 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAL-SUMMER: A Structured Evaluation Framework of Hierarchical Errors in Dialogue Summaries
Feb 08, 2026Dialogues are a predominant mode of communication for humans, and it is immensely helpful to have automatically generated summaries of them (e.g., to revise key points discussed in a meeting, to review conversations between customer agents and product users). Prior works on dialogue summary evaluation largely ignore the complexities specific to this task: (i) shift in structure, from multiple speakers discussing information in a scattered fashion across several turns, to a summary's sentences, and (ii) shift in narration viewpoint, from speakers' first/second-person narration, standardized third-person narration in the summary. In this work, we introduce our framework DIALSUMMER to address the above. We propose DIAL-SUMMER's taxonomy of errors to comprehensively evaluate dialogue summaries at two hierarchical levels: DIALOGUE-LEVEL that focuses on the broader speakers/turns, and WITHIN-TURN-LEVEL that focuses on the information talked about inside a turn. We then present DIAL-SUMMER's dataset composed of dialogue summaries manually annotated with our taxonomy's fine-grained errors. We conduct empirical analyses of these annotated errors, and observe interesting trends (e.g., turns occurring in middle of the dialogue are the most frequently missed in the summary, extrinsic hallucinations largely occur at the end of the summary). We also conduct experiments on LLM-Judges' capability at detecting these errors, through which we demonstrate the challenging nature of our dataset, the robustness of our taxonomy, and the need for future work in this field to enhance LLMs' performance in the same. Code and inference dataset coming soon.
SPEAR-MM: Selective Parameter Evaluation and Restoration via Model Merging for Efficient Financial LLM Adaptation
Nov 11, 2025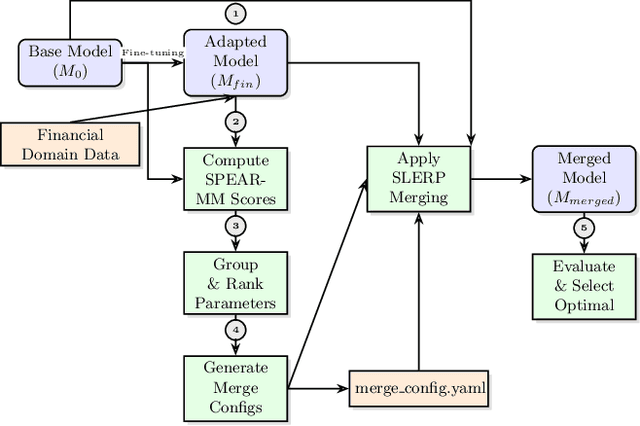


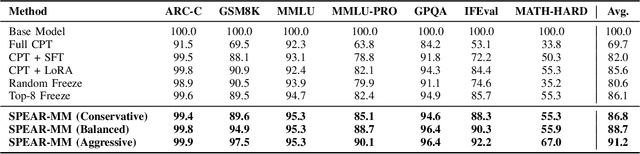
Large language models (LLMs) adapted to financial domains often suffer from catastrophic forgetting of general reasoning capabilities essential for customer interactions and complex financial analysis. We introduce Selective Parameter Evaluation and Restoration via Model Merging (SPEAR-MM), a practical framework that preserves critical capabilities while enabling domain adaptation. Our method approximates layer-wise impact on external benchmarks through post-hoc analysis, then selectively freezes or restores transformer layers via spherical interpolation merging. Applied to LLaMA-3.1-8B for financial tasks, SPEAR-MM achieves 91.2% retention of general capabilities versus 69.7% for standard continual pretraining, while maintaining 94% of domain adaptation gains. The approach provides interpretable trade-off control and reduces computational costs by 90% crucial for resource-constrained financial institutions.
Continual Pre-training of MoEs: How robust is your router?
Mar 06, 2025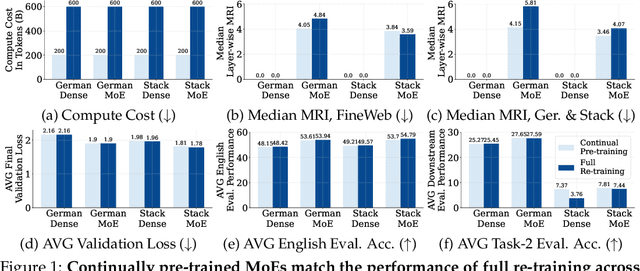
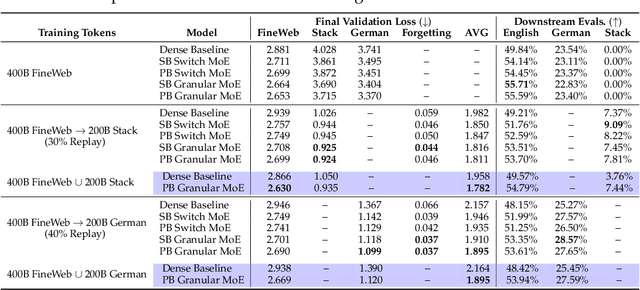
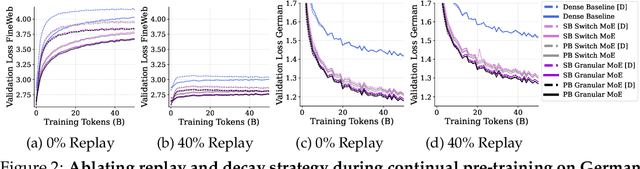
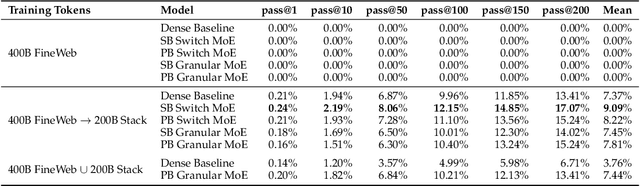
Sparsely-activated Mixture of Experts (MoE) transformers are promising architectures for foundation models. Compared to dense transformers that require the same amount of floating point operations (FLOPs) per forward pass, MoEs benefit from improved sample efficiency at training time and achieve much stronger performance. Many closed-source and open-source frontier language models have thus adopted an MoE architecture. Naturally, practitioners will want to extend the capabilities of these models with large amounts of newly collected data without completely re-training them. Prior work has shown that a simple combination of replay and learning rate re-warming and re-decaying can enable the continual pre-training (CPT) of dense decoder-only transformers with minimal performance degradation compared to full re-training. In the case of decoder-only MoE transformers, however, it is unclear how the routing algorithm will impact continual pre-training performance: 1) do the MoE transformer's routers exacerbate forgetting relative to a dense model?; 2) do the routers maintain a balanced load on previous distributions after CPT?; 3) are the same strategies applied to dense models sufficient to continually pre-train MoE LLMs? In what follows, we conduct a large-scale (>2B parameter switch and DeepSeek MoE LLMs trained for 600B tokens) empirical study across four MoE transformers to answer these questions. Our results establish a surprising robustness to distribution shifts for both Sinkhorn-Balanced and Z-and-Aux-loss-balanced routing algorithms, even in MoEs continually pre-trained without replay. Moreover, we show that MoE LLMs maintain their sample efficiency (relative to a FLOP-matched dense model) during CPT and that they can match the performance of a fully re-trained MoE at a fraction of the cost.
Translation-Enhanced Multilingual Text-to-Image Generation
May 30, 2023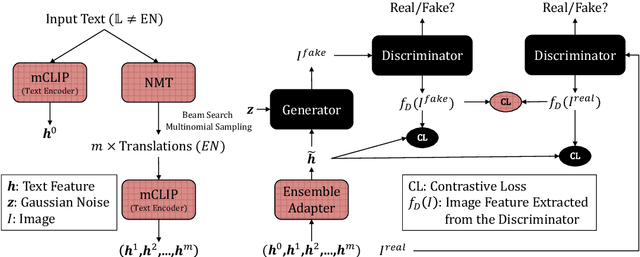
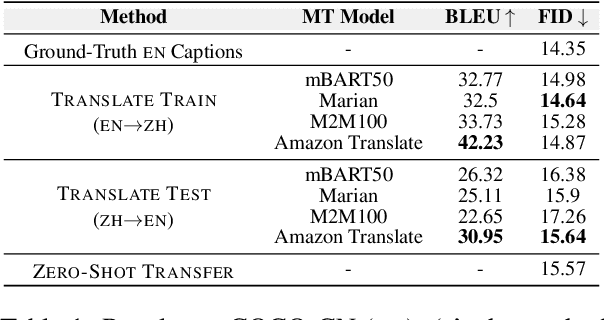
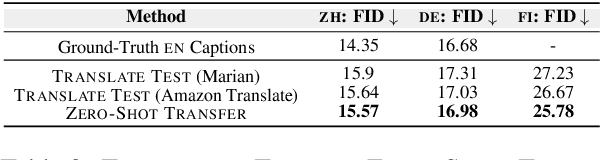

Research on text-to-image generation (TTI) still predominantly focuses on the English language due to the lack of annotated image-caption data in other languages; in the long run, this might widen inequitable access to TTI technology. In this work, we thus investigate multilingual TTI (termed mTTI) and the current potential of neural machine translation (NMT) to bootstrap mTTI systems. We provide two key contributions. 1) Relying on a multilingual multi-modal encoder, we provide a systematic empirical study of standard methods used in cross-lingual NLP when applied to mTTI: Translate Train, Translate Test, and Zero-Shot Transfer. 2) We propose Ensemble Adapter (EnsAd), a novel parameter-efficient approach that learns to weigh and consolidate the multilingual text knowledge within the mTTI framework, mitigating the language gap and thus improving mTTI performance. Our evaluations on standard mTTI datasets COCO-CN, Multi30K Task2, and LAION-5B demonstrate the potential of translation-enhanced mTTI systems and also validate the benefits of the proposed EnsAd which derives consistent gains across all datasets. Further investigations on model variants, ablation studies, and qualitative analyses provide additional insights on the inner workings of the proposed mTTI approaches.
Scalable and Accurate Self-supervised Multimodal Representation Learning without Aligned Video and Text Data
Apr 04, 2023

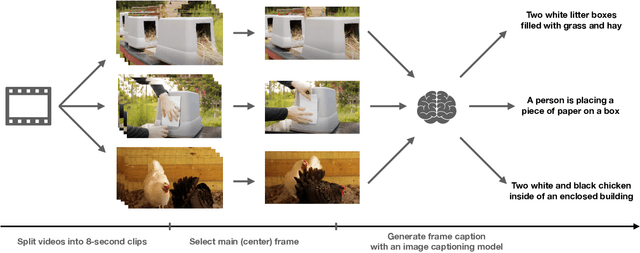

Scaling up weakly-supervised datasets has shown to be highly effective in the image-text domain and has contributed to most of the recent state-of-the-art computer vision and multimodal neural networks. However, existing large-scale video-text datasets and mining techniques suffer from several limitations, such as the scarcity of aligned data, the lack of diversity in the data, and the difficulty of collecting aligned data. Currently popular video-text data mining approach via automatic speech recognition (ASR) used in HowTo100M provides low-quality captions that often do not refer to the video content. Other mining approaches do not provide proper language descriptions (video tags) and are biased toward short clips (alt text). In this work, we show how recent advances in image captioning allow us to pre-train high-quality video models without any parallel video-text data. We pre-train several video captioning models that are based on an OPT language model and a TimeSformer visual backbone. We fine-tune these networks on several video captioning datasets. First, we demonstrate that image captioning pseudolabels work better for pre-training than the existing HowTo100M ASR captions. Second, we show that pre-training on both images and videos produces a significantly better network (+4 CIDER on MSR-VTT) than pre-training on a single modality. Our methods are complementary to the existing pre-training or data mining approaches and can be used in a variety of settings. Given the efficacy of the pseudolabeling method, we are planning to publicly release the generated captions.
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
Aug 03, 2022


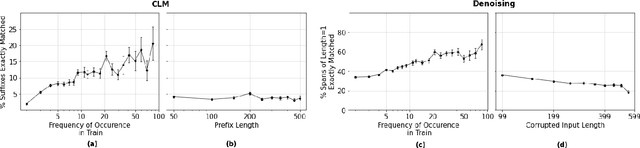
In this work, we demonstrate that multilingual large-scale sequence-to-sequence (seq2seq) models, pre-trained on a mixture of denoising and Causal Language Modeling (CLM) tasks, are more efficient few-shot learners than decoder-only models on various tasks. In particular, we train a 20 billion parameter multilingual seq2seq model called Alexa Teacher Model (AlexaTM 20B) and show that it achieves state-of-the-art (SOTA) performance on 1-shot summarization tasks, outperforming a much larger 540B PaLM decoder model. AlexaTM 20B also achieves SOTA in 1-shot machine translation, especially for low-resource languages, across almost all language pairs supported by the model (Arabic, English, French, German, Hindi, Italian, Japanese, Marathi, Portuguese, Spanish, Tamil, and Telugu) on Flores-101 dataset. We also show in zero-shot setting, AlexaTM 20B outperforms GPT3 (175B) on SuperGLUE and SQuADv2 datasets and provides SOTA performance on multilingual tasks such as XNLI, XCOPA, Paws-X, and XWinograd. Overall, our results present a compelling case for seq2seq models as a powerful alternative to decoder-only models for Large-scale Language Model (LLM) training.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022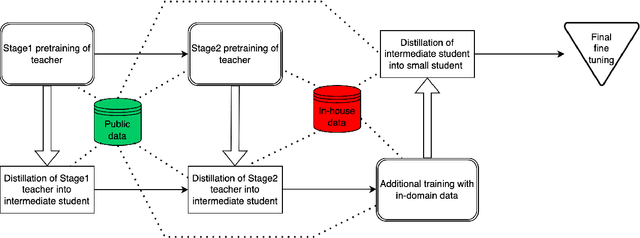
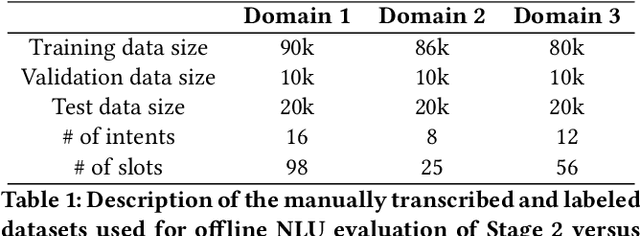
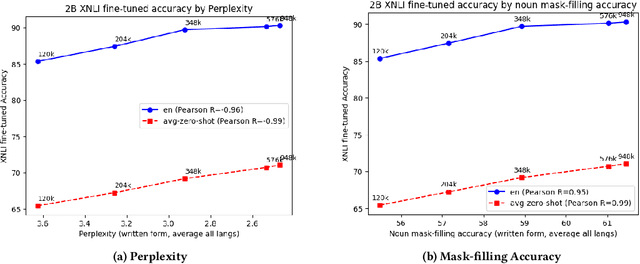
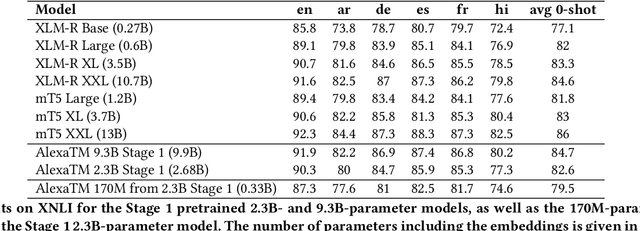
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
Don't Parse, Insert: Multilingual Semantic Parsing with Insertion Based Decoding
Oct 08, 2020
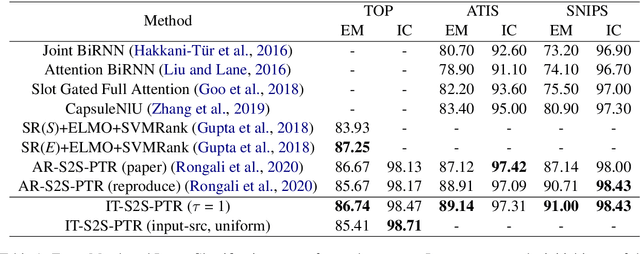


Semantic parsing is one of the key components of natural language understanding systems. A successful parse transforms an input utterance to an action that is easily understood by the system. Many algorithms have been proposed to solve this problem, from conventional rulebased or statistical slot-filling systems to shiftreduce based neural parsers. For complex parsing tasks, the state-of-the-art method is based on autoregressive sequence to sequence models to generate the parse directly. This model is slow at inference time, generating parses in O(n) decoding steps (n is the length of the target sequence). In addition, we demonstrate that this method performs poorly in zero-shot cross-lingual transfer learning settings. In this paper, we propose a non-autoregressive parser which is based on the insertion transformer to overcome these two issues. Our approach 1) speeds up decoding by 3x while outperforming the autoregressive model and 2) significantly improves cross-lingual transfer in the low-resource setting by 37% compared to autoregressive baseline. We test our approach on three well-known monolingual datasets: ATIS, SNIPS and TOP. For cross lingual semantic parsing, we use the MultiATIS++ and the multilingual TOP datasets.
Implicit Language Model in LSTM for OCR
May 23, 2018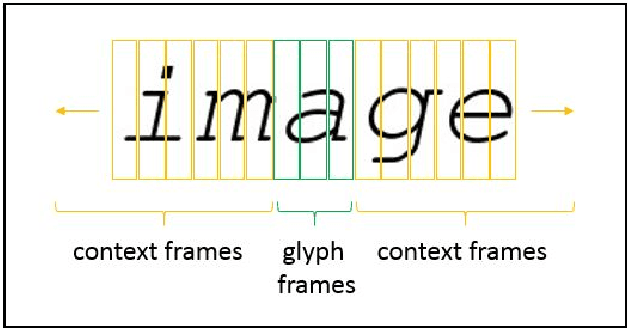
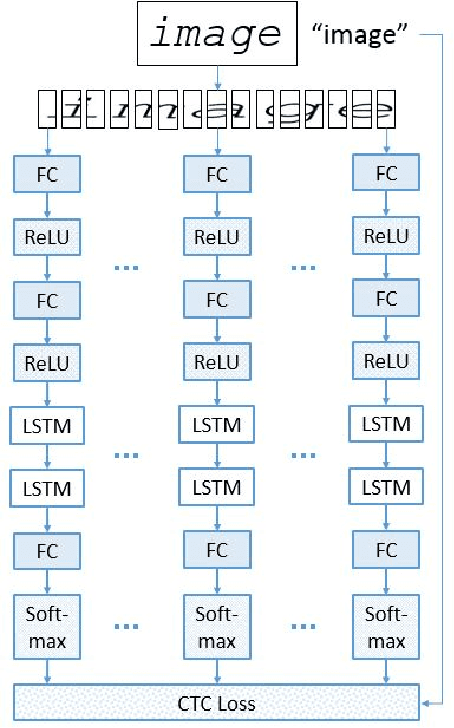
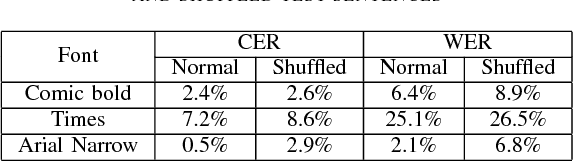
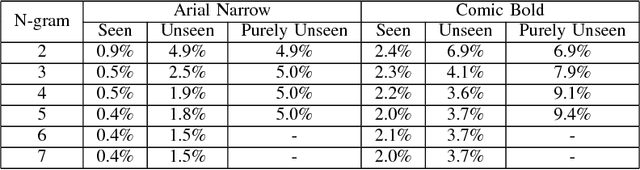
Neural networks have become the technique of choice for OCR, but many aspects of how and why they deliver superior performance are still unknown. One key difference between current neural network techniques using LSTMs and the previous state-of-the-art HMM systems is that HMM systems have a strong independence assumption. In comparison LSTMs have no explicit constraints on the amount of context that can be considered during decoding. In this paper we show that they learn an implicit LM and attempt to characterize the strength of the LM in terms of equivalent n-gram context. We show that this implicitly learned language model provides a 2.4\% CER improvement on our synthetic test set when compared against a test set of random characters (i.e. not naturally occurring sequences), and that the LSTM learns to use up to 5 characters of context (which is roughly 88 frames in our configuration). We believe that this is the first ever attempt at characterizing the strength of the implicit LM in LSTM based OCR systems.
Learning Document Image Binarization from Data
May 04, 2015



In this paper we present a fully trainable binarization solution for degraded document images. Unlike previous attempts that often used simple features with a series of pre- and post-processing, our solution encodes all heuristics about whether or not a pixel is foreground text into a high-dimensional feature vector and learns a more complicated decision function. In particular, we prepare features of three types: 1) existing features for binarization such as intensity [1], contrast [2], [3], and Laplacian [4], [5]; 2) reformulated features from existing binarization decision functions such those in [6] and [7]; and 3) our newly developed features, namely the Logarithm Intensity Percentile (LIP) and the Relative Darkness Index (RDI). Our initial experimental results show that using only selected samples (about 1.5% of all available training data), we can achieve a binarization performance comparable to those fine-tuned (typically by hand), state-of-the-art methods. Additionally, the trained document binarization classifier shows good generalization capabilities on out-of-domain data.