 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Robust Watermarks for Open-Source Language Models
Oct 24, 2024

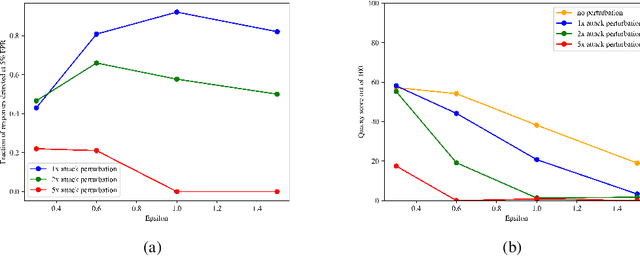

The recent explosion of high-quality language models has necessitated new methods for identifying AI-generated text. Watermarking is a leading solution and could prove to be an essential tool in the age of generative AI. Existing approaches embed watermarks at inference and crucially rely on the large language model (LLM) specification and parameters being secret, which makes them inapplicable to the open-source setting. In this work, we introduce the first watermarking scheme for open-source LLMs. Our scheme works by modifying the parameters of the model, but the watermark can be detected from just the outputs of the model. Perhaps surprisingly, we prove that our watermarks are unremovable under certain assumptions about the adversary's knowledge. To demonstrate the behavior of our construction under concrete parameter instantiations, we present experimental results with OPT-6.7B and OPT-1.3B. We demonstrate robustness to both token substitution and perturbation of the model parameters. We find that the stronger of these attacks, the model-perturbation attack, requires deteriorating the quality score to 0 out of 100 in order to bring the detection rate down to 50%.
Advances and Open Problems in Federated Learning
Dec 10, 2019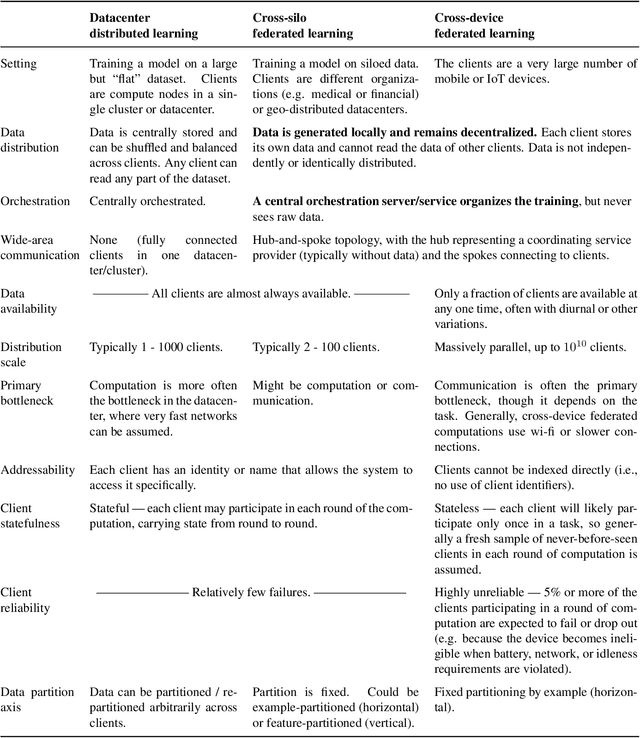
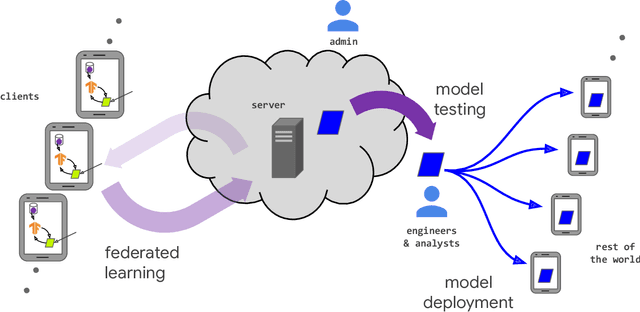
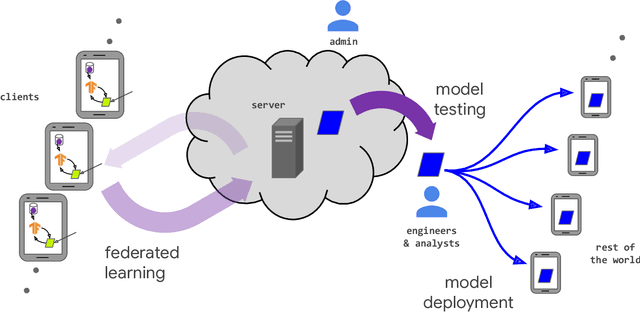

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.