 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMYCROFT: Towards Effective and Efficient External Data Augmentation
Oct 11, 2024



Machine learning (ML) models often require large amounts of data to perform well. When the available data is limited, model trainers may need to acquire more data from external sources. Often, useful data is held by private entities who are hesitant to share their data due to propriety and privacy concerns. This makes it challenging and expensive for model trainers to acquire the data they need to improve model performance. To address this challenge, we propose Mycroft, a data-efficient method that enables model trainers to evaluate the relative utility of different data sources while working with a constrained data-sharing budget. By leveraging feature space distances and gradient matching, Mycroft identifies small but informative data subsets from each owner, allowing model trainers to maximize performance with minimal data exposure. Experimental results across four tasks in two domains show that Mycroft converges rapidly to the performance of the full-information baseline, where all data is shared. Moreover, Mycroft is robust to noise and can effectively rank data owners by utility. Mycroft can pave the way for democratized training of high performance ML models.
Towards Scalable and Robust Model Versioning
Jan 17, 2024As the deployment of deep learning models continues to expand across industries, the threat of malicious incursions aimed at gaining access to these deployed models is on the rise. Should an attacker gain access to a deployed model, whether through server breaches, insider attacks, or model inversion techniques, they can then construct white-box adversarial attacks to manipulate the model's classification outcomes, thereby posing significant risks to organizations that rely on these models for critical tasks. Model owners need mechanisms to protect themselves against such losses without the necessity of acquiring fresh training data - a process that typically demands substantial investments in time and capital. In this paper, we explore the feasibility of generating multiple versions of a model that possess different attack properties, without acquiring new training data or changing model architecture. The model owner can deploy one version at a time and replace a leaked version immediately with a new version. The newly deployed model version can resist adversarial attacks generated leveraging white-box access to one or all previously leaked versions. We show theoretically that this can be accomplished by incorporating parameterized hidden distributions into the model training data, forcing the model to learn task-irrelevant features uniquely defined by the chosen data. Additionally, optimal choices of hidden distributions can produce a sequence of model versions capable of resisting compound transferability attacks over time. Leveraging our analytical insights, we design and implement a practical model versioning method for DNN classifiers, which leads to significant robustness improvements over existing methods. We believe our work presents a promising direction for safeguarding DNN services beyond their initial deployment.
Characterizing the Optimal 0-1 Loss for Multi-class Classification with a Test-time Attacker
Feb 21, 2023



Finding classifiers robust to adversarial examples is critical for their safe deployment. Determining the robustness of the best possible classifier under a given threat model for a given data distribution and comparing it to that achieved by state-of-the-art training methods is thus an important diagnostic tool. In this paper, we find achievable information-theoretic lower bounds on loss in the presence of a test-time attacker for multi-class classifiers on any discrete dataset. We provide a general framework for finding the optimal 0-1 loss that revolves around the construction of a conflict hypergraph from the data and adversarial constraints. We further define other variants of the attacker-classifier game that determine the range of the optimal loss more efficiently than the full-fledged hypergraph construction. Our evaluation shows, for the first time, an analysis of the gap to optimal robustness for classifiers in the multi-class setting on benchmark datasets.
Augmenting Rule-based DNS Censorship Detection at Scale with Machine Learning
Feb 03, 2023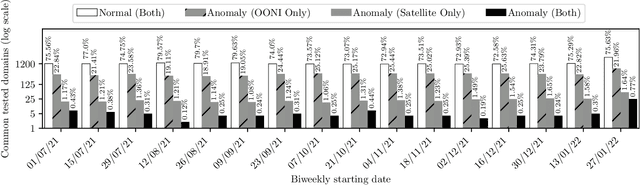
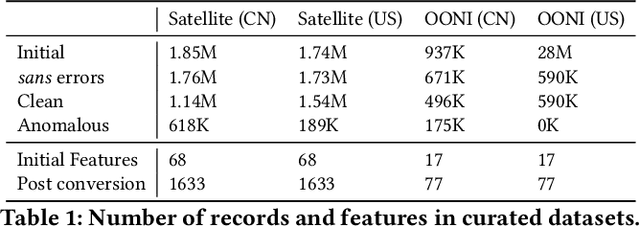
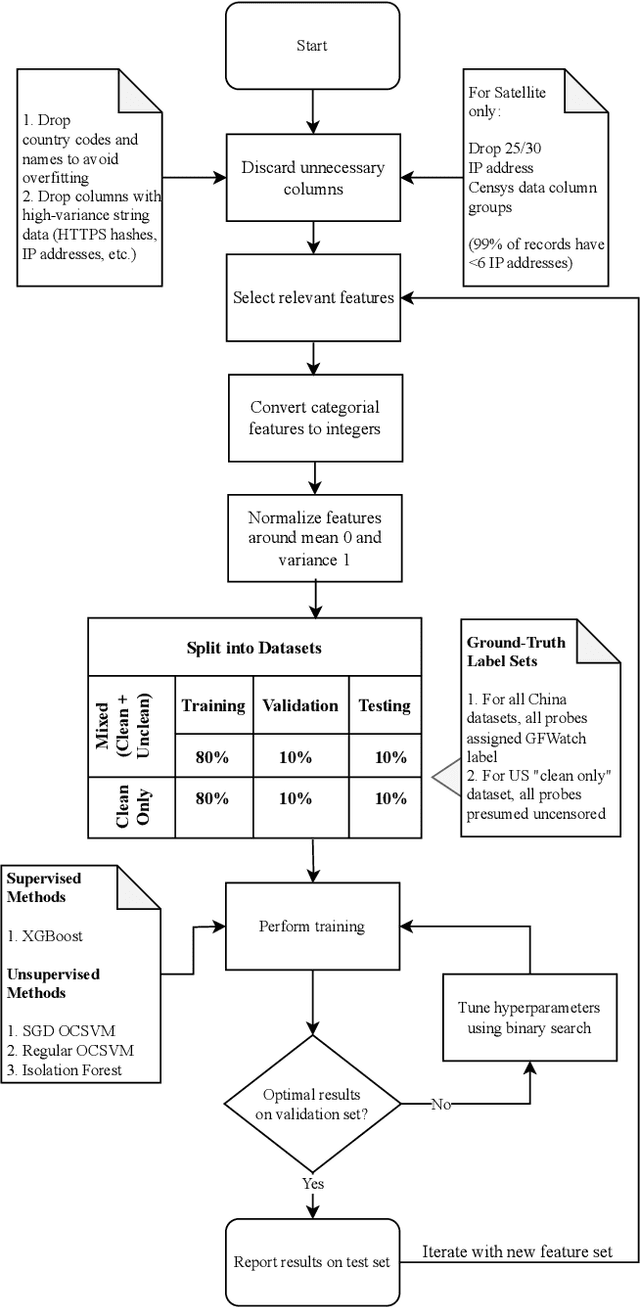
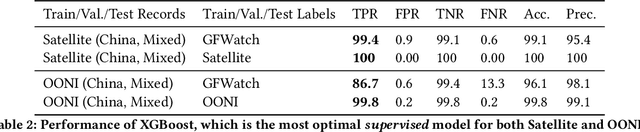
The proliferation of global censorship has led to the development of a plethora of measurement platforms to monitor and expose it. Censorship of the domain name system (DNS) is a key mechanism used across different countries. It is currently detected by applying heuristics to samples of DNS queries and responses (probes) for specific destinations. These heuristics, however, are both platform-specific and have been found to be brittle when censors change their blocking behavior, necessitating a more reliable automated process for detecting censorship. In this paper, we explore how machine learning (ML) models can (1) help streamline the detection process, (2) improve the usability of large-scale datasets for censorship detection, and (3) discover new censorship instances and blocking signatures missed by existing heuristic methods. Our study shows that supervised models, trained using expert-derived labels on instances of known anomalies and possible censorship, can learn the detection heuristics employed by different measurement platforms. More crucially, we find that unsupervised models, trained solely on uncensored instances, can identify new instances and variations of censorship missed by existing heuristics. Moreover, both methods demonstrate the capability to uncover a substantial number of new DNS blocking signatures, i.e., injected fake IP addresses overlooked by existing heuristics. These results are underpinned by an important methodological finding: comparing the outputs of models trained using the same probes but with labels arising from independent processes allows us to more reliably detect cases of censorship in the absence of ground-truth labels of censorship.
Natural Backdoor Datasets
Jun 21, 2022

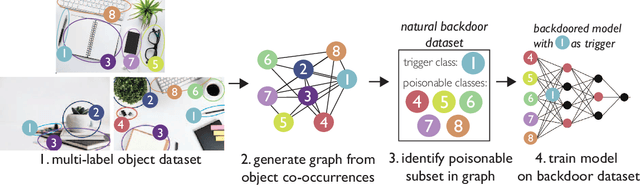
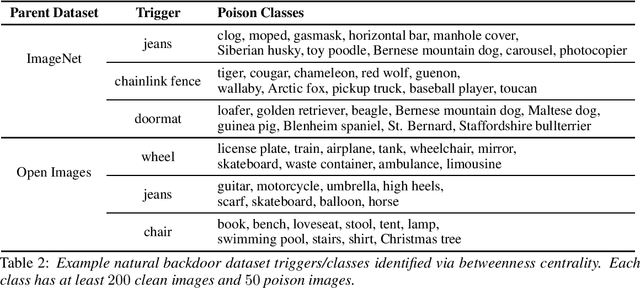
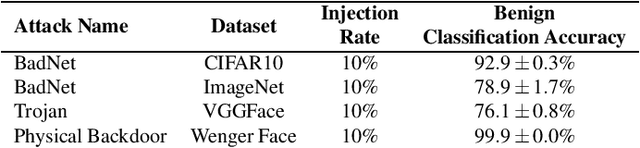
Extensive literature on backdoor poison attacks has studied attacks and defenses for backdoors using "digital trigger patterns." In contrast, "physical backdoors" use physical objects as triggers, have only recently been identified, and are qualitatively different enough to resist all defenses targeting digital trigger backdoors. Research on physical backdoors is limited by access to large datasets containing real images of physical objects co-located with targets of classification. Building these datasets is time- and labor-intensive. This works seeks to address the challenge of accessibility for research on physical backdoor attacks. We hypothesize that there may be naturally occurring physically co-located objects already present in popular datasets such as ImageNet. Once identified, a careful relabeling of these data can transform them into training samples for physical backdoor attacks. We propose a method to scalably identify these subsets of potential triggers in existing datasets, along with the specific classes they can poison. We call these naturally occurring trigger-class subsets natural backdoor datasets. Our techniques successfully identify natural backdoors in widely-available datasets, and produce models behaviorally equivalent to those trained on manually curated datasets. We release our code to allow the research community to create their own datasets for research on physical backdoor attacks.
Understanding Robust Learning through the Lens of Representation Similarities
Jun 20, 2022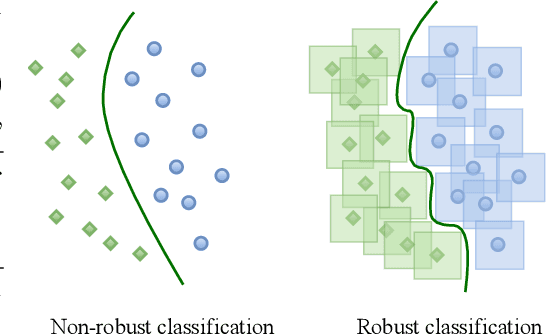
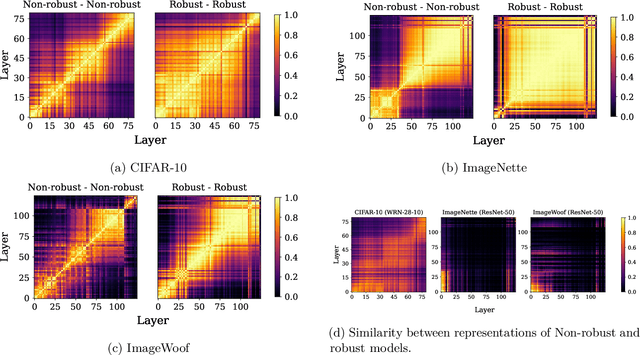
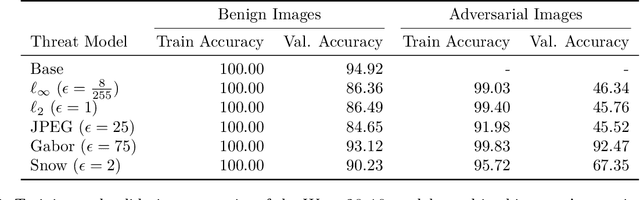
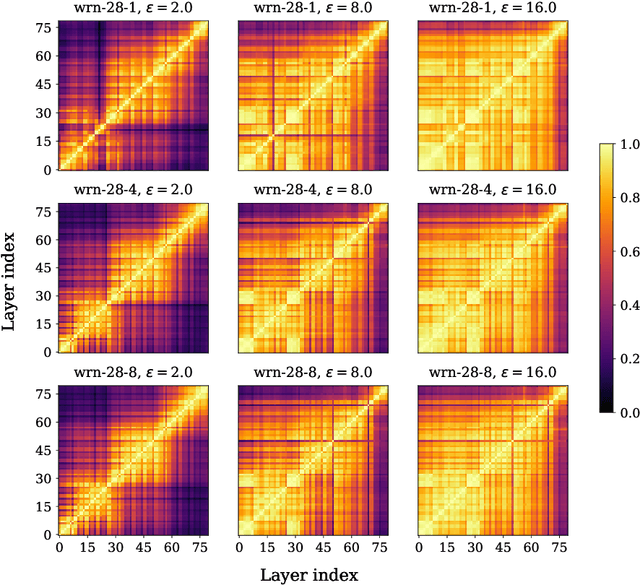
Representation learning, i.e. the generation of representations useful for downstream applications, is a task of fundamental importance that underlies much of the success of deep neural networks (DNNs). Recently, robustness to adversarial examples has emerged as a desirable property for DNNs, spurring the development of robust training methods that account for adversarial examples. In this paper, we aim to understand how the properties of representations learned by robust training differ from those obtained from standard, non-robust training. This is critical to diagnosing numerous salient pitfalls in robust networks, such as, degradation of performance on benign inputs, poor generalization of robustness, and increase in over-fitting. We utilize a powerful set of tools known as representation similarity metrics, across three vision datasets, to obtain layer-wise comparisons between robust and non-robust DNNs with different architectures, training procedures and adversarial constraints. Our experiments highlight hitherto unseen properties of robust representations that we posit underlie the behavioral differences of robust networks. We discover a lack of specialization in robust networks' representations along with a disappearance of `block structure'. We also find overfitting during robust training largely impacts deeper layers. These, along with other findings, suggest ways forward for the design and training of better robust networks.
Can Backdoor Attacks Survive Time-Varying Models?
Jun 08, 2022
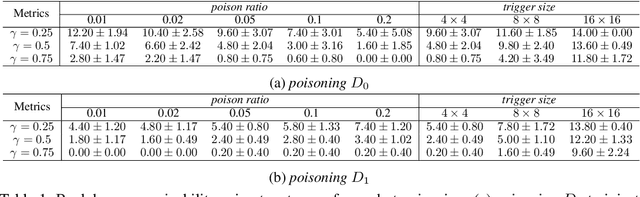
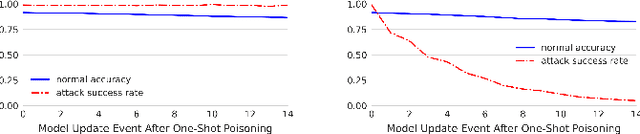

Backdoors are powerful attacks against deep neural networks (DNNs). By poisoning training data, attackers can inject hidden rules (backdoors) into DNNs, which only activate on inputs containing attack-specific triggers. While existing work has studied backdoor attacks on a variety of DNN models, they only consider static models, which remain unchanged after initial deployment. In this paper, we study the impact of backdoor attacks on a more realistic scenario of time-varying DNN models, where model weights are updated periodically to handle drifts in data distribution over time. Specifically, we empirically quantify the "survivability" of a backdoor against model updates, and examine how attack parameters, data drift behaviors, and model update strategies affect backdoor survivability. Our results show that one-shot backdoor attacks (i.e., only poisoning training data once) do not survive past a few model updates, even when attackers aggressively increase trigger size and poison ratio. To stay unaffected by model update, attackers must continuously introduce corrupted data into the training pipeline. Together, these results indicate that when models are updated to learn new data, they also "forget" backdoors as hidden, malicious features. The larger the distribution shift between old and new training data, the faster backdoors are forgotten. Leveraging these insights, we apply a smart learning rate scheduler to further accelerate backdoor forgetting during model updates, which prevents one-shot backdoors from surviving past a single model update.
Traceback of Data Poisoning Attacks in Neural Networks
Oct 13, 2021

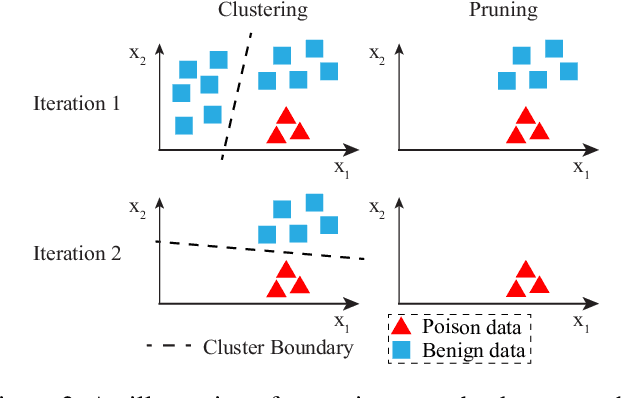
In adversarial machine learning, new defenses against attacks on deep learning systems are routinely broken soon after their release by more powerful attacks. In this context, forensic tools can offer a valuable complement to existing defenses, by tracing back a successful attack to its root cause, and offering a path forward for mitigation to prevent similar attacks in the future. In this paper, we describe our efforts in developing a forensic traceback tool for poison attacks on deep neural networks. We propose a novel iterative clustering and pruning solution that trims "innocent" training samples, until all that remains is the set of poisoned data responsible for the attack. Our method clusters training samples based on their impact on model parameters, then uses an efficient data unlearning method to prune innocent clusters. We empirically demonstrate the efficacy of our system on three types of dirty-label (backdoor) poison attacks and three types of clean-label poison attacks, across domains of computer vision and malware classification. Our system achieves over 98.4% precision and 96.8% recall across all attacks. We also show that our system is robust against four anti-forensics measures specifically designed to attack it.
Lower Bounds on Cross-Entropy Loss in the Presence of Test-time Adversaries
Apr 16, 2021
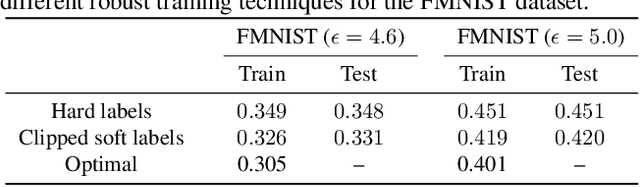
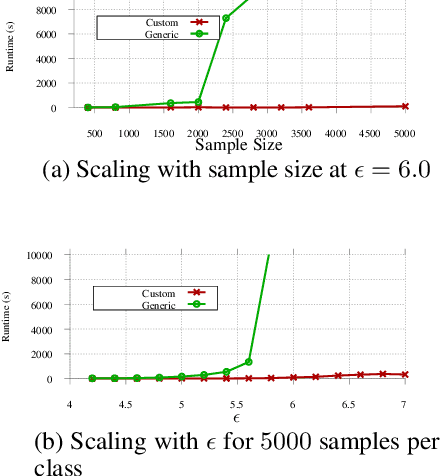
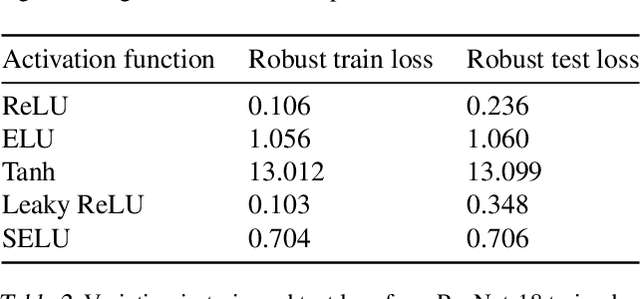
Understanding the fundamental limits of robust supervised learning has emerged as a problem of immense interest, from both practical and theoretical standpoints. In particular, it is critical to determine classifier-agnostic bounds on the training loss to establish when learning is possible. In this paper, we determine optimal lower bounds on the cross-entropy loss in the presence of test-time adversaries, along with the corresponding optimal classification outputs. Our formulation of the bound as a solution to an optimization problem is general enough to encompass any loss function depending on soft classifier outputs. We also propose and provide a proof of correctness for a bespoke algorithm to compute this lower bound efficiently, allowing us to determine lower bounds for multiple practical datasets of interest. We use our lower bounds as a diagnostic tool to determine the effectiveness of current robust training methods and find a gap from optimality at larger budgets. Finally, we investigate the possibility of using of optimal classification outputs as soft labels to empirically improve robust training.
A Critical Evaluation of Open-World Machine Learning
Jul 08, 2020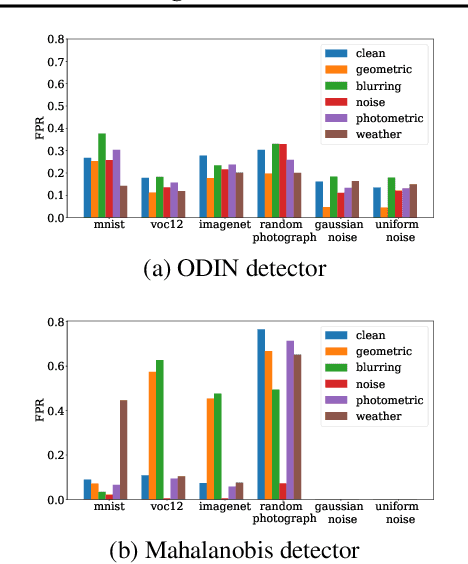
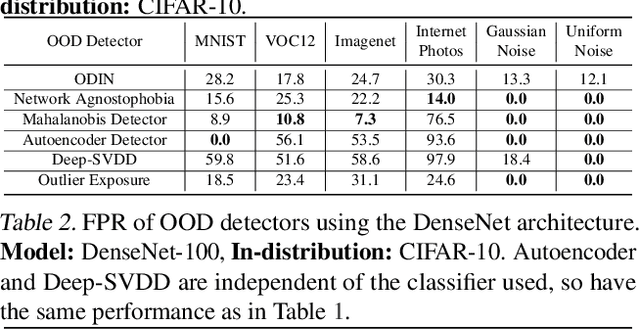
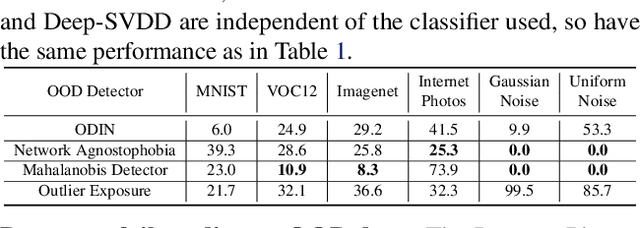
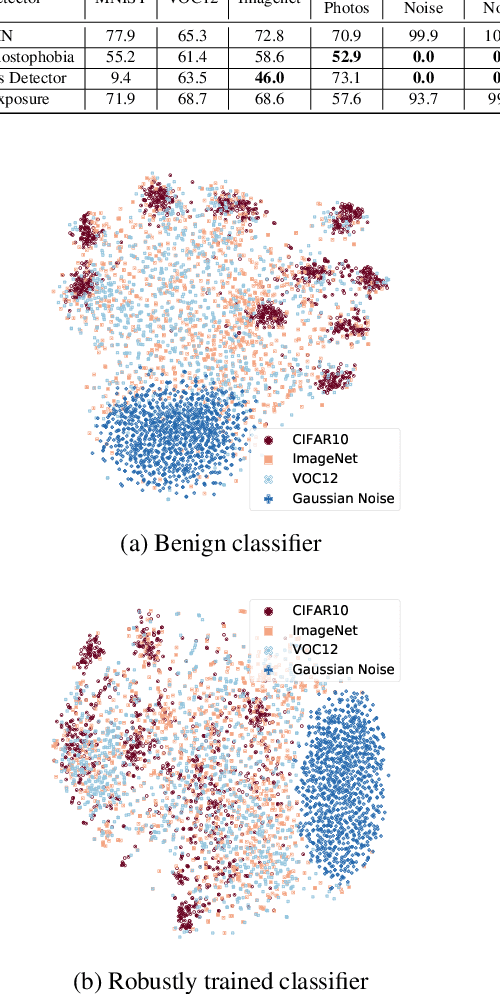
Open-world machine learning (ML) combines closed-world models trained on in-distribution data with out-of-distribution (OOD) detectors, which aim to detect and reject OOD inputs. Previous works on open-world ML systems usually fail to test their reliability under diverse, and possibly adversarial conditions. Therefore, in this paper, we seek to understand how resilient are state-of-the-art open-world ML systems to changes in system components? With our evaluation across 6 OOD detectors, we find that the choice of in-distribution data, model architecture and OOD data have a strong impact on OOD detection performance, inducing false positive rates in excess of $70\%$. We further show that OOD inputs with 22 unintentional corruptions or adversarial perturbations render open-world ML systems unusable with false positive rates of up to $100\%$. To increase the resilience of open-world ML, we combine robust classifiers with OOD detection techniques and uncover a new trade-off between OOD detection and robustness.