 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multimodal Deepfake Detection Using Intra- and Cross-Modal Inconsistencies
Paper and Code
Nov 28, 2023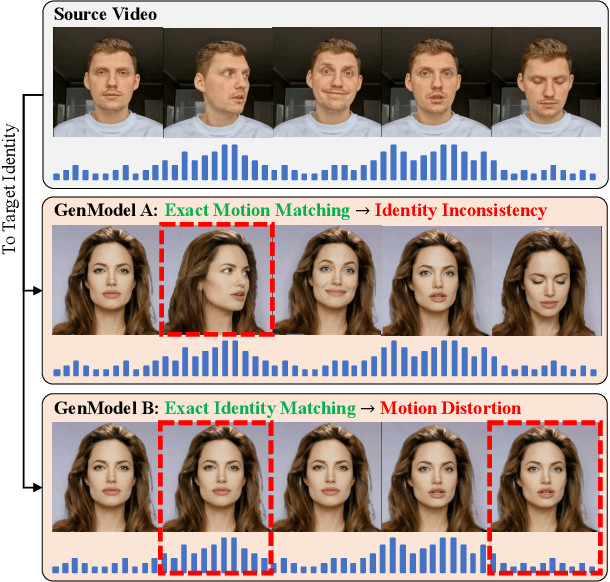
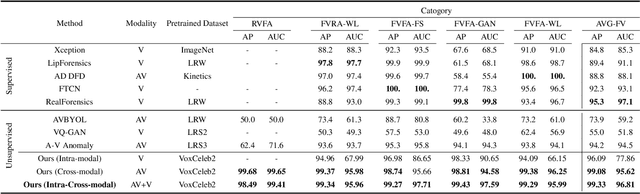
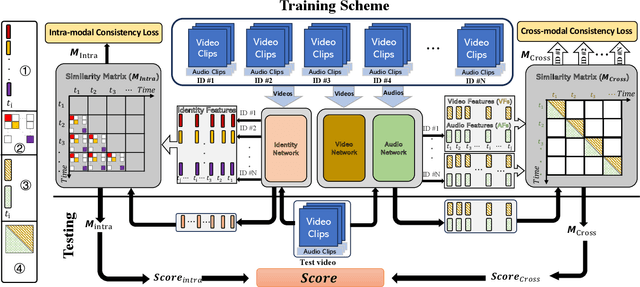
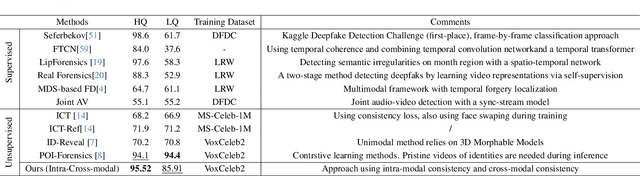
Deepfake videos present an increasing threat to society with potentially negative impact on criminal justice, democracy, and personal safety and privacy. Meanwhile, detecting deepfakes, at scale, remains a very challenging tasks that often requires labeled training data from existing deepfake generation methods. Further, even the most accurate supervised learning, deepfake detection methods do not generalize to deepfakes generated using new generation methods. In this paper, we introduce a novel unsupervised approach for detecting deepfake videos by measuring of intra- and cross-modal consistency among multimodal features; specifically visual, audio, and identity features. The fundamental hypothesis behind the proposed detection method is that since deepfake generation attempts to transfer the facial motion of one identity to another, these methods will eventually encounter a trade-off between motion and identity that enviably leads to detectable inconsistencies. We validate our method through extensive experimentation, demonstrating the existence of significant intra- and cross- modal inconsistencies in deepfake videos, which can be effectively utilized to detect them with high accuracy. Our proposed method is scalable because it does not require pristine samples at inference, generalizable because it is trained only on real data, and is explainable since it can pinpoint the exact location of modality inconsistencies which are then verifiable by a human expert.