 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to sketch a learning algorithm
Apr 08, 2026How does the choice of training data influence an AI model? This question is of central importance to interpretability, privacy, and basic science. At its core is the data deletion problem: after a reasonable amount of precomputation, quickly predict how the model would behave in a given situation if a given subset of training data had been excluded from the learning algorithm. We present a data deletion scheme capable of predicting model outputs with vanishing error $\varepsilon$ in the deep learning setting. Our precomputation and prediction algorithms are only $\mathrm{poly}(1/\varepsilon)$ factors slower than regular training and inference, respectively. The storage requirements are those of $\mathrm{poly}(1/\varepsilon)$ models. Our proof is based on an assumption that we call "stability." In contrast to the assumptions made by prior work, stability appears to be fully compatible with learning powerful AI models. In support of this, we show that stability is satisfied in a minimal set of experiments with microgpt. Our code is available at https://github.com/SamSpo1/microgpt-sketch. At a technical level, our work is based on a new method for locally sketching an arithmetic circuit by computing higher-order derivatives in random complex directions. Forward-mode automatic differentiation allows cheap computation of these derivatives.
SoK: Watermarking for AI-Generated Content
Nov 27, 2024

As the outputs of generative AI (GenAI) techniques improve in quality, it becomes increasingly challenging to distinguish them from human-created content. Watermarking schemes are a promising approach to address the problem of distinguishing between AI and human-generated content. These schemes embed hidden signals within AI-generated content to enable reliable detection. While watermarking is not a silver bullet for addressing all risks associated with GenAI, it can play a crucial role in enhancing AI safety and trustworthiness by combating misinformation and deception. This paper presents a comprehensive overview of watermarking techniques for GenAI, beginning with the need for watermarking from historical and regulatory perspectives. We formalize the definitions and desired properties of watermarking schemes and examine the key objectives and threat models for existing approaches. Practical evaluation strategies are also explored, providing insights into the development of robust watermarking techniques capable of resisting various attacks. Additionally, we review recent representative works, highlight open challenges, and discuss potential directions for this emerging field. By offering a thorough understanding of watermarking in GenAI, this work aims to guide researchers in advancing watermarking methods and applications, and support policymakers in addressing the broader implications of GenAI.
Provably Robust Watermarks for Open-Source Language Models
Oct 24, 2024

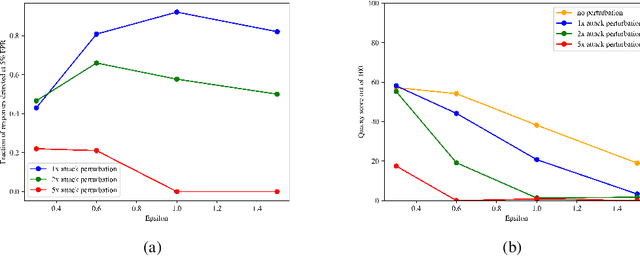

The recent explosion of high-quality language models has necessitated new methods for identifying AI-generated text. Watermarking is a leading solution and could prove to be an essential tool in the age of generative AI. Existing approaches embed watermarks at inference and crucially rely on the large language model (LLM) specification and parameters being secret, which makes them inapplicable to the open-source setting. In this work, we introduce the first watermarking scheme for open-source LLMs. Our scheme works by modifying the parameters of the model, but the watermark can be detected from just the outputs of the model. Perhaps surprisingly, we prove that our watermarks are unremovable under certain assumptions about the adversary's knowledge. To demonstrate the behavior of our construction under concrete parameter instantiations, we present experimental results with OPT-6.7B and OPT-1.3B. We demonstrate robustness to both token substitution and perturbation of the model parameters. We find that the stronger of these attacks, the model-perturbation attack, requires deteriorating the quality score to 0 out of 100 in order to bring the detection rate down to 50%.
An undetectable watermark for generative image models
Oct 09, 2024

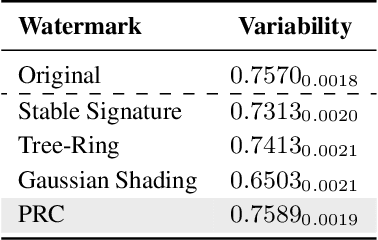

We present the first undetectable watermarking scheme for generative image models. Undetectability ensures that no efficient adversary can distinguish between watermarked and un-watermarked images, even after making many adaptive queries. In particular, an undetectable watermark does not degrade image quality under any efficiently computable metric. Our scheme works by selecting the initial latents of a diffusion model using a pseudorandom error-correcting code (Christ and Gunn, 2024), a strategy which guarantees undetectability and robustness. We experimentally demonstrate that our watermarks are quality-preserving and robust using Stable Diffusion 2.1. Our experiments verify that, in contrast to every prior scheme we tested, our watermark does not degrade image quality. Our experiments also demonstrate robustness: existing watermark removal attacks fail to remove our watermark from images without significantly degrading the quality of the images. Finally, we find that we can robustly encode 512 bits in our watermark, and up to 2500 bits when the images are not subjected to watermark removal attacks. Our code is available at https://github.com/XuandongZhao/PRC-Watermark.
Pseudorandom Error-Correcting Codes
Feb 14, 2024We construct pseudorandom error-correcting codes (or simply pseudorandom codes), which are error-correcting codes with the property that any polynomial number of codewords are pseudorandom to any computationally-bounded adversary. Efficient decoding of corrupted codewords is possible with the help of a decoding key. We build pseudorandom codes that are robust to substitution and deletion errors, where pseudorandomness rests on standard cryptographic assumptions. Specifically, pseudorandomness is based on either $2^{O(\sqrt{n})}$-hardness of LPN, or polynomial hardness of LPN and the planted XOR problem at low density. As our primary application of pseudorandom codes, we present an undetectable watermarking scheme for outputs of language models that is robust to cropping and a constant rate of random substitutions and deletions. The watermark is undetectable in the sense that any number of samples of watermarked text are computationally indistinguishable from text output by the original model. This is the first undetectable watermarking scheme that can tolerate a constant rate of errors. Our second application is to steganography, where a secret message is hidden in innocent-looking content. We present a constant-rate stateless steganography scheme with robustness to a constant rate of substitutions. Ours is the first stateless steganography scheme with provable steganographic security and any robustness to errors.