 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Refusal Tokens to Refusal Control: Discovering and Steering Category-Specific Refusal Directions
Mar 09, 2026Language models are commonly fine-tuned for safety alignment to refuse harmful prompts. One approach fine-tunes them to generate categorical refusal tokens that distinguish different refusal types before responding. In this work, we leverage a version of Llama 3 8B fine-tuned with these categorical refusal tokens to enable inference-time control over fine-grained refusal behavior, improving both safety and reliability. We show that refusal token fine-tuning induces separable, category-aligned directions in the residual stream, which we extract and use to construct categorical steering vectors with a lightweight probe that determines whether to steer toward or away from refusal during inference. In addition, we introduce a learned low-rank combination that mixes these category directions in a whitened, orthonormal steering basis, resulting in a single controllable intervention under activation-space anisotropy, and show that this intervention is transferable across same-architecture model variants without additional training. Across benchmarks, both categorical steering vectors and the low-rank combination consistently reduce over-refusals on benign prompts while increasing refusal rates on harmful prompts, highlighting their utility for multi-category refusal control.
Multi-Token Prediction via Self-Distillation
Feb 05, 2026Existing techniques for accelerating language model inference, such as speculative decoding, require training auxiliary speculator models and building and deploying complex inference pipelines. We consider a new approach for converting a pretrained autoregressive language model from a slow single next token prediction model into a fast standalone multi-token prediction model using a simple online distillation objective. The final model retains the exact same implementation as the pretrained initial checkpoint and is deployable without the addition of any auxiliary verifier or other specialized inference code. On GSM8K, our method produces models that can decode more than $3\times$ faster on average at $<5\%$ drop in accuracy relative to single token decoding performance.
A Few Bad Neurons: Isolating and Surgically Correcting Sycophancy
Jan 26, 2026Behavioral alignment in large language models (LLMs) is often achieved through broad fine-tuning, which can result in undesired side effects like distributional shift and low interpretability. We propose a method for alignment that identifies and updates only the neurons most responsible for a given behavior, a targeted approach that allows for fine-tuning with significantly less data. Using sparse autoencoders (SAEs) and linear probes, we isolate the 3% of MLP neurons most predictive of a target behavior, decode them into residual space, and fine-tune only those neurons using gradient masking. We demonstrate this approach on the task of reducing sycophantic behavior, where our method matches or exceeds state-of-the-art performance on four benchmarks (Syco-Bench, NLP, POLI, PHIL) using Gemma-2-2B and 9B models. Our results show that sparse, neuron-level updates offer a scalable and precise alternative to full-model fine-tuning, remaining effective even in situations when little data is available
Modeling and Predicting Multi-Turn Answer Instability in Large Language Models
Nov 12, 2025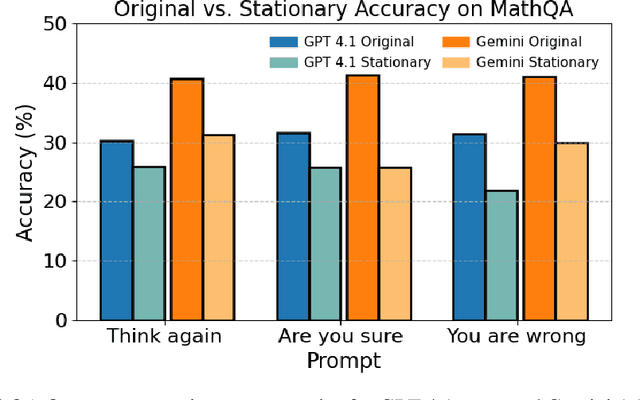

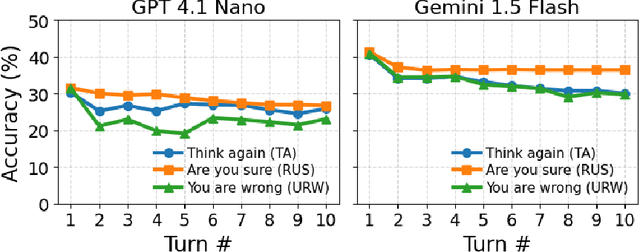

As large language models (LLMs) are adopted in an increasingly wide range of applications, user-model interactions have grown in both frequency and scale. Consequently, research has focused on evaluating the robustness of LLMs, an essential quality for real-world tasks. In this paper, we employ simple multi-turn follow-up prompts to evaluate models' answer changes, model accuracy dynamics across turns with Markov chains, and examine whether linear probes can predict these changes. Our results show significant vulnerabilities in LLM robustness: a simple "Think again" prompt led to an approximate 10% accuracy drop for Gemini 1.5 Flash over nine turns, while combining this prompt with a semantically equivalent reworded question caused a 7.5% drop for Claude 3.5 Haiku. Additionally, we find that model accuracy across turns can be effectively modeled using Markov chains, enabling the prediction of accuracy probabilities over time. This allows for estimation of the model's stationary (long-run) accuracy, which we find to be on average approximately 8% lower than its first-turn accuracy for Gemini 1.5 Flash. Our results from a model's hidden states also reveal evidence that linear probes can help predict future answer changes. Together, these results establish stationary accuracy as a principled robustness metric for interactive settings and expose the fragility of models under repeated questioning. Addressing this instability will be essential for deploying LLMs in high-stakes and interactive settings where consistent reasoning is as important as initial accuracy.
SALT: Steering Activations towards Leakage-free Thinking in Chain of Thought
Nov 11, 2025As Large Language Models (LLMs) evolve into personal assistants with access to sensitive user data, they face a critical privacy challenge: while prior work has addressed output-level privacy, recent findings reveal that LLMs often leak private information through their internal reasoning processes, violating contextual privacy expectations. These leaky thoughts occur when models inadvertently expose sensitive details in their reasoning traces, even when final outputs appear safe. The challenge lies in preventing such leakage without compromising the model's reasoning capabilities, requiring a delicate balance between privacy and utility. We introduce Steering Activations towards Leakage-free Thinking (SALT), a lightweight test-time intervention that mitigates privacy leakage in model's Chain of Thought (CoT) by injecting targeted steering vectors into hidden state. We identify the high-leakage layers responsible for this behavior. Through experiments across multiple LLMs, we demonstrate that SALT achieves reductions including $18.2\%$ reduction in CPL on QwQ-32B, $17.9\%$ reduction in CPL on Llama-3.1-8B, and $31.2\%$ reduction in CPL on Deepseek in contextual privacy leakage dataset AirGapAgent-R while maintaining comparable task performance and utility. Our work establishes SALT as a practical approach for test-time privacy protection in reasoning-capable language models, offering a path toward safer deployment of LLM-based personal agents.
Alignment-Constrained Dynamic Pruning for LLMs: Identifying and Preserving Alignment-Critical Circuits
Nov 09, 2025Large Language Models require substantial computational resources for inference, posing deployment challenges. While dynamic pruning offers superior efficiency over static methods through adaptive circuit selection, it exacerbates alignment degradation by retaining only input-dependent safety-critical circuit preservation across diverse inputs. As a result, addressing these heightened alignment vulnerabilities remains critical. We introduce Alignment-Aware Probe Pruning (AAPP), a dynamic structured pruning method that adaptively preserves alignment-relevant circuits during inference, building upon Probe Pruning. Experiments on LLaMA 2-7B, Qwen2.5-14B-Instruct, and Gemma-3-12B-IT show AAPP improves refusal rates by 50\% at matched compute, enabling efficient yet safety-preserving LLM deployment.
Dense Backpropagation Improves Training for Sparse Mixture-of-Experts
Apr 18, 2025Mixture of Experts (MoE) pretraining is more scalable than dense Transformer pretraining, because MoEs learn to route inputs to a sparse set of their feedforward parameters. However, this means that MoEs only receive a sparse backward update, leading to training instability and suboptimal performance. We present a lightweight approximation method that gives the MoE router a dense gradient update while continuing to sparsely activate its parameters. Our method, which we refer to as Default MoE, substitutes missing expert activations with default outputs consisting of an exponential moving average of expert outputs previously seen over the course of training. This allows the router to receive signals from every expert for each token, leading to significant improvements in training performance. Our Default MoE outperforms standard TopK routing in a variety of settings without requiring significant computational overhead. Code: https://github.com/vatsal0/default-moe.
Analysis of Attention in Video Diffusion Transformers
Apr 14, 2025We conduct an in-depth analysis of attention in video diffusion transformers (VDiTs) and report a number of novel findings. We identify three key properties of attention in VDiTs: Structure, Sparsity, and Sinks. Structure: We observe that attention patterns across different VDiTs exhibit similar structure across different prompts, and that we can make use of the similarity of attention patterns to unlock video editing via self-attention map transfer. Sparse: We study attention sparsity in VDiTs, finding that proposed sparsity methods do not work for all VDiTs, because some layers that are seemingly sparse cannot be sparsified. Sinks: We make the first study of attention sinks in VDiTs, comparing and contrasting them to attention sinks in language models. We propose a number of future directions that can make use of our insights to improve the efficiency-quality Pareto frontier for VDiTs.
LoRI: Reducing Cross-Task Interference in Multi-Task Low-Rank Adaptation
Apr 10, 2025Low-Rank Adaptation (LoRA) has emerged as a popular parameter-efficient fine-tuning (PEFT) method for Large Language Models (LLMs), yet it still incurs notable overhead and suffers from parameter interference in multi-task scenarios. We propose LoRA with Reduced Interference (LoRI), a simple yet effective approach that freezes the projection matrices $A$ as random projections and sparsifies the matrices $B$ using task-specific masks. This design substantially reduces the number of trainable parameters while maintaining strong task performance. Moreover, LoRI minimizes cross-task interference in adapter merging by leveraging the orthogonality between adapter subspaces, and supports continual learning by using sparsity to mitigate catastrophic forgetting. Extensive experiments across natural language understanding, mathematical reasoning, code generation, and safety alignment tasks demonstrate that LoRI outperforms full fine-tuning and existing PEFT methods, while using up to 95% fewer trainable parameters than LoRA. In multi-task experiments, LoRI enables effective adapter merging and continual learning with reduced cross-task interference. Code is available at: https://github.com/juzhengz/LoRI
Using Attention Sinks to Identify and Evaluate Dormant Heads in Pretrained LLMs
Apr 04, 2025Multi-head attention is foundational to large language models (LLMs), enabling different heads to have diverse focus on relevant input tokens. However, learned behaviors like attention sinks, where the first token receives most attention despite limited semantic importance, challenge our understanding of multi-head attention. To analyze this phenomenon, we propose a new definition for attention heads dominated by attention sinks, known as dormant attention heads. We compare our definition to prior work in a model intervention study where we test whether dormant heads matter for inference by zeroing out the output of dormant attention heads. Using six pretrained models and five benchmark datasets, we find our definition to be more model and dataset-agnostic. Using our definition on most models, more than 4% of a model's attention heads can be zeroed while maintaining average accuracy, and zeroing more than 14% of a model's attention heads can keep accuracy to within 1% of the pretrained model's average accuracy. Further analysis reveals that dormant heads emerge early in pretraining and can transition between dormant and active states during pretraining. Additionally, we provide evidence that they depend on characteristics of the input text.