enhances segmentation performance in low-data regimes, highlighting its potential for real-world remote sensing applications.
MaD-Scientist: AI-based Scientist solving Convection-Diffusion-Reaction Equations Using Massive PINN-Based Prior Data
Oct 09, 2024



Large language models (LLMs), like ChatGPT, have shown that even trained with noisy prior data, they can generalize effectively to new tasks through in-context learning (ICL) and pre-training techniques. Motivated by this, we explore whether a similar approach can be applied to scientific foundation models (SFMs). Our methodology is structured as follows: (i) we collect low-cost physics-informed neural network (PINN)-based approximated prior data in the form of solutions to partial differential equations (PDEs) constructed through an arbitrary linear combination of mathematical dictionaries; (ii) we utilize Transformer architectures with self and cross-attention mechanisms to predict PDE solutions without knowledge of the governing equations in a zero-shot setting; (iii) we provide experimental evidence on the one-dimensional convection-diffusion-reaction equation, which demonstrate that pre-training remains robust even with approximated prior data, with only marginal impacts on test accuracy. Notably, this finding opens the path to pre-training SFMs with realistic, low-cost data instead of (or in conjunction with) numerical high-cost data. These results support the conjecture that SFMs can improve in a manner similar to LLMs, where fully cleaning the vast set of sentences crawled from the Internet is nearly impossible.
FastLRNR and Sparse Physics Informed Backpropagation
Oct 05, 2024
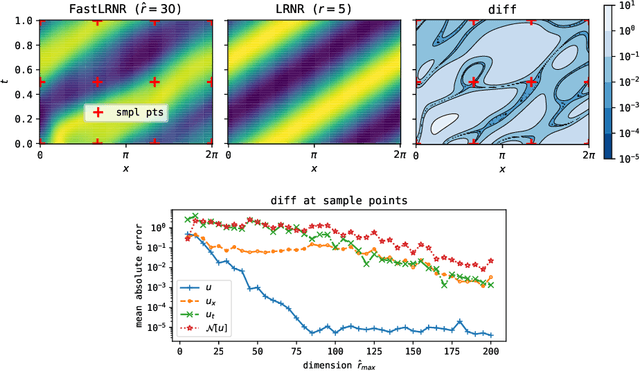
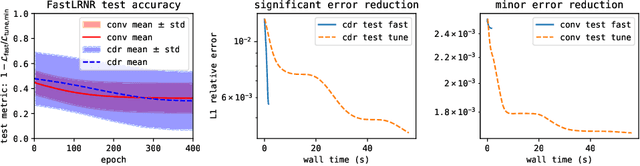
We introduce Sparse Physics Informed Backpropagation (SPInProp), a new class of methods for accelerating backpropagation for a specialized neural network architecture called Low Rank Neural Representation (LRNR). The approach exploits the low rank structure within LRNR and constructs a reduced neural network approximation that is much smaller in size. We call the smaller network FastLRNR. We show that backpropagation of FastLRNR can be substituted for that of LRNR, enabling a significant reduction in complexity. We apply SPInProp to a physics informed neural networks framework and demonstrate how the solution of parametrized partial differential equations is accelerated.
Dense Hand-Object(HO) GraspNet with Full Grasping Taxonomy and Dynamics
Sep 06, 2024
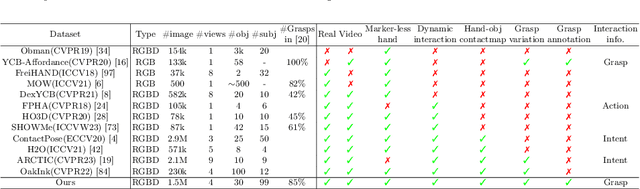
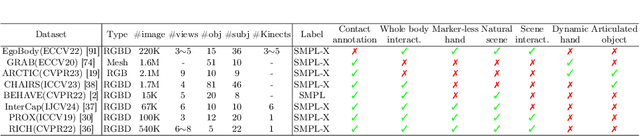
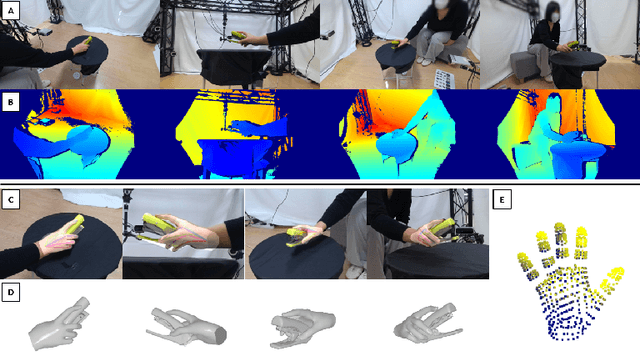
Existing datasets for 3D hand-object interaction are limited either in the data cardinality, data variations in interaction scenarios, or the quality of annotations. In this work, we present a comprehensive new training dataset for hand-object interaction called HOGraspNet. It is the only real dataset that captures full grasp taxonomies, providing grasp annotation and wide intraclass variations. Using grasp taxonomies as atomic actions, their space and time combinatorial can represent complex hand activities around objects. We select 22 rigid objects from the YCB dataset and 8 other compound objects using shape and size taxonomies, ensuring coverage of all hand grasp configurations. The dataset includes diverse hand shapes from 99 participants aged 10 to 74, continuous video frames, and a 1.5M RGB-Depth of sparse frames with annotations. It offers labels for 3D hand and object meshes, 3D keypoints, contact maps, and \emph{grasp labels}. Accurate hand and object 3D meshes are obtained by fitting the hand parametric model (MANO) and the hand implicit function (HALO) to multi-view RGBD frames, with the MoCap system only for objects. Note that HALO fitting does not require any parameter tuning, enabling scalability to the dataset's size with comparable accuracy to MANO. We evaluate HOGraspNet on relevant tasks: grasp classification and 3D hand pose estimation. The result shows performance variations based on grasp type and object class, indicating the potential importance of the interaction space captured by our dataset. The provided data aims at learning universal shape priors or foundation models for 3D hand-object interaction. Our dataset and code are available at https://hograspnet2024.github.io/.