 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONet: Multi-scale Overlap Network for Duplication Detection in Biomedical Images
Jul 19, 2022

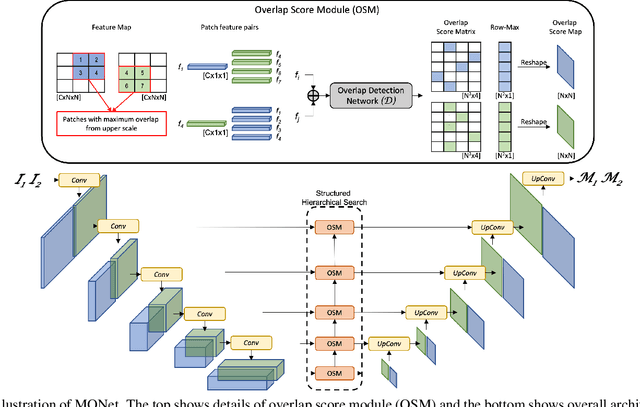
Manipulation of biomedical images to misrepresent experimental results has plagued the biomedical community for a while. Recent interest in the problem led to the curation of a dataset and associated tasks to promote the development of biomedical forensic methods. Of these, the largest manipulation detection task focuses on the detection of duplicated regions between images. Traditional computer-vision based forensic models trained on natural images are not designed to overcome the challenges presented by biomedical images. We propose a multi-scale overlap detection model to detect duplicated image regions. Our model is structured to find duplication hierarchically, so as to reduce the number of patch operations. It achieves state-of-the-art performance overall and on multiple biomedical image categories.
BioFors: A Large Biomedical Image Forensics Dataset
Aug 30, 2021
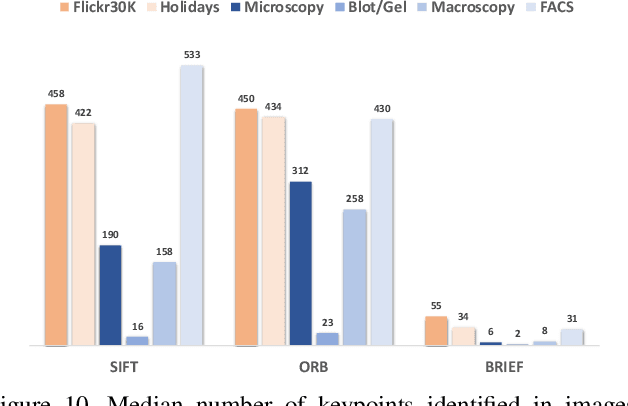

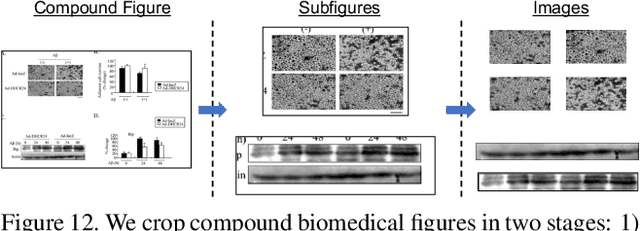
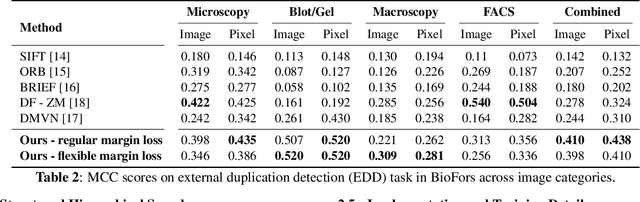
Research in media forensics has gained traction to combat the spread of misinformation. However, most of this research has been directed towards content generated on social media. Biomedical image forensics is a related problem, where manipulation or misuse of images reported in biomedical research documents is of serious concern. The problem has failed to gain momentum beyond an academic discussion due to an absence of benchmark datasets and standardized tasks. In this paper we present BioFors -- the first dataset for benchmarking common biomedical image manipulations. BioFors comprises 47,805 images extracted from 1,031 open-source research papers. Images in BioFors are divided into four categories -- Microscopy, Blot/Gel, FACS and Macroscopy. We also propose three tasks for forensic analysis -- external duplication detection, internal duplication detection and cut/sharp-transition detection. We benchmark BioFors on all tasks with suitable state-of-the-art algorithms. Our results and analysis show that existing algorithms developed on common computer vision datasets are not robust when applied to biomedical images, validating that more research is required to address the unique challenges of biomedical image forensics.
MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Nov 23, 2020
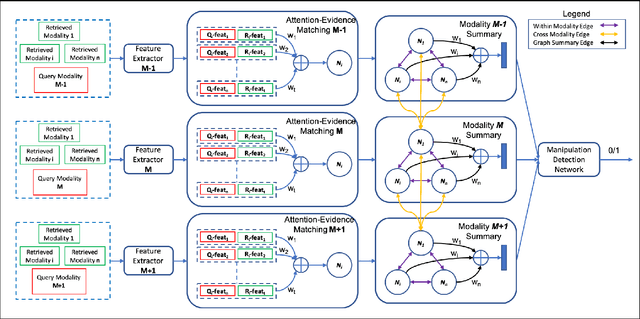


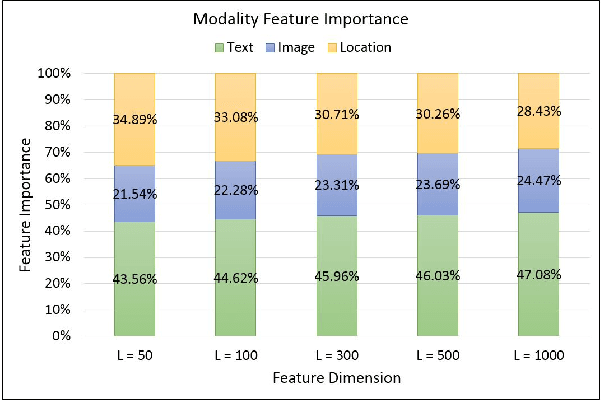
Fake news often involves semantic manipulations across modalities such as image, text, location etc and requires the development of multimodal semantic forensics for its detection. Recent research has centered the problem around images, calling it image repurposing -- where a digitally unmanipulated image is semantically misrepresented by means of its accompanying multimodal metadata such as captions, location, etc. The image and metadata together comprise a multimedia package. The problem setup requires algorithms to perform multimodal semantic forensics to authenticate a query multimedia package using a reference dataset of potentially related packages as evidences. Existing methods are limited to using a single evidence (retrieved package), which ignores potential performance improvement from the use of multiple evidences. In this work, we introduce a novel graph neural network based model for multimodal semantic forensics, which effectively utilizes multiple retrieved packages as evidences and is scalable with the number of evidences. We compare the scalability and performance of our model against existing methods. Experimental results show that the proposed model outperforms existing state-of-the-art algorithms with an error reduction of up to 25%.
CORD19STS: COVID-19 Semantic Textual Similarity Dataset
Jul 05, 2020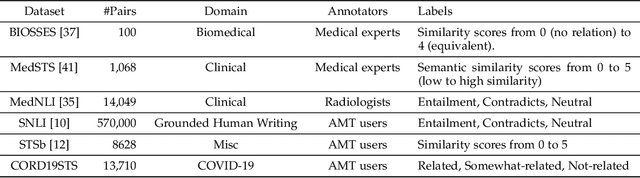


In order to combat the COVID-19 pandemic, society can benefit from various natural language processing applications, such as dialog medical diagnosis systems and information retrieval engines calibrated specifically for COVID-19. These applications rely on the ability to measure semantic textual similarity (STS), making STS a fundamental task that can benefit several downstream applications. However, existing STS datasets and models fail to translate their performance to a domain-specific environment such as COVID-19. To overcome this gap, we introduce CORD19STS dataset which includes 13,710 annotated sentence pairs collected from COVID-19 open research dataset (CORD-19) challenge. To be specific, we generated one million sentence pairs using different sampling strategies. We then used a finetuned BERT-like language model, which we call Sen-SCI-CORD19-BERT, to calculate the similarity scores between sentence pairs to provide a balanced dataset with respect to the different semantic similarity levels, which gives us a total of 32K sentence pairs. Each sentence pair was annotated by five Amazon Mechanical Turk (AMT) crowd workers, where the labels represent different semantic similarity levels between the sentence pairs (i.e. related, somewhat-related, and not-related). After employing a rigorous qualification tasks to verify collected annotations, our final CORD19STS dataset includes 13,710 sentence pairs.
Recurrent Convolutional Strategies for Face Manipulation Detection in Videos
May 16, 2019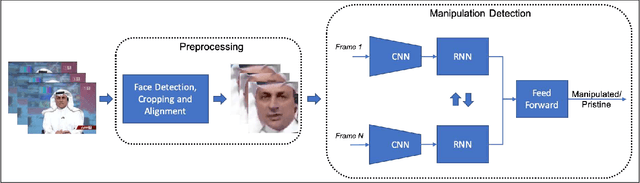
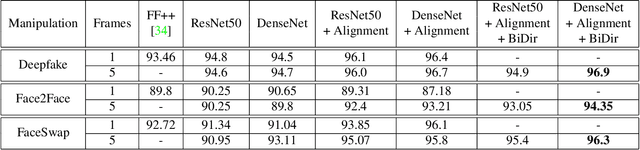
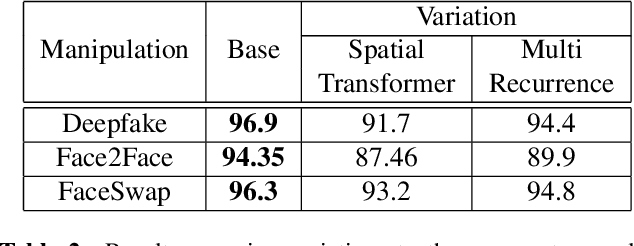
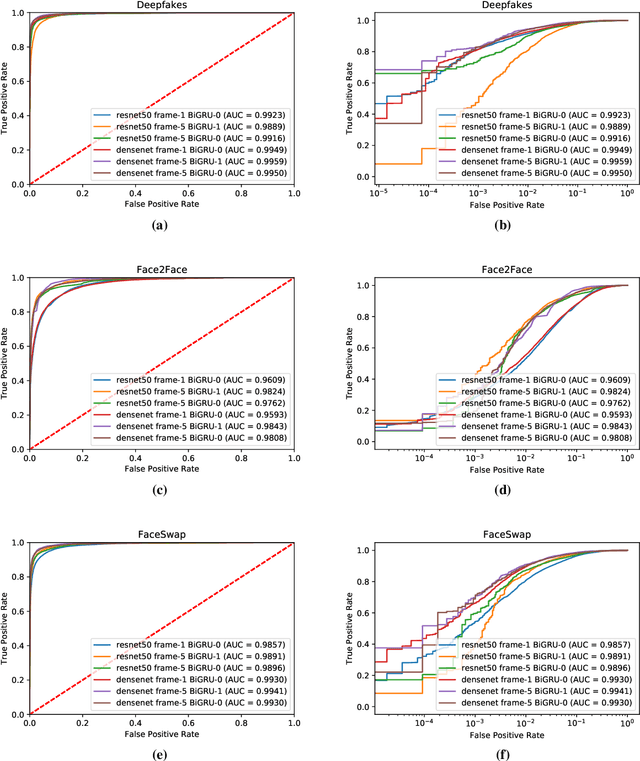
The spread of misinformation through synthetically generated yet realistic images and videos has become a significant problem, calling for robust manipulation detection methods. Despite the predominant effort of detecting face manipulation in still images, less attention has been paid to the identification of tampered faces in videos by taking advantage of the temporal information present in the stream. Recurrent convolutional models are a class of deep learning models which have proven effective at exploiting the temporal information from image streams across domains. We thereby distill the best strategy for combining variations in these models along with domain specific face preprocessing techniques through extensive experimentation to obtain state-of-the-art performance on publicly available video-based facial manipulation benchmarks. Specifically, we attempt to detect Deepfake, Face2Face and FaceSwap tampered faces in video streams. Evaluation is performed on the recently introduced FaceForensics++ dataset, improving the previous state-of-the-art by up to 4.55% in accuracy.
Policy Design for Active Sequential Hypothesis Testing using Deep Learning
Oct 11, 2018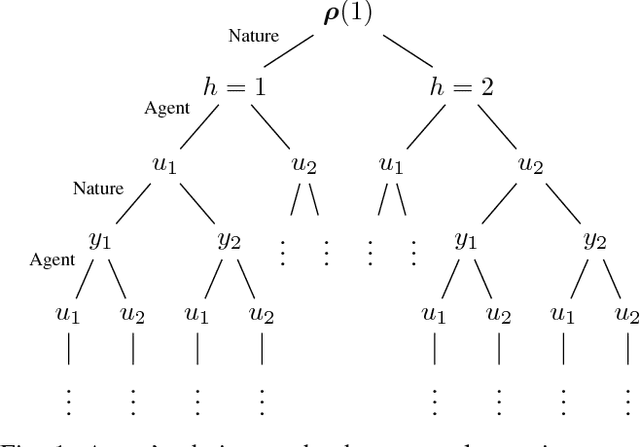
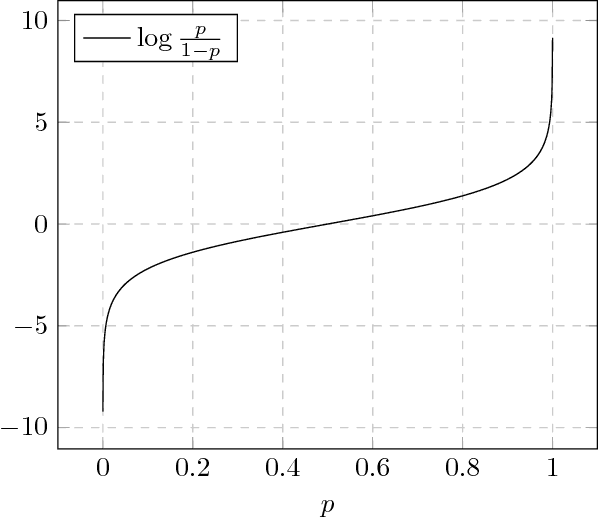
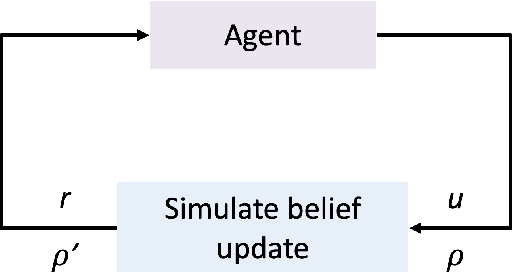
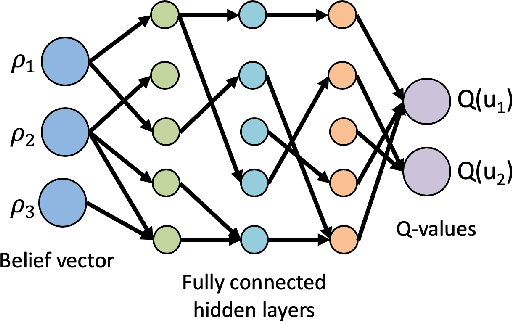
Information theory has been very successful in obtaining performance limits for various problems such as communication, compression and hypothesis testing. Likewise, stochastic control theory provides a characterization of optimal policies for Partially Observable Markov Decision Processes (POMDPs) using dynamic programming. However, finding optimal policies for these problems is computationally hard in general and thus, heuristic solutions are employed in practice. Deep learning can be used as a tool for designing better heuristics in such problems. In this paper, the problem of active sequential hypothesis testing is considered. The goal is to design a policy that can reliably infer the true hypothesis using as few samples as possible by adaptively selecting appropriate queries. This problem can be modeled as a POMDP and bounds on its value function exist in literature. However, optimal policies have not been identified and various heuristics are used. In this paper, two new heuristics are proposed: one based on deep reinforcement learning and another based on a KL-divergence zero-sum game. These heuristics are compared with state-of-the-art solutions and it is demonstrated using numerical experiments that the proposed heuristics can achieve significantly better performance than existing methods in some scenarios.
Deep Multimodal Image-Repurposing Detection
Aug 20, 2018

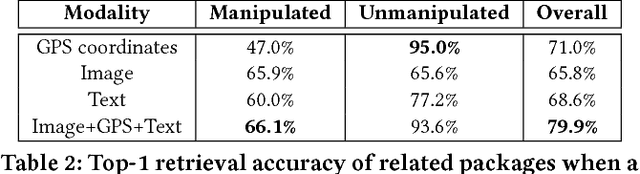
Nefarious actors on social media and other platforms often spread rumors and falsehoods through images whose metadata (e.g., captions) have been modified to provide visual substantiation of the rumor/falsehood. This type of modification is referred to as image repurposing, in which often an unmanipulated image is published along with incorrect or manipulated metadata to serve the actor's ulterior motives. We present the Multimodal Entity Image Repurposing (MEIR) dataset, a substantially challenging dataset over that which has been previously available to support research into image repurposing detection. The new dataset includes location, person, and organization manipulations on real-world data sourced from Flickr. We also present a novel, end-to-end, deep multimodal learning model for assessing the integrity of an image by combining information extracted from the image with related information from a knowledge base. The proposed method is compared against state-of-the-art techniques on existing datasets as well as MEIR, where it outperforms existing methods across the board, with AUC improvement up to 0.23.
Multimedia Semantic Integrity Assessment Using Joint Embedding Of Images And Text
Jun 29, 2018

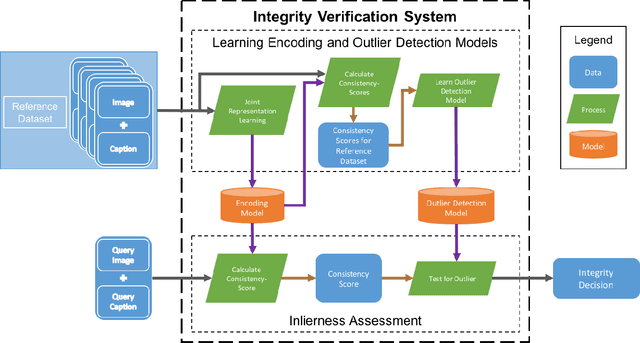

Real world multimedia data is often composed of multiple modalities such as an image or a video with associated text (e.g. captions, user comments, etc.) and metadata. Such multimodal data packages are prone to manipulations, where a subset of these modalities can be altered to misrepresent or repurpose data packages, with possible malicious intent. It is, therefore, important to develop methods to assess or verify the integrity of these multimedia packages. Using computer vision and natural language processing methods to directly compare the image (or video) and the associated caption to verify the integrity of a media package is only possible for a limited set of objects and scenes. In this paper, we present a novel deep learning-based approach for assessing the semantic integrity of multimedia packages containing images and captions, using a reference set of multimedia packages. We construct a joint embedding of images and captions with deep multimodal representation learning on the reference dataset in a framework that also provides image-caption consistency scores (ICCSs). The integrity of query media packages is assessed as the inlierness of the query ICCSs with respect to the reference dataset. We present the MultimodAl Information Manipulation dataset (MAIM), a new dataset of media packages from Flickr, which we make available to the research community. We use both the newly created dataset as well as Flickr30K and MS COCO datasets to quantitatively evaluate our proposed approach. The reference dataset does not contain unmanipulated versions of tampered query packages. Our method is able to achieve F1 scores of 0.75, 0.89 and 0.94 on MAIM, Flickr30K and MS COCO, respectively, for detecting semantically incoherent media packages.
* *Ayush Jaiswal and Ekraam Sabir contributed equally to the work in this paper
Implicit Language Model in LSTM for OCR
May 23, 2018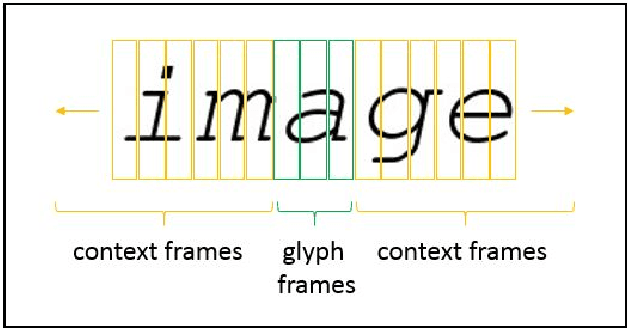
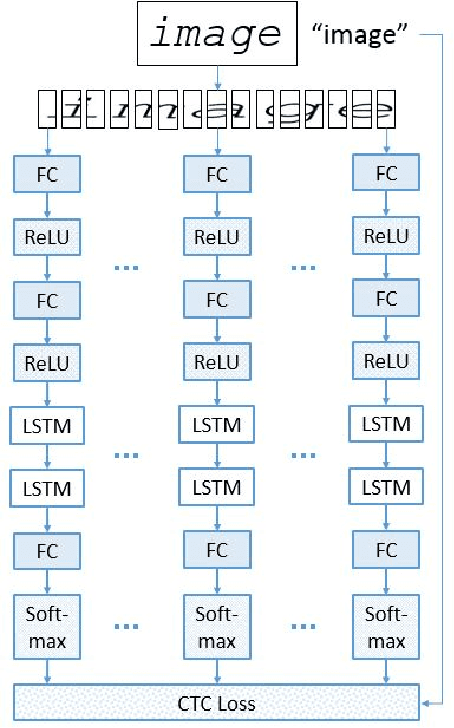
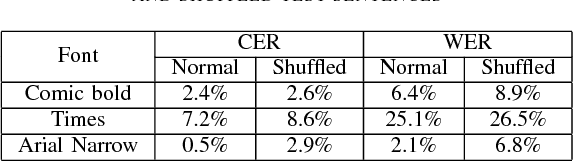
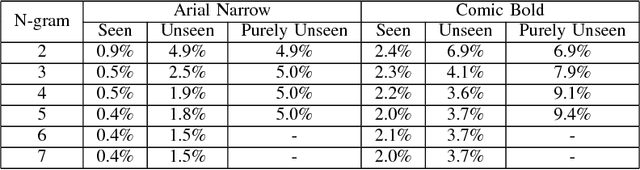
Neural networks have become the technique of choice for OCR, but many aspects of how and why they deliver superior performance are still unknown. One key difference between current neural network techniques using LSTMs and the previous state-of-the-art HMM systems is that HMM systems have a strong independence assumption. In comparison LSTMs have no explicit constraints on the amount of context that can be considered during decoding. In this paper we show that they learn an implicit LM and attempt to characterize the strength of the LM in terms of equivalent n-gram context. We show that this implicitly learned language model provides a 2.4\% CER improvement on our synthetic test set when compared against a test set of random characters (i.e. not naturally occurring sequences), and that the LSTM learns to use up to 5 characters of context (which is roughly 88 frames in our configuration). We believe that this is the first ever attempt at characterizing the strength of the implicit LM in LSTM based OCR systems.