 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural ODE Transformers: Analyzing Internal Dynamics and Adaptive Fine-tuning
Mar 03, 2025Recent advancements in large language models (LLMs) based on transformer architectures have sparked significant interest in understanding their inner workings. In this paper, we introduce a novel approach to modeling transformer architectures using highly flexible non-autonomous neural ordinary differential equations (ODEs). Our proposed model parameterizes all weights of attention and feed-forward blocks through neural networks, expressing these weights as functions of a continuous layer index. Through spectral analysis of the model's dynamics, we uncover an increase in eigenvalue magnitude that challenges the weight-sharing assumption prevalent in existing theoretical studies. We also leverage the Lyapunov exponent to examine token-level sensitivity, enhancing model interpretability. Our neural ODE transformer demonstrates performance comparable to or better than vanilla transformers across various configurations and datasets, while offering flexible fine-tuning capabilities that can adapt to different architectural constraints.
Parameterized Physics-informed Neural Networks for Parameterized PDEs
Aug 18, 2024



Complex physical systems are often described by partial differential equations (PDEs) that depend on parameters such as the Reynolds number in fluid mechanics. In applications such as design optimization or uncertainty quantification, solutions of those PDEs need to be evaluated at numerous points in the parameter space. While physics-informed neural networks (PINNs) have emerged as a new strong competitor as a surrogate, their usage in this scenario remains underexplored due to the inherent need for repetitive and time-consuming training. In this paper, we address this problem by proposing a novel extension, parameterized physics-informed neural networks (P$^2$INNs). P$^2$INNs enable modeling the solutions of parameterized PDEs via explicitly encoding a latent representation of PDE parameters. With the extensive empirical evaluation, we demonstrate that P$^2$INNs outperform the baselines both in accuracy and parameter efficiency on benchmark 1D and 2D parameterized PDEs and are also effective in overcoming the known "failure modes".
PAC-FNO: Parallel-Structured All-Component Fourier Neural Operators for Recognizing Low-Quality Images
Feb 20, 2024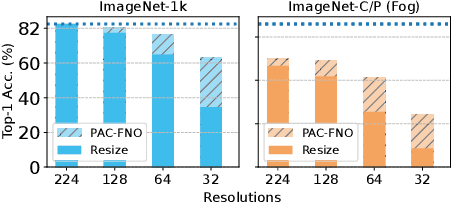
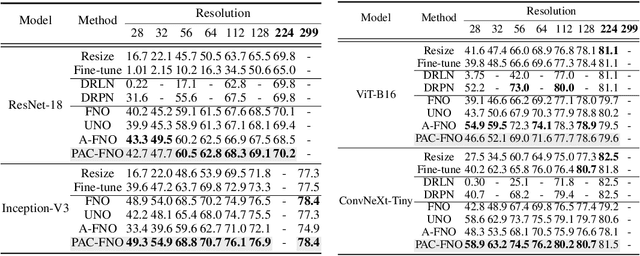
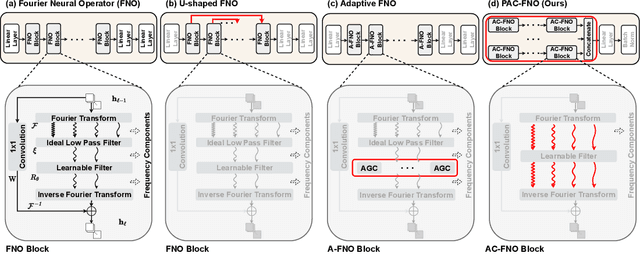
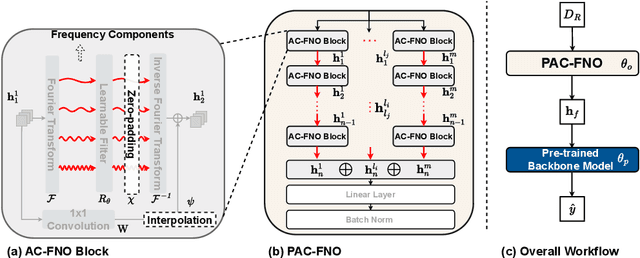
A standard practice in developing image recognition models is to train a model on a specific image resolution and then deploy it. However, in real-world inference, models often encounter images different from the training sets in resolution and/or subject to natural variations such as weather changes, noise types and compression artifacts. While traditional solutions involve training multiple models for different resolutions or input variations, these methods are computationally expensive and thus do not scale in practice. To this end, we propose a novel neural network model, parallel-structured and all-component Fourier neural operator (PAC-FNO), that addresses the problem. Unlike conventional feed-forward neural networks, PAC-FNO operates in the frequency domain, allowing it to handle images of varying resolutions within a single model. We also propose a two-stage algorithm for training PAC-FNO with a minimal modification to the original, downstream model. Moreover, the proposed PAC-FNO is ready to work with existing image recognition models. Extensively evaluating methods with seven image recognition benchmarks, we show that the proposed PAC-FNO improves the performance of existing baseline models on images with various resolutions by up to 77.1% and various types of natural variations in the images at inference.
Operator-learning-inspired Modeling of Neural Ordinary Differential Equations
Dec 16, 2023Neural ordinary differential equations (NODEs), one of the most influential works of the differential equation-based deep learning, are to continuously generalize residual networks and opened a new field. They are currently utilized for various downstream tasks, e.g., image classification, time series classification, image generation, etc. Its key part is how to model the time-derivative of the hidden state, denoted dh(t)/dt. People have habitually used conventional neural network architectures, e.g., fully-connected layers followed by non-linear activations. In this paper, however, we present a neural operator-based method to define the time-derivative term. Neural operators were initially proposed to model the differential operator of partial differential equations (PDEs). Since the time-derivative of NODEs can be understood as a special type of the differential operator, our proposed method, called branched Fourier neural operator (BFNO), makes sense. In our experiments with general downstream tasks, our method significantly outperforms existing methods.
SigFormer: Signature Transformers for Deep Hedging
Oct 20, 2023Deep hedging is a promising direction in quantitative finance, incorporating models and techniques from deep learning research. While giving excellent hedging strategies, models inherently requires careful treatment in designing architectures for neural networks. To mitigate such difficulties, we introduce SigFormer, a novel deep learning model that combines the power of path signatures and transformers to handle sequential data, particularly in cases with irregularities. Path signatures effectively capture complex data patterns, while transformers provide superior sequential attention. Our proposed model is empirically compared to existing methods on synthetic data, showcasing faster learning and enhanced robustness, especially in the presence of irregular underlying price data. Additionally, we validate our model performance through a real-world backtest on hedging the SP 500 index, demonstrating positive outcomes.
Time Series Forecasting with Hypernetworks Generating Parameters in Advance
Nov 22, 2022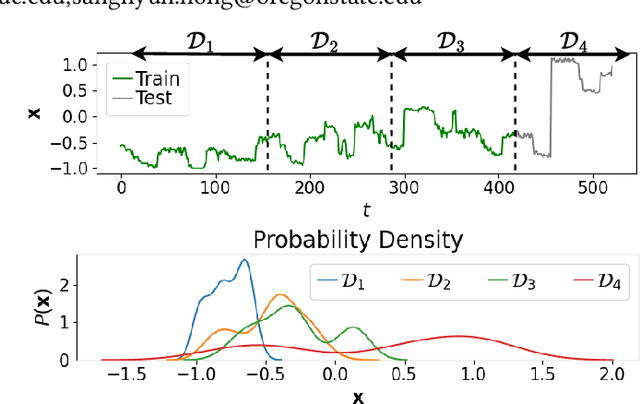

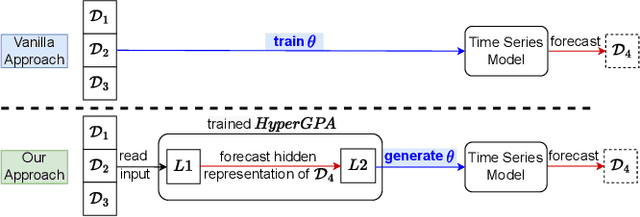

Forecasting future outcomes from recent time series data is not easy, especially when the future data are different from the past (i.e. time series are under temporal drifts). Existing approaches show limited performances under data drifts, and we identify the main reason: It takes time for a model to collect sufficient training data and adjust its parameters for complicated temporal patterns whenever the underlying dynamics change. To address this issue, we study a new approach; instead of adjusting model parameters (by continuously re-training a model on new data), we build a hypernetwork that generates other target models' parameters expected to perform well on the future data. Therefore, we can adjust the model parameters beforehand (if the hypernetwork is correct). We conduct extensive experiments with 6 target models, 6 baselines, and 4 datasets, and show that our HyperGPA outperforms other baselines.
Climate Modeling with Neural Diffusion Equations
Nov 11, 2021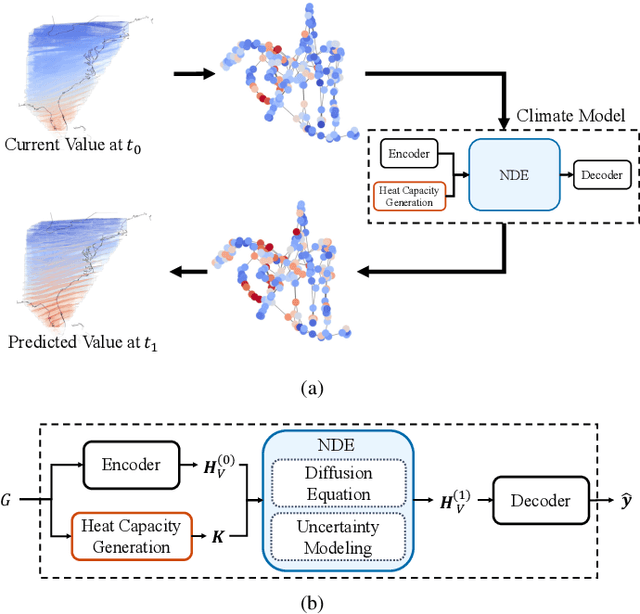

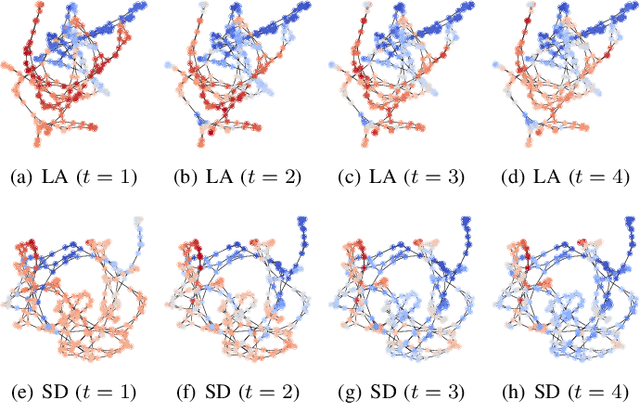
Owing to the remarkable development of deep learning technology, there have been a series of efforts to build deep learning-based climate models. Whereas most of them utilize recurrent neural networks and/or graph neural networks, we design a novel climate model based on the two concepts, the neural ordinary differential equation (NODE) and the diffusion equation. Many physical processes involving a Brownian motion of particles can be described by the diffusion equation and as a result, it is widely used for modeling climate. On the other hand, neural ordinary differential equations (NODEs) are to learn a latent governing equation of ODE from data. In our presented method, we combine them into a single framework and propose a concept, called neural diffusion equation (NDE). Our NDE, equipped with the diffusion equation and one more additional neural network to model inherent uncertainty, can learn an appropriate latent governing equation that best describes a given climate dataset. In our experiments with two real-world and one synthetic datasets and eleven baselines, our method consistently outperforms existing baselines by non-trivial margins.
DPM: A Novel Training Method for Physics-Informed Neural Networks in Extrapolation
Dec 04, 2020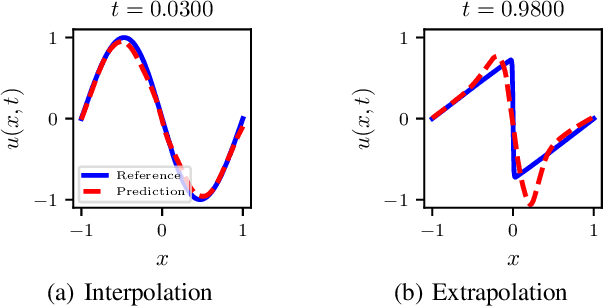

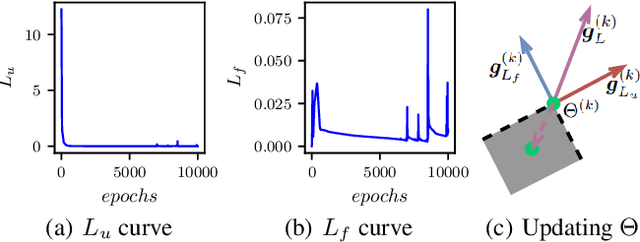
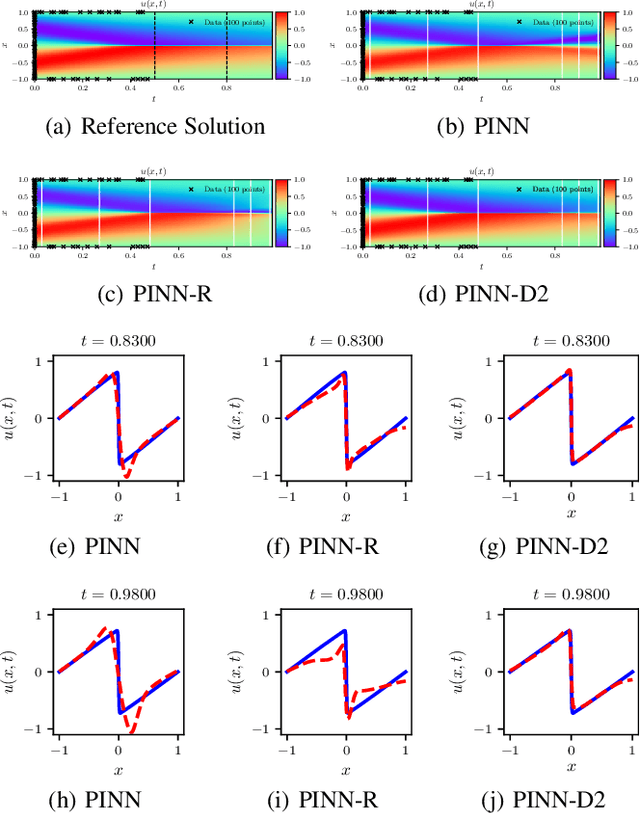
We present a method for learning dynamics of complex physical processes described by time-dependent nonlinear partial differential equations (PDEs). Our particular interest lies in extrapolating solutions in time beyond the range of temporal domain used in training. Our choice for a baseline method is physics-informed neural network (PINN) [Raissi et al., J. Comput. Phys., 378:686--707, 2019] because the method parameterizes not only the solutions but also the equations that describe the dynamics of physical processes. We demonstrate that PINN performs poorly on extrapolation tasks in many benchmark problems. To address this, we propose a novel method for better training PINN and demonstrate that our newly enhanced PINNs can accurately extrapolate solutions in time. Our method shows up to 72% smaller errors than existing methods in terms of the standard L2-norm metric.
Solving Large-Scale 0-1 Knapsack Problems and its Application to Point Cloud Resampling
Jun 11, 2019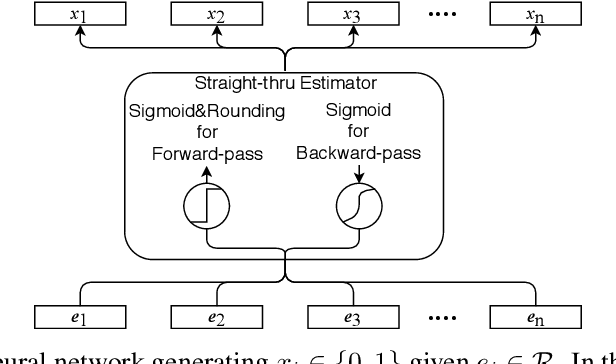
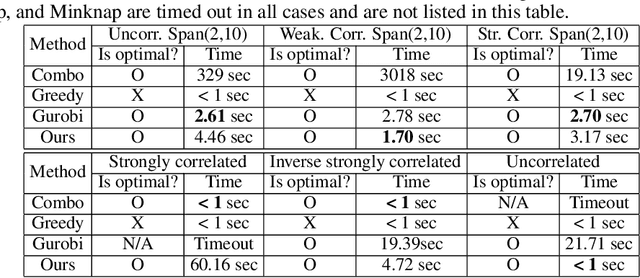
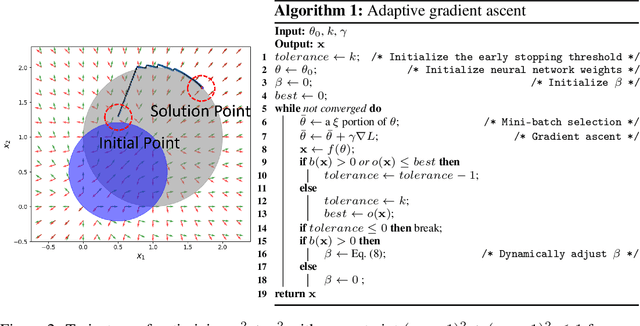

0-1 knapsack is of fundamental importance in computer science, business, operations research, etc. In this paper, we present a deep learning technique-based method to solve large-scale 0-1 knapsack problems where the number of products (items) is large and/or the values of products are not necessarily predetermined but decided by an external value assignment function during the optimization process. Our solution is greatly inspired by the method of Lagrange multiplier and some recent adoptions of game theory to deep learning. After formally defining our proposed method based on them, we develop an adaptive gradient ascent method to stabilize its optimization process. In our experiments, the presented method solves all the large-scale benchmark KP instances in a minute whereas existing methods show fluctuating runtime. We also show that our method can be used for other applications, including but not limited to the point cloud resampling.