 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypassing Prompt Guards in Production with Controlled-Release Prompting
Oct 02, 2025As large language models (LLMs) advance, ensuring AI safety and alignment is paramount. One popular approach is prompt guards, lightweight mechanisms designed to filter malicious queries while being easy to implement and update. In this work, we introduce a new attack that circumvents such prompt guards, highlighting their limitations. Our method consistently jailbreaks production models while maintaining response quality, even under the highly protected chat interfaces of Google Gemini (2.5 Flash/Pro), DeepSeek Chat (DeepThink), Grok (3), and Mistral Le Chat (Magistral). The attack exploits a resource asymmetry between the prompt guard and the main LLM, encoding a jailbreak prompt that lightweight guards cannot decode but the main model can. This reveals an attack surface inherent to lightweight prompt guards in modern LLM architectures and underscores the need to shift defenses from blocking malicious inputs to preventing malicious outputs. We additionally identify other critical alignment issues, such as copyrighted data extraction, training data extraction, and malicious response leakage during thinking.
On the Difficulty of Constructing a Robust and Publicly-Detectable Watermark
Feb 07, 2025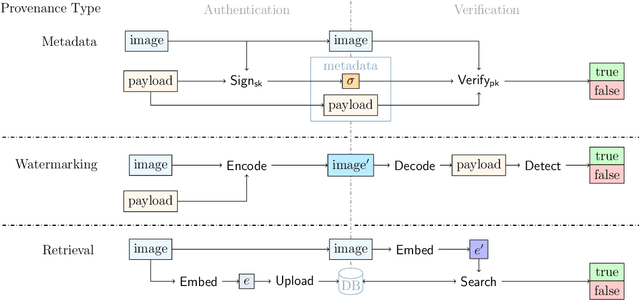
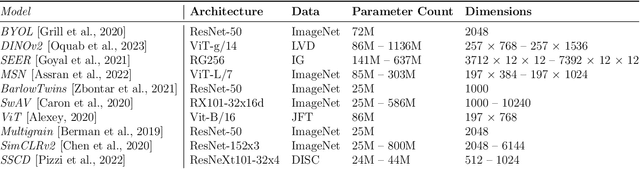
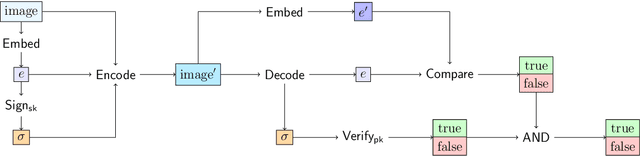
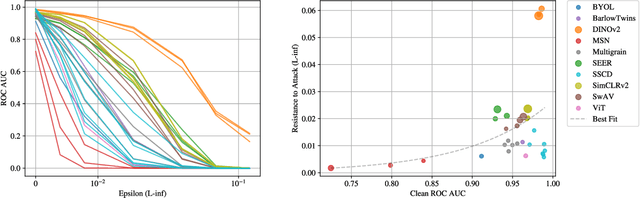
This work investigates the theoretical boundaries of creating publicly-detectable schemes to enable the provenance of watermarked imagery. Metadata-based approaches like C2PA provide unforgeability and public-detectability. ML techniques offer robust retrieval and watermarking. However, no existing scheme combines robustness, unforgeability, and public-detectability. In this work, we formally define such a scheme and establish its existence. Although theoretically possible, we find that at present, it is intractable to build certain components of our scheme without a leap in deep learning capabilities. We analyze these limitations and propose research directions that need to be addressed before we can practically realize robust and publicly-verifiable provenance.
SoK: Watermarking for AI-Generated Content
Nov 27, 2024

As the outputs of generative AI (GenAI) techniques improve in quality, it becomes increasingly challenging to distinguish them from human-created content. Watermarking schemes are a promising approach to address the problem of distinguishing between AI and human-generated content. These schemes embed hidden signals within AI-generated content to enable reliable detection. While watermarking is not a silver bullet for addressing all risks associated with GenAI, it can play a crucial role in enhancing AI safety and trustworthiness by combating misinformation and deception. This paper presents a comprehensive overview of watermarking techniques for GenAI, beginning with the need for watermarking from historical and regulatory perspectives. We formalize the definitions and desired properties of watermarking schemes and examine the key objectives and threat models for existing approaches. Practical evaluation strategies are also explored, providing insights into the development of robust watermarking techniques capable of resisting various attacks. Additionally, we review recent representative works, highlight open challenges, and discuss potential directions for this emerging field. By offering a thorough understanding of watermarking in GenAI, this work aims to guide researchers in advancing watermarking methods and applications, and support policymakers in addressing the broader implications of GenAI.
Publicly Detectable Watermarking for Language Models
Oct 27, 2023We construct the first provable watermarking scheme for language models with public detectability or verifiability: we use a private key for watermarking and a public key for watermark detection. Our protocol is the first watermarking scheme that does not embed a statistical signal in generated text. Rather, we directly embed a publicly-verifiable cryptographic signature using a form of rejection sampling. We show that our construction meets strong formal security guarantees and preserves many desirable properties found in schemes in the private-key watermarking setting. In particular, our watermarking scheme retains distortion-freeness and model agnosticity. We implement our scheme and make empirical measurements over open models in the 7B parameter range. Our experiments suggest that our watermarking scheme meets our formal claims while preserving text quality.