 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Agent Behaviors in Reinforcement-Learning-Based Cyber-Battle Simulation Platforms
Jun 09, 2025We analyze two open source deep reinforcement learning agents submitted to the CAGE Challenge 2 cyber defense challenge, where each competitor submitted an agent to defend a simulated network against each of several provided rules-based attack agents. We demonstrate that one can gain interpretability of agent successes and failures by simplifying the complex state and action spaces and by tracking important events, shedding light on the fine-grained behavior of both the defense and attack agents in each experimental scenario. By analyzing important events within an evaluation episode, we identify patterns in infiltration and clearing events that tell us how well the attacker and defender played their respective roles; for example, defenders were generally able to clear infiltrations within one or two timesteps of a host being exploited. By examining transitions in the environment's state caused by the various possible actions, we determine which actions tended to be effective and which did not, showing that certain important actions are between 40% and 99% ineffective. We examine how decoy services affect exploit success, concluding for instance that decoys block up to 94% of exploits that would directly grant privileged access to a host. Finally, we discuss the realism of the challenge and ways that the CAGE Challenge 4 has addressed some of our concerns.
Augmenting Rule-based DNS Censorship Detection at Scale with Machine Learning
Feb 03, 2023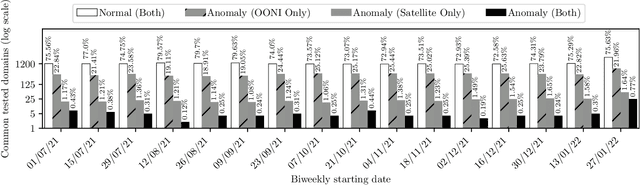
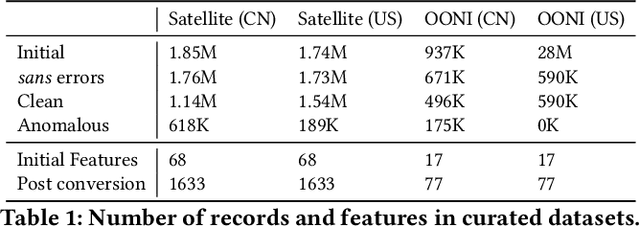
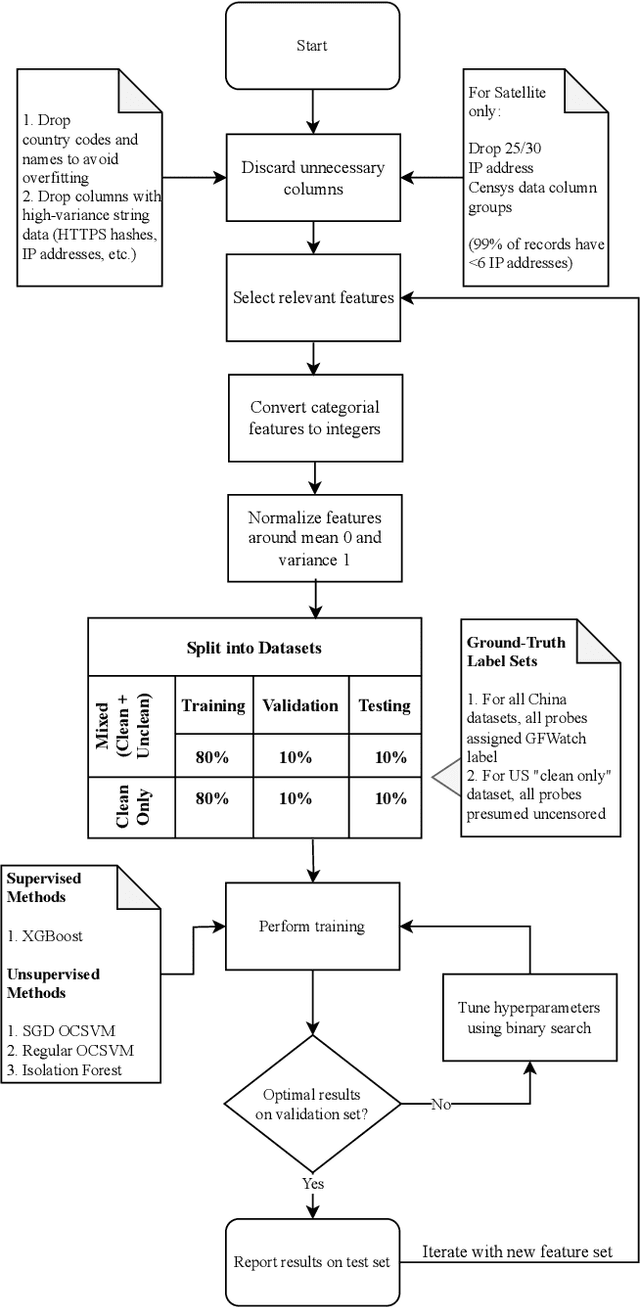
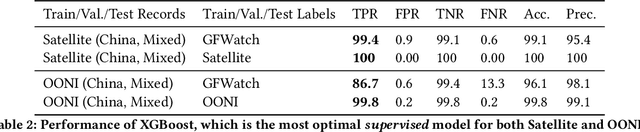
The proliferation of global censorship has led to the development of a plethora of measurement platforms to monitor and expose it. Censorship of the domain name system (DNS) is a key mechanism used across different countries. It is currently detected by applying heuristics to samples of DNS queries and responses (probes) for specific destinations. These heuristics, however, are both platform-specific and have been found to be brittle when censors change their blocking behavior, necessitating a more reliable automated process for detecting censorship. In this paper, we explore how machine learning (ML) models can (1) help streamline the detection process, (2) improve the usability of large-scale datasets for censorship detection, and (3) discover new censorship instances and blocking signatures missed by existing heuristic methods. Our study shows that supervised models, trained using expert-derived labels on instances of known anomalies and possible censorship, can learn the detection heuristics employed by different measurement platforms. More crucially, we find that unsupervised models, trained solely on uncensored instances, can identify new instances and variations of censorship missed by existing heuristics. Moreover, both methods demonstrate the capability to uncover a substantial number of new DNS blocking signatures, i.e., injected fake IP addresses overlooked by existing heuristics. These results are underpinned by an important methodological finding: comparing the outputs of models trained using the same probes but with labels arising from independent processes allows us to more reliably detect cases of censorship in the absence of ground-truth labels of censorship.
Scalable Microservice Forensics and Stability Assessment Using Variational Autoencoders
Apr 23, 2021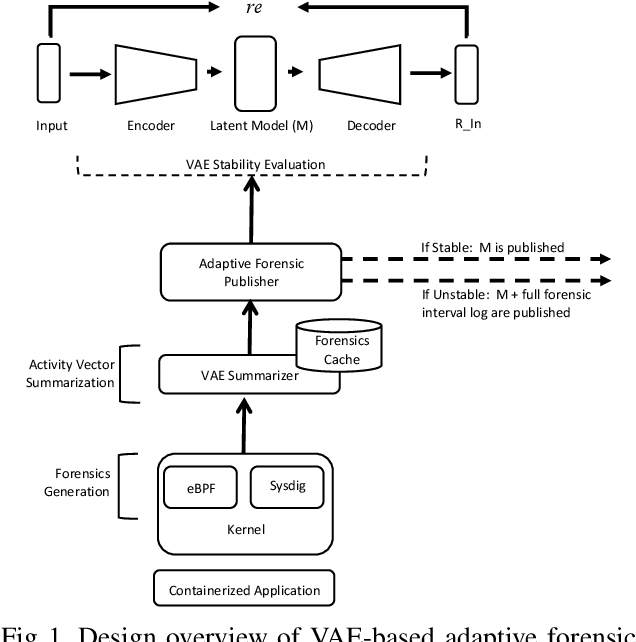
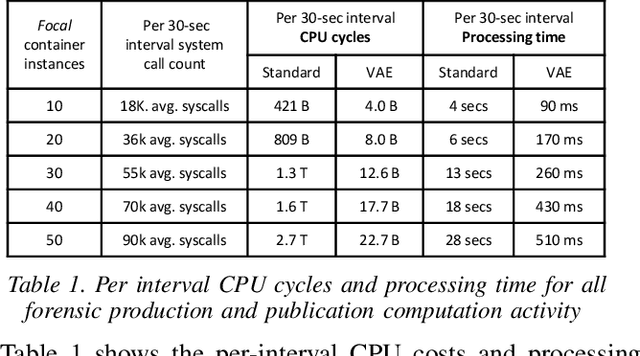
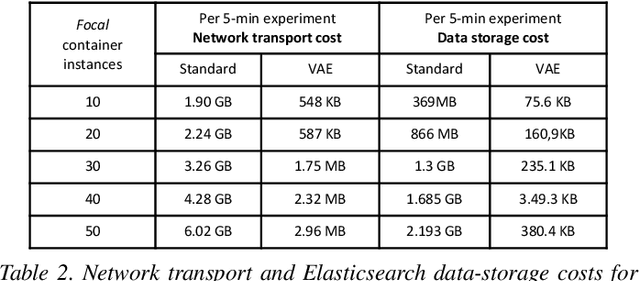
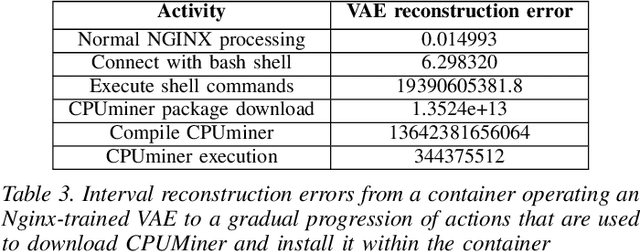
We present a deep learning based approach to containerized application runtime stability analysis, and an intelligent publishing algorithm that can dynamically adjust the depth of process-level forensics published to a backend incident analysis repository. The approach applies variational autoencoders (VAEs) to learn the stable runtime patterns of container images, and then instantiates these container-specific VAEs to implement stability detection and adaptive forensics publishing. In performance comparisons using a 50-instance container workload, a VAE-optimized service versus a conventional eBPF-based forensic publisher demonstrates 2 orders of magnitude (OM) CPU performance improvement, a 3 OM reduction in network transport volume, and a 4 OM reduction in Elasticsearch storage costs. We evaluate the VAE-based stability detection technique against two attacks, CPUMiner and HTTP-flood attack, finding that it is effective in isolating both anomalies. We believe this technique provides a novel approach to integrating fine-grained process monitoring and digital-forensic services into large container ecosystems that today simply cannot be monitored by conventional techniques
Data Masking with Privacy Guarantees
Jan 08, 2019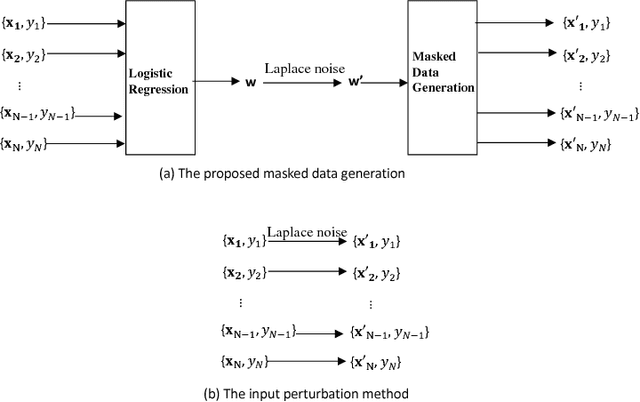
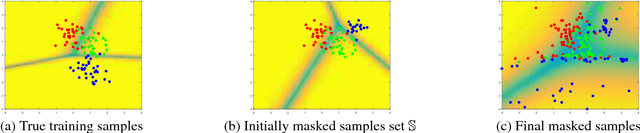


We study the problem of data release with privacy, where data is made available with privacy guarantees while keeping the usability of the data as high as possible --- this is important in health-care and other domains with sensitive data. In particular, we propose a method of masking the private data with privacy guarantee while ensuring that a classifier trained on the masked data is similar to the classifier trained on the original data, to maintain usability. We analyze the theoretical risks of the proposed method and the traditional input perturbation method. Results show that the proposed method achieves lower risk compared to the input perturbation, especially when the number of training samples gets large. We illustrate the effectiveness of the proposed method of data masking for privacy-sensitive learning on $12$ benchmark datasets.
Time Series Deinterleaving of DNS Traffic
Jul 16, 2018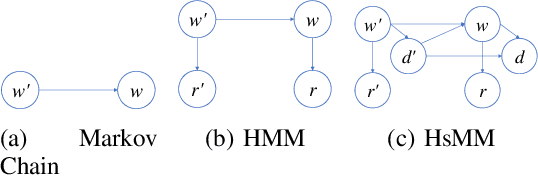
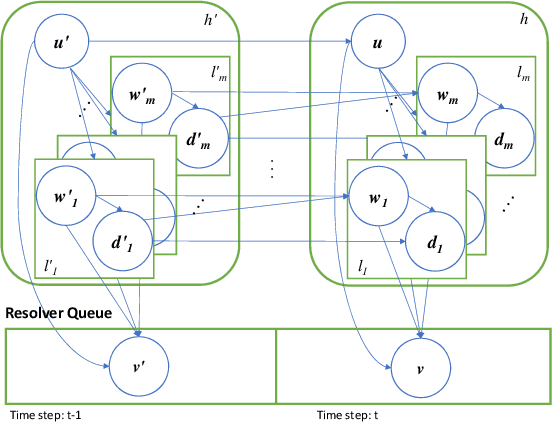
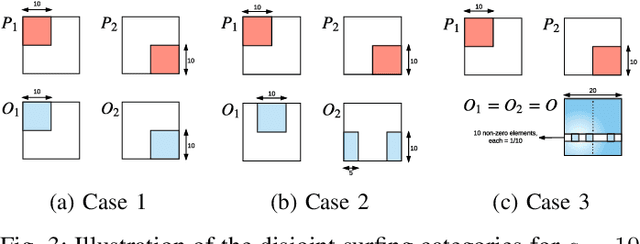
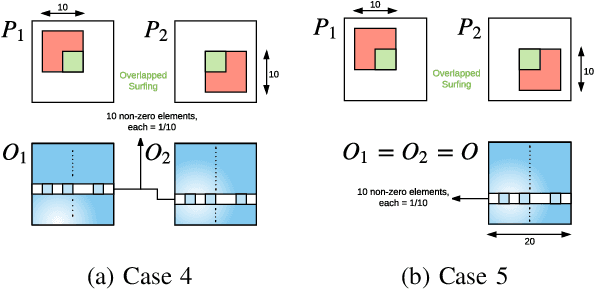
Stream deinterleaving is an important problem with various applications in the cybersecurity domain. In this paper, we consider the specific problem of deinterleaving DNS data streams using machine-learning techniques, with the objective of automating the extraction of malware domain sequences. We first develop a generative model for user request generation and DNS stream interleaving. Based on these we evaluate various inference strategies for deinterleaving including augmented HMMs and LSTMs on synthetic datasets. Our results demonstrate that state-of-the-art LSTMs outperform more traditional augmented HMMs in this application domain.
Trusted Neural Networks for Safety-Constrained Autonomous Control
May 18, 2018

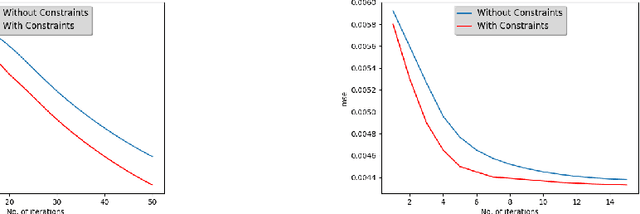
We propose Trusted Neural Network (TNN) models, which are deep neural network models that satisfy safety constraints critical to the application domain. We investigate different mechanisms for incorporating rule-based knowledge in the form of first-order logic constraints into a TNN model, where rules that encode safety are accompanied by weights indicating their relative importance. This framework allows the TNN model to learn from knowledge available in form of data as well as logical rules. We propose multiple approaches for solving this problem: (a) a multi-headed model structure that allows trade-off between satisfying logical constraints and fitting training data in a unified training framework, and (b) creating a constrained optimization problem and solving it in dual formulation by posing a new constrained loss function and using a proximal gradient descent algorithm. We demonstrate the efficacy of our TNN framework through experiments using the open-source TORCS~\cite{BernhardCAA15} 3D simulator for self-driving cars. Experiments using our first approach of a multi-headed TNN model, on a dataset generated by a customized version of TORCS, show that (1) adding safety constraints to a neural network model results in increased performance and safety, and (2) the improvement increases with increasing importance of the safety constraints. Experiments were also performed using the second approach of proximal algorithm for constrained optimization --- they demonstrate how the proposed method ensures that (1) the overall TNN model satisfies the constraints even when the training data violates some of the constraints, and (2) the proximal gradient descent algorithm on the constrained objective converges faster than the unconstrained version.