 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Pre-training of MoEs: How robust is your router?
Mar 06, 2025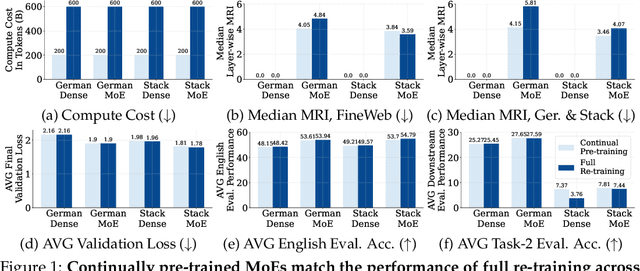
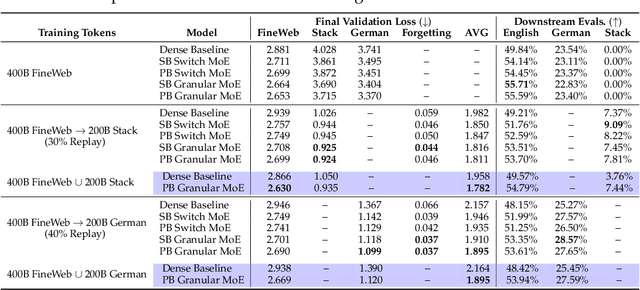
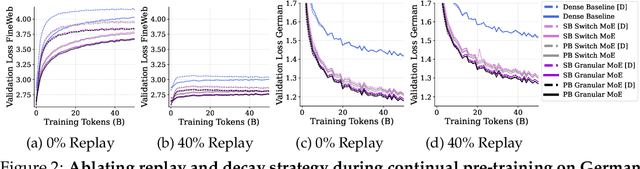
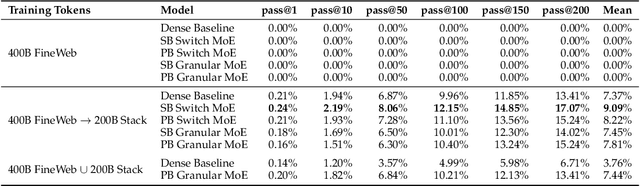
Sparsely-activated Mixture of Experts (MoE) transformers are promising architectures for foundation models. Compared to dense transformers that require the same amount of floating point operations (FLOPs) per forward pass, MoEs benefit from improved sample efficiency at training time and achieve much stronger performance. Many closed-source and open-source frontier language models have thus adopted an MoE architecture. Naturally, practitioners will want to extend the capabilities of these models with large amounts of newly collected data without completely re-training them. Prior work has shown that a simple combination of replay and learning rate re-warming and re-decaying can enable the continual pre-training (CPT) of dense decoder-only transformers with minimal performance degradation compared to full re-training. In the case of decoder-only MoE transformers, however, it is unclear how the routing algorithm will impact continual pre-training performance: 1) do the MoE transformer's routers exacerbate forgetting relative to a dense model?; 2) do the routers maintain a balanced load on previous distributions after CPT?; 3) are the same strategies applied to dense models sufficient to continually pre-train MoE LLMs? In what follows, we conduct a large-scale (>2B parameter switch and DeepSeek MoE LLMs trained for 600B tokens) empirical study across four MoE transformers to answer these questions. Our results establish a surprising robustness to distribution shifts for both Sinkhorn-Balanced and Z-and-Aux-loss-balanced routing algorithms, even in MoEs continually pre-trained without replay. Moreover, we show that MoE LLMs maintain their sample efficiency (relative to a FLOP-matched dense model) during CPT and that they can match the performance of a fully re-trained MoE at a fraction of the cost.
$μ$LO: Compute-Efficient Meta-Generalization of Learned Optimizers
May 31, 2024



Learned optimizers (LOs) can significantly reduce the wall-clock training time of neural networks, substantially reducing training costs. However, they often suffer from poor meta-generalization, especially when training networks larger than those seen during meta-training. To address this, we use the recently proposed Maximal Update Parametrization ($\mu$P), which allows zero-shot generalization of optimizer hyperparameters from smaller to larger models. We extend $\mu$P theory to learned optimizers, treating the meta-training problem as finding the learned optimizer under $\mu$P. Our evaluation shows that LOs meta-trained with $\mu$P substantially improve meta-generalization as compared to LOs trained under standard parametrization (SP). Notably, when applied to large-width models, our best $\mu$LO, trained for 103 GPU-hours, matches or exceeds the performance of VeLO, the largest publicly available learned optimizer, meta-trained with 4000 TPU-months of compute. Moreover, $\mu$LOs demonstrate better generalization than their SP counterparts to deeper networks and to much longer training horizons (25 times longer) than those seen during meta-training.
Can We Learn Communication-Efficient Optimizers?
Dec 02, 2023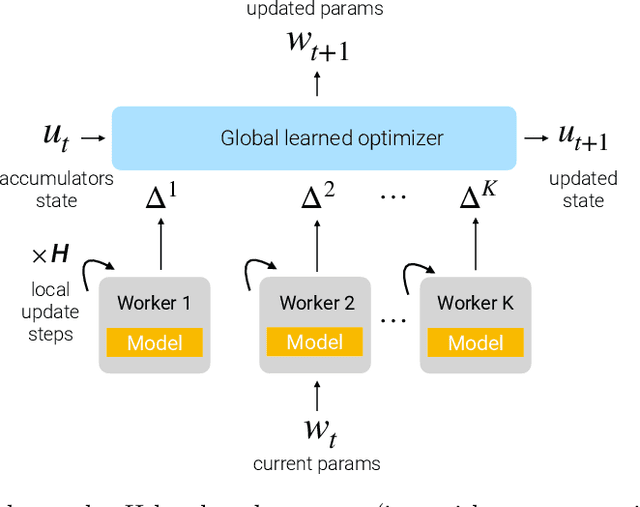

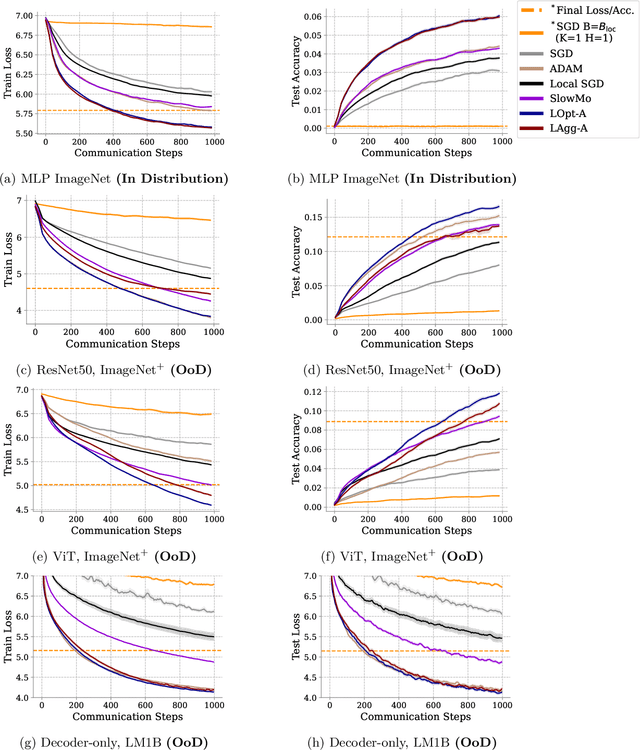
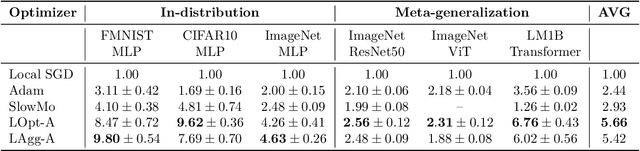
Communication-efficient variants of SGD, specifically local SGD, have received a great deal of interest in recent years. These approaches compute multiple gradient steps locally, that is on each worker, before averaging model parameters, helping relieve the critical communication bottleneck in distributed deep learning training. Although many variants of these approaches have been proposed, they can sometimes lag behind state-of-the-art adaptive optimizers for deep learning. In this work, we investigate if the recent progress in the emerging area of learned optimizers can potentially close this gap while remaining communication-efficient. Specifically, we meta-learn how to perform global updates given an update from local SGD iterations. Our results demonstrate that learned optimizers can substantially outperform local SGD and its sophisticated variants while maintaining their communication efficiency. Learned optimizers can even generalize to unseen and much larger datasets and architectures, including ImageNet and ViTs, and to unseen modalities such as language modeling. We therefore demonstrate the potential of learned optimizers for improving communication-efficient distributed learning.