 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multimodal Deepfake Detection Using Intra- and Cross-Modal Inconsistencies
Nov 28, 2023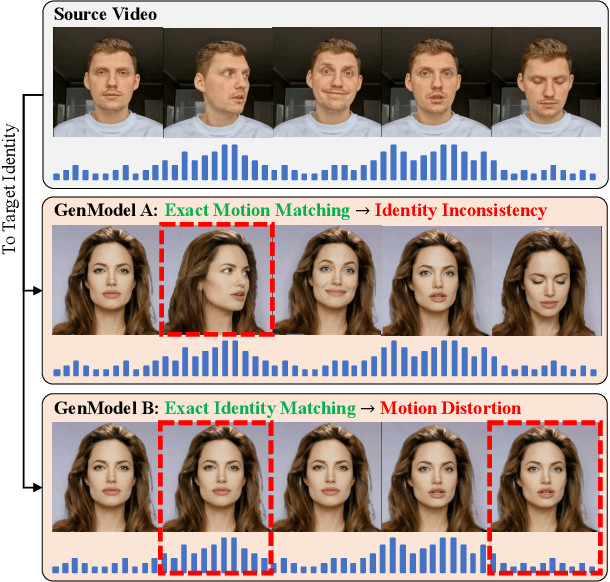
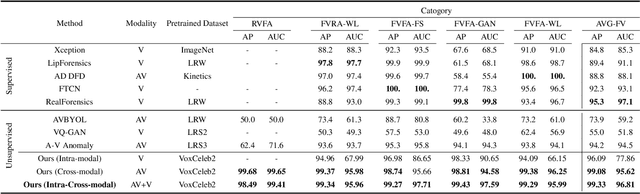
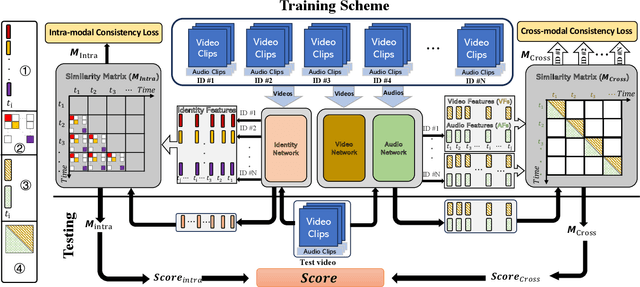
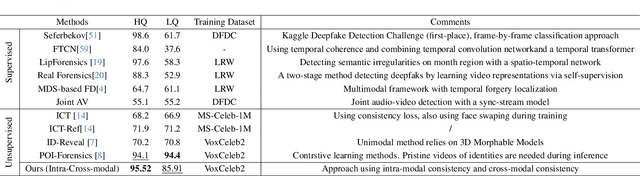
Deepfake videos present an increasing threat to society with potentially negative impact on criminal justice, democracy, and personal safety and privacy. Meanwhile, detecting deepfakes, at scale, remains a very challenging tasks that often requires labeled training data from existing deepfake generation methods. Further, even the most accurate supervised learning, deepfake detection methods do not generalize to deepfakes generated using new generation methods. In this paper, we introduce a novel unsupervised approach for detecting deepfake videos by measuring of intra- and cross-modal consistency among multimodal features; specifically visual, audio, and identity features. The fundamental hypothesis behind the proposed detection method is that since deepfake generation attempts to transfer the facial motion of one identity to another, these methods will eventually encounter a trade-off between motion and identity that enviably leads to detectable inconsistencies. We validate our method through extensive experimentation, demonstrating the existence of significant intra- and cross- modal inconsistencies in deepfake videos, which can be effectively utilized to detect them with high accuracy. Our proposed method is scalable because it does not require pristine samples at inference, generalizable because it is trained only on real data, and is explainable since it can pinpoint the exact location of modality inconsistencies which are then verifiable by a human expert.
P2M-DeTrack: Processing-in-Pixel-in-Memory for Energy-efficient and Real-Time Multi-Object Detection and Tracking
May 28, 2022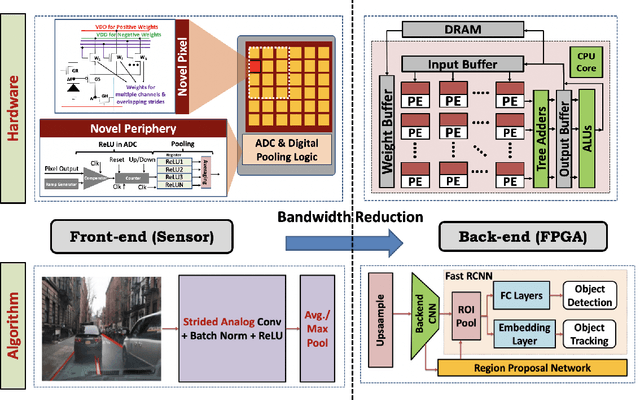
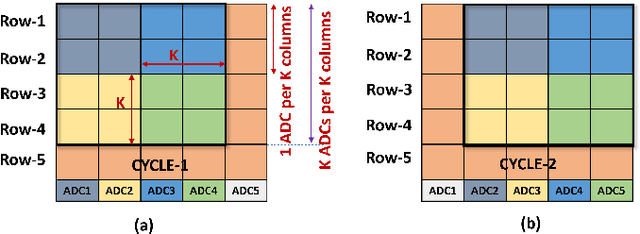
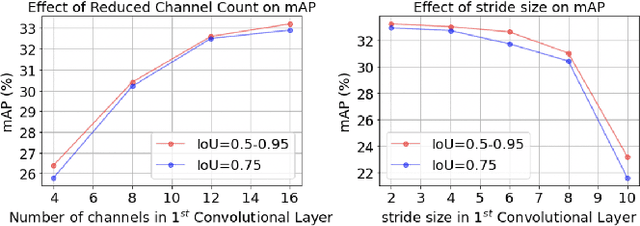
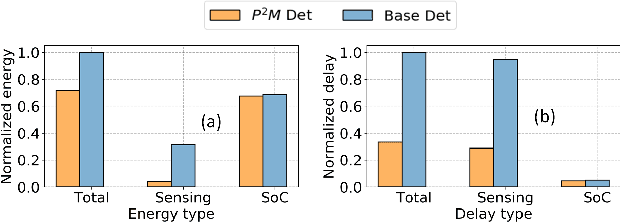
Today's high resolution, high frame rate cameras in autonomous vehicles generate a large volume of data that needs to be transferred and processed by a downstream processor or machine learning (ML) accelerator to enable intelligent computing tasks, such as multi-object detection and tracking. The massive amount of data transfer incurs significant energy, latency, and bandwidth bottlenecks, which hinders real-time processing. To mitigate this problem, we propose an algorithm-hardware co-design framework called Processing-in-Pixel-in-Memory-based object Detection and Tracking (P2M-DeTrack). P2M-DeTrack is based on a custom faster R-CNN-based model that is distributed partly inside the pixel array (front-end) and partly in a separate FPGA/ASIC (back-end). The proposed front-end in-pixel processing down-samples the input feature maps significantly with judiciously optimized strided convolution and pooling. Compared to a conventional baseline design that transfers frames of RGB pixels to the back-end, the resulting P2M-DeTrack designs reduce the data bandwidth between sensor and back-end by up to 24x. The designs also reduce the sensor and total energy (obtained from in-house circuit simulations at Globalfoundries 22nm technology node) per frame by 5.7x and 1.14x, respectively. Lastly, they reduce the sensing and total frame latency by an estimated 1.7x and 3x, respectively. We evaluate our approach on the multi-object object detection (tracking) task of the large-scale BDD100K dataset and observe only a 0.5% reduction in the mean average precision (0.8% reduction in the identification F1 score) compared to the state-of-the-art.