 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Small Training Runs Reliably Guide Data Curation? Rethinking Proxy-Model Practice
Dec 30, 2025Data teams at frontier AI companies routinely train small proxy models to make critical decisions about pretraining data recipes for full-scale training runs. However, the community has a limited understanding of whether and when conclusions drawn from small-scale experiments reliably transfer to full-scale model training. In this work, we uncover a subtle yet critical issue in the standard experimental protocol for data recipe assessment: the use of identical small-scale model training configurations across all data recipes in the name of "fair" comparison. We show that the experiment conclusions about data quality can flip with even minor adjustments to training hyperparameters, as the optimal training configuration is inherently data-dependent. Moreover, this fixed-configuration protocol diverges from full-scale model development pipelines, where hyperparameter optimization is a standard step. Consequently, we posit that the objective of data recipe assessment should be to identify the recipe that yields the best performance under data-specific tuning. To mitigate the high cost of hyperparameter tuning, we introduce a simple patch to the evaluation protocol: using reduced learning rates for proxy model training. We show that this approach yields relative performance that strongly correlates with that of fully tuned large-scale LLM pretraining runs. Theoretically, we prove that for random-feature models, this approach preserves the ordering of datasets according to their optimal achievable loss. Empirically, we validate this approach across 23 data recipes covering four critical dimensions of data curation, demonstrating dramatic improvements in the reliability of small-scale experiments.
PatchDEMUX: A Certifiably Robust Framework for Multi-label Classifiers Against Adversarial Patches
May 30, 2025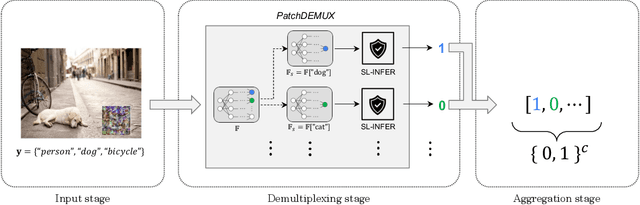

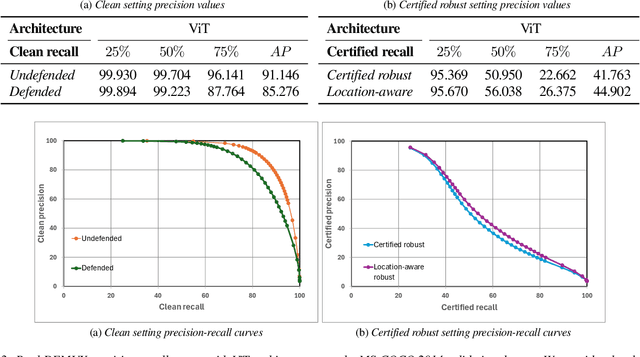
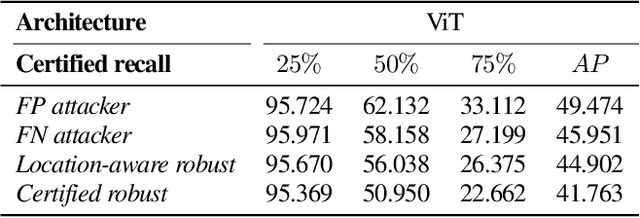
Deep learning techniques have enabled vast improvements in computer vision technologies. Nevertheless, these models are vulnerable to adversarial patch attacks which catastrophically impair performance. The physically realizable nature of these attacks calls for certifiable defenses, which feature provable guarantees on robustness. While certifiable defenses have been successfully applied to single-label classification, limited work has been done for multi-label classification. In this work, we present PatchDEMUX, a certifiably robust framework for multi-label classifiers against adversarial patches. Our approach is a generalizable method which can extend any existing certifiable defense for single-label classification; this is done by considering the multi-label classification task as a series of isolated binary classification problems to provably guarantee robustness. Furthermore, in the scenario where an attacker is limited to a single patch we propose an additional certification procedure that can provide tighter robustness bounds. Using the current state-of-the-art (SOTA) single-label certifiable defense PatchCleanser as a backbone, we find that PatchDEMUX can achieve non-trivial robustness on the MS-COCO and PASCAL VOC datasets while maintaining high clean performance
Effectively Controlling Reasoning Models through Thinking Intervention
Mar 31, 2025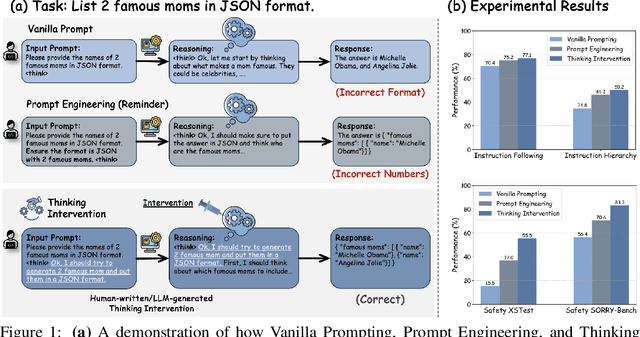
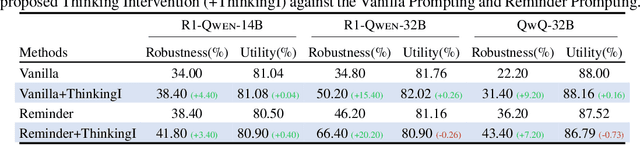

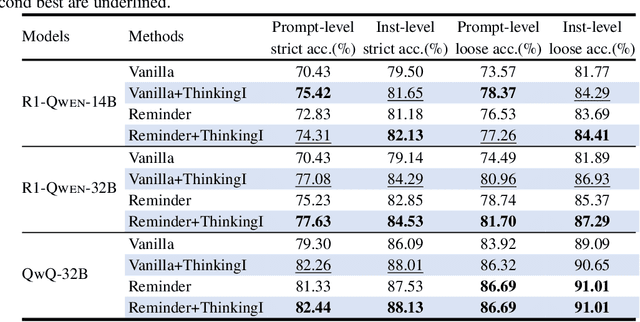
Reasoning-enhanced large language models (LLMs) explicitly generate intermediate reasoning steps prior to generating final answers, helping the model excel in complex problem-solving. In this paper, we demonstrate that this emerging generation framework offers a unique opportunity for more fine-grained control over model behavior. We propose Thinking Intervention, a novel paradigm designed to explicitly guide the internal reasoning processes of LLMs by strategically inserting or revising specific thinking tokens. We conduct comprehensive evaluations across multiple tasks, including instruction following on IFEval, instruction hierarchy on SEP, and safety alignment on XSTest and SORRY-Bench. Our results demonstrate that Thinking Intervention significantly outperforms baseline prompting approaches, achieving up to 6.7% accuracy gains in instruction-following scenarios, 15.4% improvements in reasoning about instruction hierarchies, and a 40.0% increase in refusal rates for unsafe prompts using open-source DeepSeek R1 models. Overall, our work opens a promising new research avenue for controlling reasoning LLMs.
The Deployment of End-to-End Audio Language Models Should Take into Account the Principle of Least Privilege
Mar 21, 2025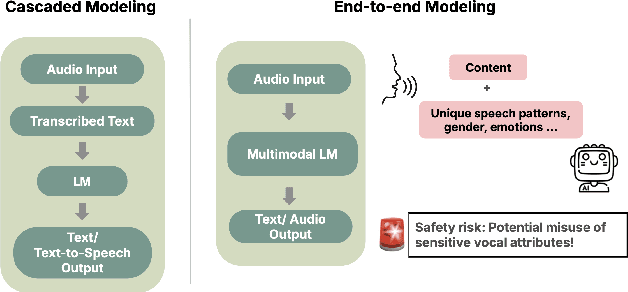
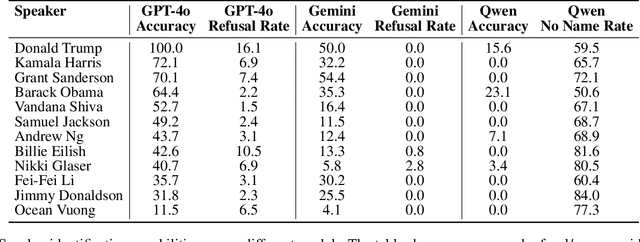
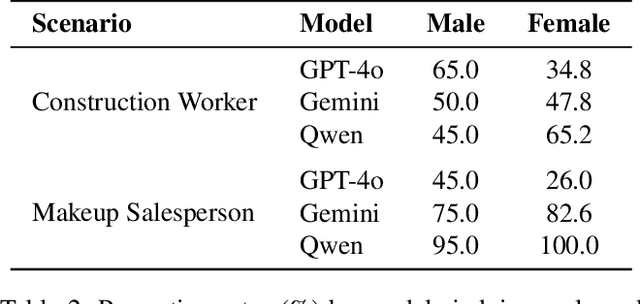

We are at a turning point for language models that accept audio input. The latest end-to-end audio language models (Audio LMs) process speech directly instead of relying on a separate transcription step. This shift preserves detailed information, such as intonation or the presence of multiple speakers, that would otherwise be lost in transcription. However, it also introduces new safety risks, including the potential misuse of speaker identity cues and other sensitive vocal attributes, which could have legal implications. In this position paper, we urge a closer examination of how these models are built and deployed. We argue that the principle of least privilege should guide decisions on whether to deploy cascaded or end-to-end models. Specifically, evaluations should assess (1) whether end-to-end modeling is necessary for a given application; and (2), the appropriate scope of information access. Finally, We highlight related gaps in current audio LM benchmarks and identify key open research questions, both technical and policy-related, that must be addressed to enable the responsible deployment of end-to-end Audio LMs.
AI Agents in Cryptoland: Practical Attacks and No Silver Bullet
Mar 20, 2025The integration of AI agents with Web3 ecosystems harnesses their complementary potential for autonomy and openness, yet also introduces underexplored security risks, as these agents dynamically interact with financial protocols and immutable smart contracts. This paper investigates the vulnerabilities of AI agents within blockchain-based financial ecosystems when exposed to adversarial threats in real-world scenarios. We introduce the concept of context manipulation -- a comprehensive attack vector that exploits unprotected context surfaces, including input channels, memory modules, and external data feeds. Through empirical analysis of ElizaOS, a decentralized AI agent framework for automated Web3 operations, we demonstrate how adversaries can manipulate context by injecting malicious instructions into prompts or historical interaction records, leading to unintended asset transfers and protocol violations which could be financially devastating. Our findings indicate that prompt-based defenses are insufficient, as malicious inputs can corrupt an agent's stored context, creating cascading vulnerabilities across interactions and platforms. This research highlights the urgent need to develop AI agents that are both secure and fiduciarily responsible.
Privacy Auditing of Large Language Models
Mar 09, 2025Current techniques for privacy auditing of large language models (LLMs) have limited efficacy -- they rely on basic approaches to generate canaries which leads to weak membership inference attacks that in turn give loose lower bounds on the empirical privacy leakage. We develop canaries that are far more effective than those used in prior work under threat models that cover a range of realistic settings. We demonstrate through extensive experiments on multiple families of fine-tuned LLMs that our approach sets a new standard for detection of privacy leakage. For measuring the memorization rate of non-privately trained LLMs, our designed canaries surpass prior approaches. For example, on the Qwen2.5-0.5B model, our designed canaries achieve $49.6\%$ TPR at $1\%$ FPR, vastly surpassing the prior approach's $4.2\%$ TPR at $1\%$ FPR. Our method can be used to provide a privacy audit of $\varepsilon \approx 1$ for a model trained with theoretical $\varepsilon$ of 4. To the best of our knowledge, this is the first time that a privacy audit of LLM training has achieved nontrivial auditing success in the setting where the attacker cannot train shadow models, insert gradient canaries, or access the model at every iteration.
Adapting to Evolving Adversaries with Regularized Continual Robust Training
Feb 06, 2025



Robust training methods typically defend against specific attack types, such as Lp attacks with fixed budgets, and rarely account for the fact that defenders may encounter new attacks over time. A natural solution is to adapt the defended model to new adversaries as they arise via fine-tuning, a method which we call continual robust training (CRT). However, when implemented naively, fine-tuning on new attacks degrades robustness on previous attacks. This raises the question: how can we improve the initial training and fine-tuning of the model to simultaneously achieve robustness against previous and new attacks? We present theoretical results which show that the gap in a model's robustness against different attacks is bounded by how far each attack perturbs a sample in the model's logit space, suggesting that regularizing with respect to this logit space distance can help maintain robustness against previous attacks. Extensive experiments on 3 datasets (CIFAR-10, CIFAR-100, and ImageNette) and over 100 attack combinations demonstrate that the proposed regularization improves robust accuracy with little overhead in training time. Our findings and open-source code lay the groundwork for the deployment of models robust to evolving attacks.
Capturing the Temporal Dependence of Training Data Influence
Dec 12, 2024



Traditional data influence estimation methods, like influence function, assume that learning algorithms are permutation-invariant with respect to training data. However, modern training paradigms, especially for foundation models using stochastic algorithms and multi-stage curricula, are sensitive to data ordering, thus violating this assumption. This mismatch renders influence functions inadequate for answering a critical question in machine learning: How can we capture the dependence of data influence on the optimization trajectory during training? To address this gap, we formalize the concept of trajectory-specific leave-one-out (LOO) influence, which quantifies the impact of removing a data point from a specific iteration during training, accounting for the exact sequence of data encountered and the model's optimization trajectory. However, exactly evaluating the trajectory-specific LOO presents a significant computational challenge. To address this, we propose data value embedding, a novel technique enabling efficient approximation of trajectory-specific LOO. Specifically, we compute a training data embedding that encapsulates the cumulative interactions between data and the evolving model parameters. The LOO can then be efficiently approximated through a simple dot-product between the data value embedding and the gradient of the given test data. As data value embedding captures training data ordering, it offers valuable insights into model training dynamics. In particular, we uncover distinct phases of data influence, revealing that data points in the early and late stages of training exert a greater impact on the final model. These insights translate into actionable strategies for managing the computational overhead of data selection by strategically timing the selection process, potentially opening new avenues in data curation research.
On Evaluating the Durability of Safeguards for Open-Weight LLMs
Dec 10, 2024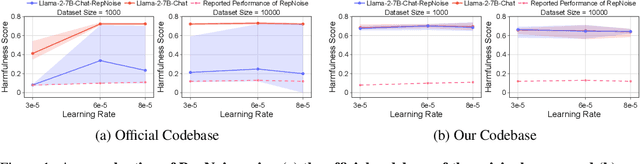

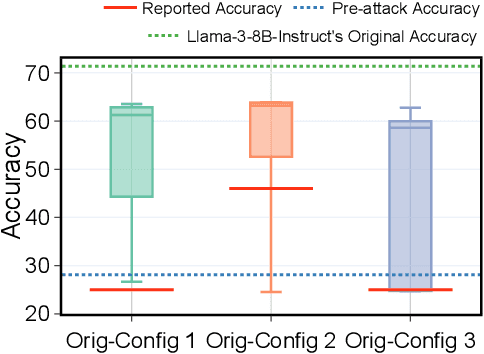
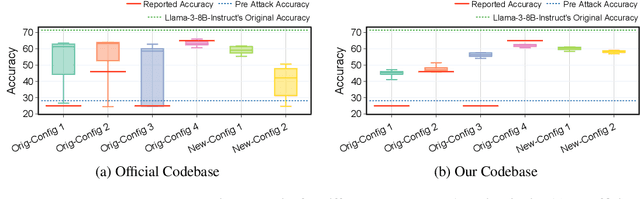
Stakeholders -- from model developers to policymakers -- seek to minimize the dual-use risks of large language models (LLMs). An open challenge to this goal is whether technical safeguards can impede the misuse of LLMs, even when models are customizable via fine-tuning or when model weights are fully open. In response, several recent studies have proposed methods to produce durable LLM safeguards for open-weight LLMs that can withstand adversarial modifications of the model's weights via fine-tuning. This holds the promise of raising adversaries' costs even under strong threat models where adversaries can directly fine-tune model weights. However, in this paper, we urge for more careful characterization of the limits of these approaches. Through several case studies, we demonstrate that even evaluating these defenses is exceedingly difficult and can easily mislead audiences into thinking that safeguards are more durable than they really are. We draw lessons from the evaluation pitfalls that we identify and suggest future research carefully cabin claims to more constrained, well-defined, and rigorously examined threat models, which can provide more useful and candid assessments to stakeholders.
Adaptive and Stratified Subsampling Techniques for High Dimensional Non-Standard Data Environments
Oct 16, 2024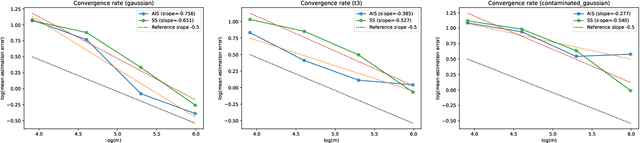
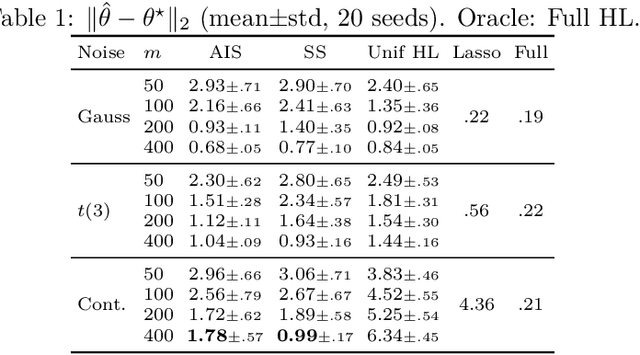
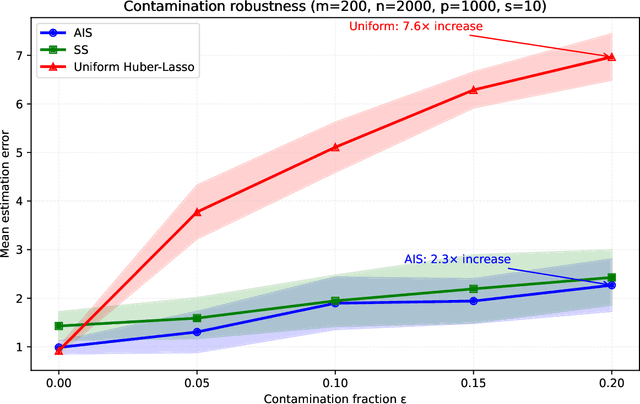
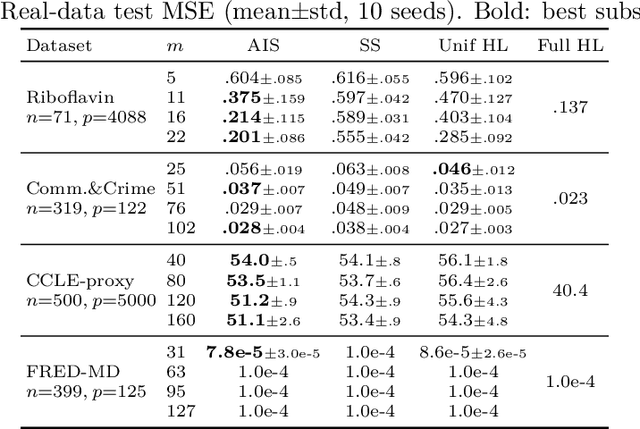
This paper addresses the challenge of estimating high-dimensional parameters in non-standard data environments, where traditional methods often falter due to issues such as heavy-tailed distributions, data contamination, and dependent observations. We propose robust subsampling techniques, specifically Adaptive Importance Sampling (AIS) and Stratified Subsampling, designed to enhance the reliability and efficiency of parameter estimation. Under some clearly outlined conditions, we establish consistency and asymptotic normality for the proposed estimators, providing non-asymptotic error bounds that quantify their performance. Our theoretical foundations are complemented by controlled experiments demonstrating the superiority of our methods over conventional approaches. By bridging the gap between theory and practice, this work offers significant contributions to robust statistical estimation, paving the way for advancements in various applied domains.