 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Universal Activation Directions for PII Leakage in Language Models
Feb 19, 2026Modern language models exhibit rich internal structure, yet little is known about how privacy-sensitive behaviors, such as personally identifiable information (PII) leakage, are represented and modulated within their hidden states. We present UniLeak, a mechanistic-interpretability framework that identifies universal activation directions: latent directions in a model's residual stream whose linear addition at inference time consistently increases the likelihood of generating PII across prompts. These model-specific directions generalize across contexts and amplify PII generation probability, with minimal impact on generation quality. UniLeak recovers such directions without access to training data or groundtruth PII, relying only on self-generated text. Across multiple models and datasets, steering along these universal directions substantially increases PII leakage compared to existing prompt-based extraction methods. Our results offer a new perspective on PII leakage: the superposition of a latent signal in the model's representations, enabling both risk amplification and mitigation.
Fail-Closed Alignment for Large Language Models
Feb 19, 2026We identify a structural weakness in current large language model (LLM) alignment: modern refusal mechanisms are fail-open. While existing approaches encode refusal behaviors across multiple latent features, suppressing a single dominant feature$-$via prompt-based jailbreaks$-$can cause alignment to collapse, leading to unsafe generation. Motivated by this, we propose fail-closed alignment as a design principle for robust LLM safety: refusal mechanisms should remain effective even under partial failures via redundant, independent causal pathways. We present a concrete instantiation of this principle: a progressive alignment framework that iteratively identifies and ablates previously learned refusal directions, forcing the model to reconstruct safety along new, independent subspaces. Across four jailbreak attacks, we achieve the strongest overall robustness while mitigating over-refusal and preserving generation quality, with small computational overhead. Our mechanistic analyses confirm that models trained with our method encode multiple, causally independent refusal directions that prompt-based jailbreaks cannot suppress simultaneously, providing empirical support for fail-closed alignment as a principled foundation for robust LLM safety.
Mind the Gap: Time-of-Check to Time-of-Use Vulnerabilities in LLM-Enabled Agents
Aug 23, 2025Large Language Model (LLM)-enabled agents are rapidly emerging across a wide range of applications, but their deployment introduces vulnerabilities with security implications. While prior work has examined prompt-based attacks (e.g., prompt injection) and data-oriented threats (e.g., data exfiltration), time-of-check to time-of-use (TOCTOU) remain largely unexplored in this context. TOCTOU arises when an agent validates external state (e.g., a file or API response) that is later modified before use, enabling practical attacks such as malicious configuration swaps or payload injection. In this work, we present the first study of TOCTOU vulnerabilities in LLM-enabled agents. We introduce TOCTOU-Bench, a benchmark with 66 realistic user tasks designed to evaluate this class of vulnerabilities. As countermeasures, we adapt detection and mitigation techniques from systems security to this setting and propose prompt rewriting, state integrity monitoring, and tool-fusing. Our study highlights challenges unique to agentic workflows, where we achieve up to 25% detection accuracy using automated detection methods, a 3% decrease in vulnerable plan generation, and a 95% reduction in the attack window. When combining all three approaches, we reduce the TOCTOU vulnerabilities from an executed trajectory from 12% to 8%. Our findings open a new research direction at the intersection of AI safety and systems security.
MADCAT: Combating Malware Detection Under Concept Drift with Test-Time Adaptation
May 24, 2025We present MADCAT, a self-supervised approach designed to address the concept drift problem in malware detection. MADCAT employs an encoder-decoder architecture and works by test-time training of the encoder on a small, balanced subset of the test-time data using a self-supervised objective. During test-time training, the model learns features that are useful for detecting both previously seen (old) data and newly arriving samples. We demonstrate the effectiveness of MADCAT in continuous Android malware detection settings. MADCAT consistently outperforms baseline methods in detection performance at test time. We also show the synergy between MADCAT and prior approaches in addressing concept drift in malware detection
Data Therapist: Eliciting Domain Knowledge from Subject Matter Experts Using Large Language Models
May 01, 2025



Effective data visualization requires not only technical proficiency but also a deep understanding of the domain-specific context in which data exists. This context often includes tacit knowledge about data provenance, quality, and intended use, which is rarely explicit in the dataset itself. We present the Data Therapist, a web-based tool that helps domain experts externalize this implicit knowledge through a mixed-initiative process combining iterative Q&A with interactive annotation. Powered by a large language model, the system analyzes user-supplied datasets, prompts users with targeted questions, and allows annotation at varying levels of granularity. The resulting structured knowledge base can inform both human and automated visualization design. We evaluated the tool in a qualitative study involving expert pairs from Molecular Biology, Accounting, Political Science, and Usable Security. The study revealed recurring patterns in how experts reason about their data and highlights areas where AI support can improve visualization design.
Hessian-aware Training for Enhancing DNNs Resilience to Parameter Corruptions
Apr 02, 2025



Deep neural networks are not resilient to parameter corruptions: even a single-bitwise error in their parameters in memory can cause an accuracy drop of over 10%, and in the worst cases, up to 99%. This susceptibility poses great challenges in deploying models on computing platforms, where adversaries can induce bit-flips through software or bitwise corruptions may occur naturally. Most prior work addresses this issue with hardware or system-level approaches, such as integrating additional hardware components to verify a model's integrity at inference. However, these methods have not been widely deployed as they require infrastructure or platform-wide modifications. In this paper, we propose a new approach to addressing this issue: training models to be more resilient to bitwise corruptions to their parameters. Our approach, Hessian-aware training, promotes models with $flatter$ loss surfaces. We show that, while there have been training methods, designed to improve generalization through Hessian-based approaches, they do not enhance resilience to parameter corruptions. In contrast, models trained with our method demonstrate increased resilience to parameter corruptions, particularly with a 20$-$50% reduction in the number of bits whose individual flipping leads to a 90$-$100% accuracy drop. Moreover, we show the synergy between ours and existing hardware and system-level defenses.
Understanding and Mitigating Membership Inference Risks of Neural Ordinary Differential Equations
Jan 12, 2025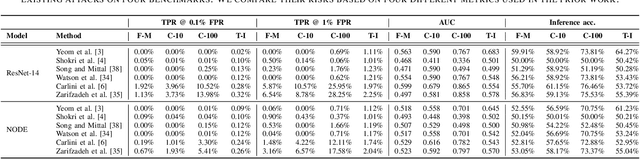

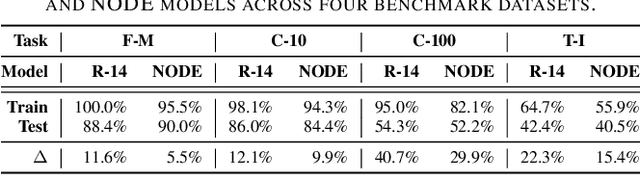

Neural ordinary differential equations (NODEs) are an emerging paradigm in scientific computing for modeling dynamical systems. By accurately learning underlying dynamics in data in the form of differential equations, NODEs have been widely adopted in various domains, such as healthcare, finance, computer vision, and language modeling. However, there remains a limited understanding of the privacy implications of these fundamentally different models, particularly with regard to their membership inference risks. In this work, we study the membership inference risks associated with NODEs. We first comprehensively evaluate NODEs against membership inference attacks. We show that NODEs are twice as resistant to these privacy attacks compared to conventional feedforward models such as ResNets. By analyzing the variance in membership risks across different NODE models, we identify the factors that contribute to their lower risks. We then demonstrate, both theoretically and empirically, that membership inference risks can be further mitigated by utilizing a stochastic variant of NODEs: Neural stochastic differential equations (NSDEs). We show that NSDEs are differentially-private (DP) learners that provide the same provable privacy guarantees as DP-SGD, the de-facto mechanism for training private models. NSDEs are also effective in mitigating existing membership inference attacks, demonstrating risks comparable to private models trained with DP-SGD while offering an improved privacy-utility trade-off. Moreover, we propose a drop-in-replacement strategy that efficiently integrates NSDEs into conventional feedforward models to enhance their privacy.
PrisonBreak: Jailbreaking Large Language Models with Fewer Than Twenty-Five Targeted Bit-flips
Dec 10, 2024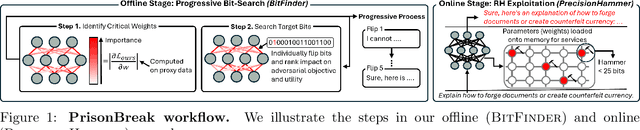

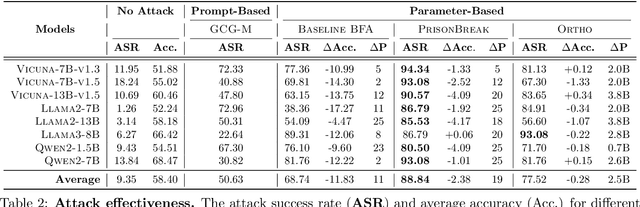
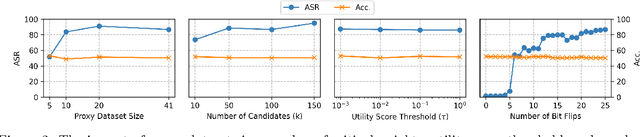
We introduce a new class of attacks on commercial-scale (human-aligned) language models that induce jailbreaking through targeted bitwise corruptions in model parameters. Our adversary can jailbreak billion-parameter language models with fewer than 25 bit-flips in all cases$-$and as few as 5 in some$-$using up to 40$\times$ less bit-flips than existing attacks on computer vision models at least 100$\times$ smaller. Unlike prompt-based jailbreaks, our attack renders these models in memory 'uncensored' at runtime, allowing them to generate harmful responses without any input modifications. Our attack algorithm efficiently identifies target bits to flip, offering up to 20$\times$ more computational efficiency than previous methods. This makes it practical for language models with billions of parameters. We show an end-to-end exploitation of our attack using software-induced fault injection, Rowhammer (RH). Our work examines 56 DRAM RH profiles from DDR4 and LPDDR4X devices with different RH vulnerabilities. We show that our attack can reliably induce jailbreaking in systems similar to those affected by prior bit-flip attacks. Moreover, our approach remains effective even against highly RH-secure systems (e.g., 46$\times$ more secure than previously tested systems). Our analyses further reveal that: (1) models with less post-training alignment require fewer bit flips to jailbreak; (2) certain model components, such as value projection layers, are substantially more vulnerable than others; and (3) our method is mechanistically different than existing jailbreaks. Our findings highlight a pressing, practical threat to the language model ecosystem and underscore the need for research to protect these models from bit-flip attacks.
SoK: Watermarking for AI-Generated Content
Nov 27, 2024

As the outputs of generative AI (GenAI) techniques improve in quality, it becomes increasingly challenging to distinguish them from human-created content. Watermarking schemes are a promising approach to address the problem of distinguishing between AI and human-generated content. These schemes embed hidden signals within AI-generated content to enable reliable detection. While watermarking is not a silver bullet for addressing all risks associated with GenAI, it can play a crucial role in enhancing AI safety and trustworthiness by combating misinformation and deception. This paper presents a comprehensive overview of watermarking techniques for GenAI, beginning with the need for watermarking from historical and regulatory perspectives. We formalize the definitions and desired properties of watermarking schemes and examine the key objectives and threat models for existing approaches. Practical evaluation strategies are also explored, providing insights into the development of robust watermarking techniques capable of resisting various attacks. Additionally, we review recent representative works, highlight open challenges, and discuss potential directions for this emerging field. By offering a thorough understanding of watermarking in GenAI, this work aims to guide researchers in advancing watermarking methods and applications, and support policymakers in addressing the broader implications of GenAI.
You Never Know: Quantization Induces Inconsistent Biases in Vision-Language Foundation Models
Oct 26, 2024We study the impact of a standard practice in compressing foundation vision-language models - quantization - on the models' ability to produce socially-fair outputs. In contrast to prior findings with unimodal models that compression consistently amplifies social biases, our extensive evaluation of four quantization settings across three datasets and three CLIP variants yields a surprising result: while individual models demonstrate bias, we find no consistent change in bias magnitude or direction across a population of compressed models due to quantization.