 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook, Learn and Leverage (L$^3$): Mitigating Visual-Domain Shift and Discovering Intrinsic Relations via Symbolic Alignment
Aug 30, 2024Modern deep learning models have demonstrated outstanding performance on discovering the underlying mechanisms when both visual appearance and intrinsic relations (e.g., causal structure) data are sufficient, such as Disentangled Representation Learning (DRL), Causal Representation Learning (CRL) and Visual Question Answering (VQA) methods. However, generalization ability of these models is challenged when the visual domain shifts and the relations data is absent during finetuning. To address this challenge, we propose a novel learning framework, Look, Learn and Leverage (L$^3$), which decomposes the learning process into three distinct phases and systematically utilize the class-agnostic segmentation masks as the common symbolic space to align visual domains. Thus, a relations discovery model can be trained on the source domain, and when the visual domain shifts and the intrinsic relations are absent, the pretrained relations discovery model can be directly reused and maintain a satisfactory performance. Extensive performance evaluations are conducted on three different tasks: DRL, CRL and VQA, and show outstanding results on all three tasks, which reveals the advantages of L$^3$.
An Investigation on The Position Encoding in Vision-Based Dynamics Prediction
Aug 27, 2024Despite the success of vision-based dynamics prediction models, which predict object states by utilizing RGB images and simple object descriptions, they were challenged by environment misalignments. Although the literature has demonstrated that unifying visual domains with both environment context and object abstract, such as semantic segmentation and bounding boxes, can effectively mitigate the visual domain misalignment challenge, discussions were focused on the abstract of environment context, and the insight of using bounding box as the object abstract is under-explored. Furthermore, we notice that, as empirical results shown in the literature, even when the visual appearance of objects is removed, object bounding boxes alone, instead of being directly fed into the network, can indirectly provide sufficient position information via the Region of Interest Pooling operation for dynamics prediction. However, previous literature overlooked discussions regarding how such position information is implicitly encoded in the dynamics prediction model. Thus, in this paper, we provide detailed studies to investigate the process and necessary conditions for encoding position information via using the bounding box as the object abstract into output features. Furthermore, we study the limitation of solely using object abstracts, such that the dynamics prediction performance will be jeopardized when the environment context varies.
ManiFPT: Defining and Analyzing Fingerprints of Generative Models
Feb 29, 2024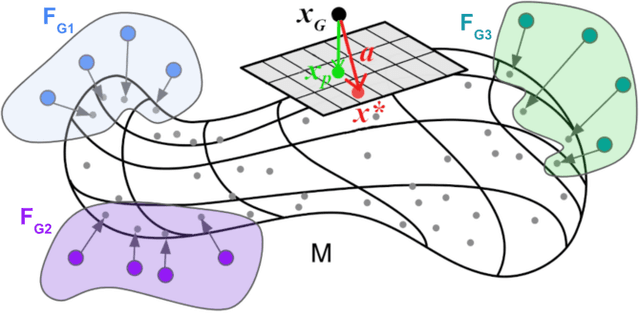
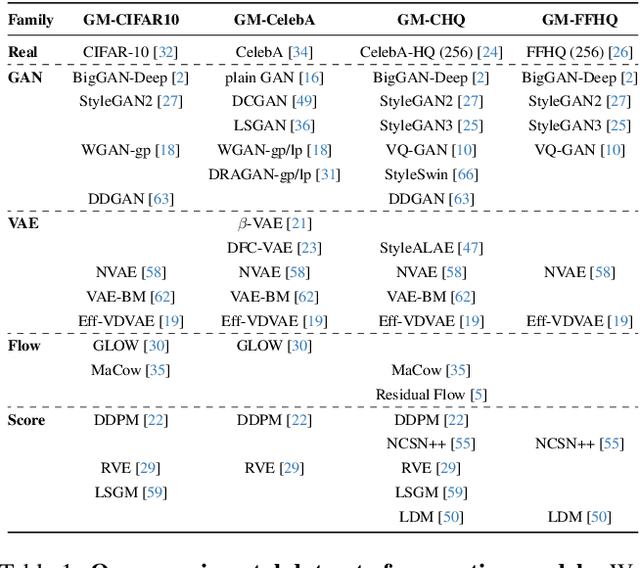
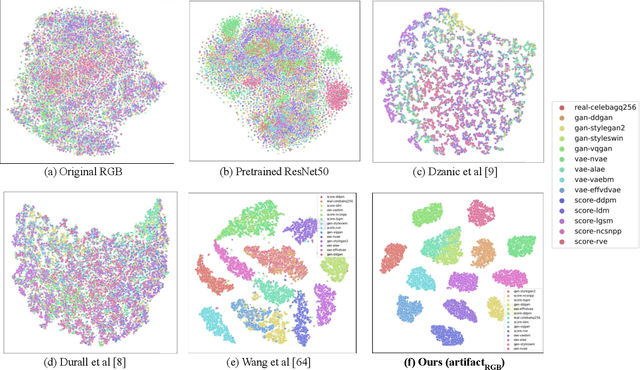
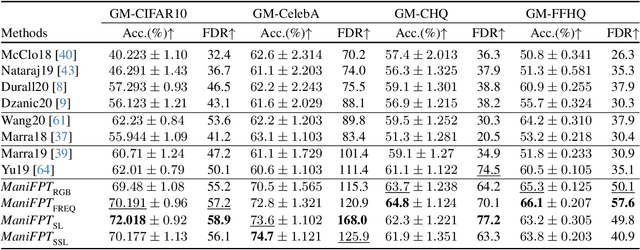
Recent works have shown that generative models leave traces of their underlying generative process on the generated samples, broadly referred to as fingerprints of a generative model, and have studied their utility in detecting synthetic images from real ones. However, the extend to which these fingerprints can distinguish between various types of synthetic image and help identify the underlying generative process remain under-explored. In particular, the very definition of a fingerprint remains unclear, to our knowledge. To that end, in this work, we formalize the definition of artifact and fingerprint in generative models, propose an algorithm for computing them in practice, and finally study its effectiveness in distinguishing a large array of different generative models. We find that using our proposed definition can significantly improve the performance on the task of identifying the underlying generative process from samples (model attribution) compared to existing methods. Additionally, we study the structure of the fingerprints, and observe that it is very predictive of the effect of different design choices on the generative process.
Unsupervised Multimodal Deepfake Detection Using Intra- and Cross-Modal Inconsistencies
Nov 28, 2023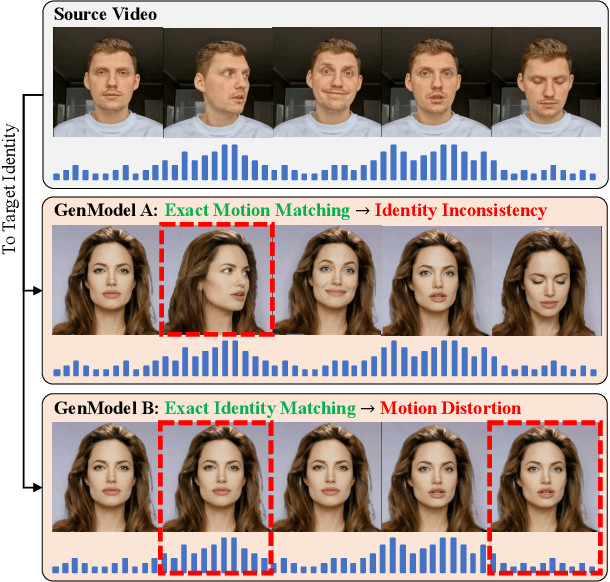
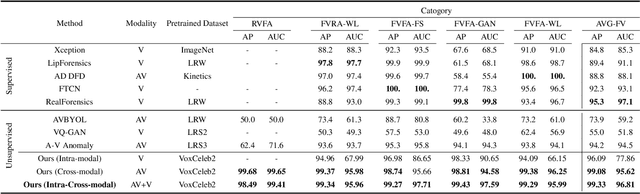
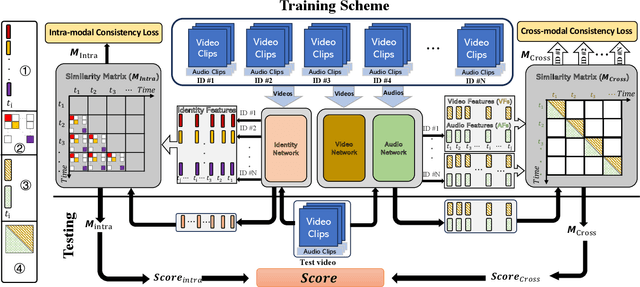
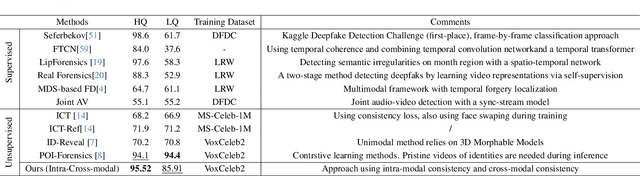
Deepfake videos present an increasing threat to society with potentially negative impact on criminal justice, democracy, and personal safety and privacy. Meanwhile, detecting deepfakes, at scale, remains a very challenging tasks that often requires labeled training data from existing deepfake generation methods. Further, even the most accurate supervised learning, deepfake detection methods do not generalize to deepfakes generated using new generation methods. In this paper, we introduce a novel unsupervised approach for detecting deepfake videos by measuring of intra- and cross-modal consistency among multimodal features; specifically visual, audio, and identity features. The fundamental hypothesis behind the proposed detection method is that since deepfake generation attempts to transfer the facial motion of one identity to another, these methods will eventually encounter a trade-off between motion and identity that enviably leads to detectable inconsistencies. We validate our method through extensive experimentation, demonstrating the existence of significant intra- and cross- modal inconsistencies in deepfake videos, which can be effectively utilized to detect them with high accuracy. Our proposed method is scalable because it does not require pristine samples at inference, generalizable because it is trained only on real data, and is explainable since it can pinpoint the exact location of modality inconsistencies which are then verifiable by a human expert.
SABAF: Removing Strong Attribute Bias from Neural Networks with Adversarial Filtering
Nov 16, 2023Ensuring a neural network is not relying on protected attributes (e.g., race, sex, age) for prediction is crucial in advancing fair and trustworthy AI. While several promising methods for removing attribute bias in neural networks have been proposed, their limitations remain under-explored. To that end, in this work, we mathematically and empirically reveal the limitation of existing attribute bias removal methods in presence of strong bias and propose a new method that can mitigate this limitation. Specifically, we first derive a general non-vacuous information-theoretical upper bound on the performance of any attribute bias removal method in terms of the bias strength, revealing that they are effective only when the inherent bias in the dataset is relatively weak. Next, we derive a necessary condition for the existence of any method that can remove attribute bias regardless of the bias strength. Inspired by this condition, we then propose a new method using an adversarial objective that directly filters out protected attributes in the input space while maximally preserving all other attributes, without requiring any specific target label. The proposed method achieves state-of-the-art performance in both strong and moderate bias settings. We provide extensive experiments on synthetic, image, and census datasets, to verify the derived theoretical bound and its consequences in practice, and evaluate the effectiveness of the proposed method in removing strong attribute bias.
Information-Theoretic Bounds on The Removal of Attribute-Specific Bias From Neural Networks
Oct 08, 2023Ensuring a neural network is not relying on protected attributes (e.g., race, sex, age) for predictions is crucial in advancing fair and trustworthy AI. While several promising methods for removing attribute bias in neural networks have been proposed, their limitations remain under-explored. In this work, we mathematically and empirically reveal an important limitation of attribute bias removal methods in presence of strong bias. Specifically, we derive a general non-vacuous information-theoretical upper bound on the performance of any attribute bias removal method in terms of the bias strength. We provide extensive experiments on synthetic, image, and census datasets to verify the theoretical bound and its consequences in practice. Our findings show that existing attribute bias removal methods are effective only when the inherent bias in the dataset is relatively weak, thus cautioning against the use of these methods in smaller datasets where strong attribute bias can occur, and advocating the need for methods that can overcome this limitation.
Shadow Datasets, New challenging datasets for Causal Representation Learning
Aug 11, 2023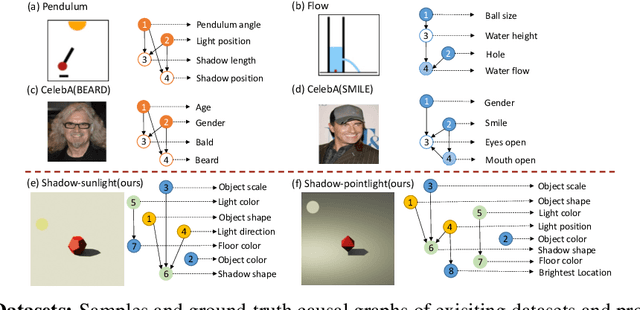
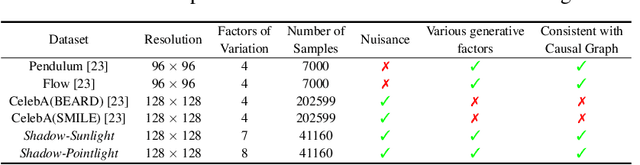

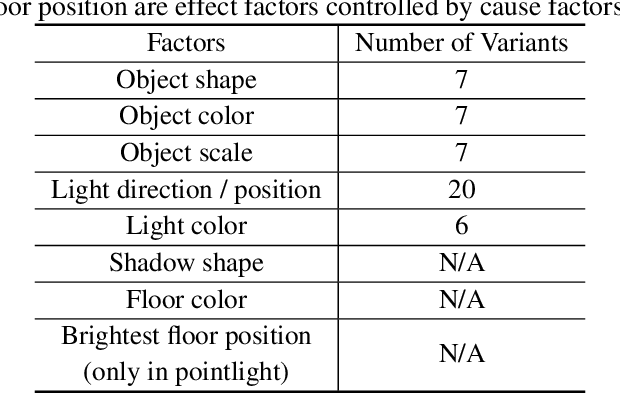
Discovering causal relations among semantic factors is an emergent topic in representation learning. Most causal representation learning (CRL) methods are fully supervised, which is impractical due to costly labeling. To resolve this restriction, weakly supervised CRL methods were introduced. To evaluate CRL performance, four existing datasets, Pendulum, Flow, CelebA(BEARD) and CelebA(SMILE), are utilized. However, existing CRL datasets are limited to simple graphs with few generative factors. Thus we propose two new datasets with a larger number of diverse generative factors and more sophisticated causal graphs. In addition, current real datasets, CelebA(BEARD) and CelebA(SMILE), the originally proposed causal graphs are not aligned with the dataset distributions. Thus, we propose modifications to them.
Emergent Asymmetry of Precision and Recall for Measuring Fidelity and Diversity of Generative Models in High Dimensions
Jun 16, 2023Precision and Recall are two prominent metrics of generative performance, which were proposed to separately measure the fidelity and diversity of generative models. Given their central role in comparing and improving generative models, understanding their limitations are crucially important. To that end, in this work, we identify a critical flaw in the common approximation of these metrics using k-nearest-neighbors, namely, that the very interpretations of fidelity and diversity that are assigned to Precision and Recall can fail in high dimensions, resulting in very misleading conclusions. Specifically, we empirically and theoretically show that as the number of dimensions grows, two model distributions with supports at equal point-wise distance from the support of the real distribution, can have vastly different Precision and Recall regardless of their respective distributions, hence an emergent asymmetry in high dimensions. Based on our theoretical insights, we then provide simple yet effective modifications to these metrics to construct symmetric metrics regardless of the number of dimensions. Finally, we provide experiments on real-world datasets to illustrate that the identified flaw is not merely a pathological case, and that our proposed metrics are effective in alleviating its impact.
Trojan Model Detection Using Activation Optimization
Jun 08, 2023Due to data's unavailability or large size, and the high computational and human labor costs of training machine learning models, it is a common practice to rely on open source pre-trained models whenever possible. However, this practice is worry some from the security perspective. Pre-trained models can be infected with Trojan attacks, in which the attacker embeds a trigger in the model such that the model's behavior can be controlled by the attacker when the trigger is present in the input. In this paper, we present our preliminary work on a novel method for Trojan model detection. Our method creates a signature for a model based on activation optimization. A classifier is then trained to detect a Trojan model given its signature. Our method achieves state of the art performance on two public datasets.
MONet: Multi-scale Overlap Network for Duplication Detection in Biomedical Images
Jul 19, 2022

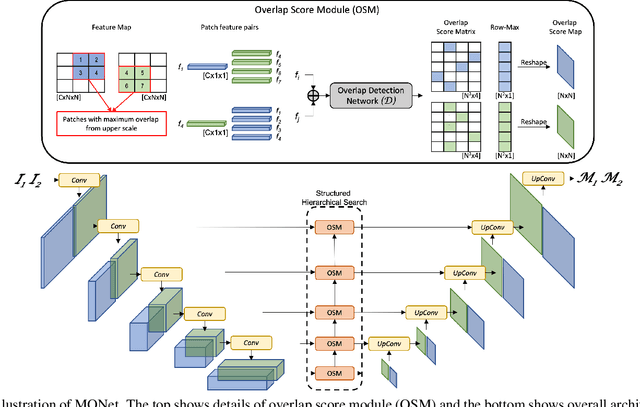
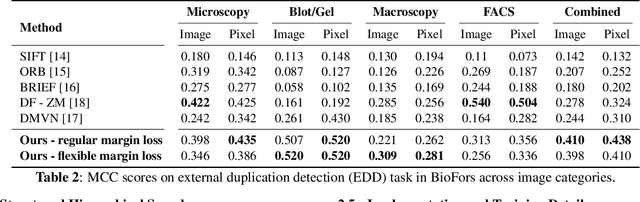
Manipulation of biomedical images to misrepresent experimental results has plagued the biomedical community for a while. Recent interest in the problem led to the curation of a dataset and associated tasks to promote the development of biomedical forensic methods. Of these, the largest manipulation detection task focuses on the detection of duplicated regions between images. Traditional computer-vision based forensic models trained on natural images are not designed to overcome the challenges presented by biomedical images. We propose a multi-scale overlap detection model to detect duplicated image regions. Our model is structured to find duplication hierarchically, so as to reduce the number of patch operations. It achieves state-of-the-art performance overall and on multiple biomedical image categories.