 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Guarantees for Clinical Reasoning in Vision Language Models via Formal Verification
Feb 27, 2026Vision-language models (VLMs) show promise in drafting radiology reports, yet they frequently suffer from logical inconsistencies, generating diagnostic impressions unsupported by their own perceptual findings or missing logically entailed conclusions. Standard lexical metrics heavily penalize clinical paraphrasing and fail to capture these deductive failures in reference-free settings. Toward guarantees for clinical reasoning, we introduce a neurosymbolic verification framework that deterministically audits the internal consistency of VLM-generated reports. Our pipeline autoformalizes free-text radiographic findings into structured propositional evidence, utilizing an SMT solver (Z3) and a clinical knowledge base to verify whether each diagnostic claim is mathematically entailed, hallucinated, or omitted. Evaluating seven VLMs across five chest X-ray benchmarks, our verifier exposes distinct reasoning failure modes, such as conservative observation and stochastic hallucination, that remain invisible to traditional metrics. On labeled datasets, enforcing solver-backed entailment acts as a rigorous post-hoc guarantee, systematically eliminating unsupported hallucinations to significantly increase diagnostic soundness and precision in generative clinical assistants.
EntroLLM: Entropy Encoded Weight Compression for Efficient Large Language Model Inference on Edge Devices
May 05, 2025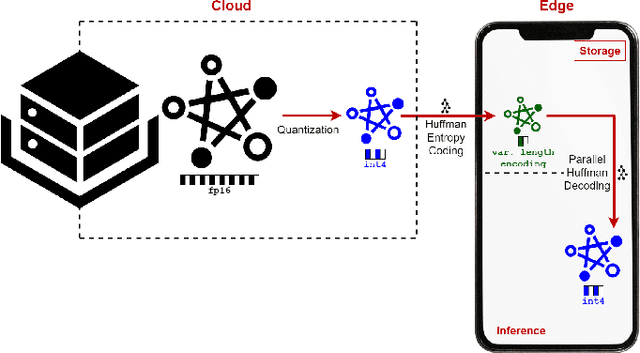

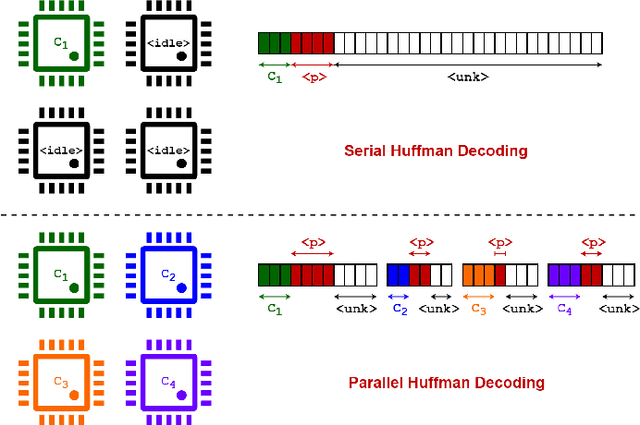
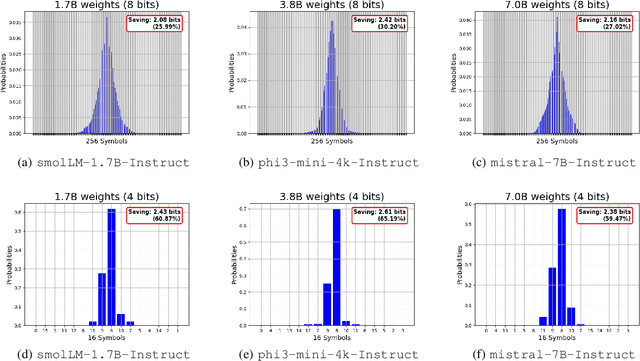
Large Language Models (LLMs) demonstrate exceptional performance across various tasks, but their large storage and computational requirements constrain their deployment on edge devices. To address this, we propose EntroLLM, a novel compression framework that integrates mixed quantization with entropy coding to reduce storage overhead while maintaining model accuracy. Our method applies a layer-wise mixed quantization scheme - choosing between symmetric and asymmetric quantization based on individual layer weight distributions - to optimize compressibility. We then employ Huffman encoding for lossless compression of the quantized weights, significantly reducing memory bandwidth requirements. Furthermore, we introduce parallel Huffman decoding, which enables efficient retrieval of encoded weights during inference, ensuring minimal latency impact. Our experiments on edge-compatible LLMs, including smolLM-1.7B-Instruct, phi3-mini-4k-Instruct, and mistral-7B-Instruct, demonstrate that EntroLLM achieves up to $30%$ storage reduction compared to uint8 models and up to $65%$ storage reduction compared to uint4 models, while preserving perplexity and accuracy, on language benchmark tasks. We further show that our method enables $31.9%$ - $146.6%$ faster inference throughput on memory-bandwidth-limited edge devices, such as NVIDIA Jetson P3450, by reducing the required data movement. The proposed approach requires no additional re-training and is fully compatible with existing post-training quantization methods, making it a practical solution for edge LLMs.
OASIS: Optimized Lightweight Autoencoder System for Distributed In-Sensor computing
May 04, 2025



In-sensor computing, which integrates computation directly within the sensor, has emerged as a promising paradigm for machine vision applications such as AR/VR and smart home systems. By processing data on-chip before transmission, it alleviates the bandwidth bottleneck caused by high-resolution, high-frame-rate image transmission, particularly in video applications. We envision a system architecture that integrates a CMOS image sensor (CIS) with a logic chip via advanced packaging, where the logic chip processes early-stage deep neural network (DNN) layers. However, its limited compute and memory make deploying advanced DNNs challenging. A simple solution is to split the model, executing the first part on the logic chip and the rest off-chip. However, modern DNNs require multiple layers before dimensionality reduction, limiting their ability to achieve the primary goal of in-sensor computing: minimizing data bandwidth. To address this, we propose a dual-branch autoencoder-based vision architecture that deploys a lightweight encoder on the logic chip while the task-specific network runs off-chip. The encoder is trained using a triple loss function: (1) task-specific loss to optimize accuracy, (2) entropy loss to enforce compact and compressible representations, and (3) reconstruction loss (mean-square error) to preserve essential visual information. This design enables a four-order-of-magnitude reduction in output activation dimensionality compared to input images, resulting in a $2{-}4.5\times$ decrease in energy consumption, as validated by our hardware-backed semi-analytical energy models. We evaluate our approach on CNN and ViT-based models across applications in smart home and augmented reality domains, achieving state-of-the-art accuracy with energy efficiency of up to 22.7 TOPS/W.
Region Masking to Accelerate Video Processing on Neuromorphic Hardware
Mar 21, 2025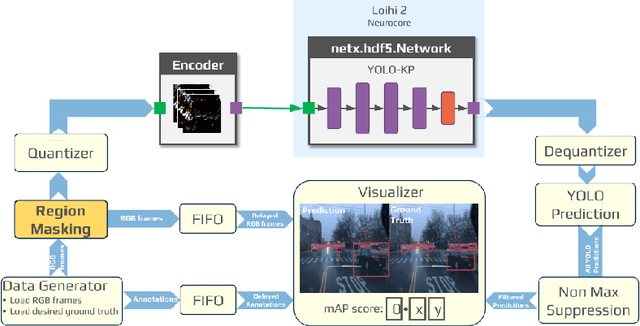
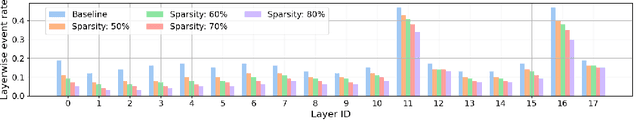
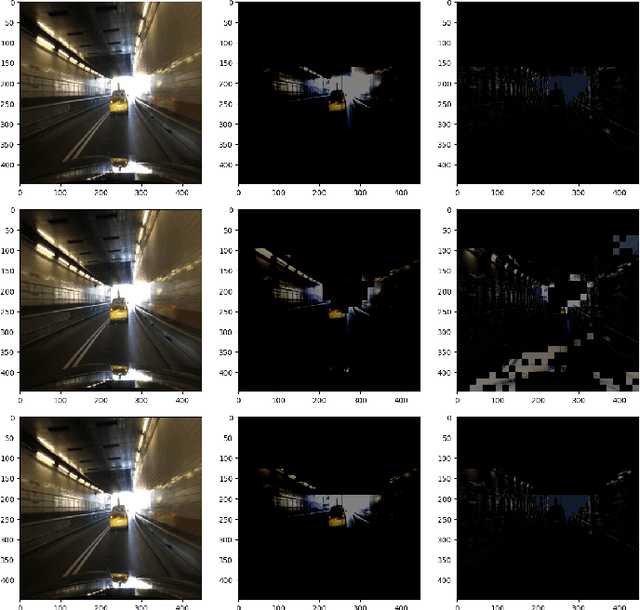
The rapidly growing demand for on-chip edge intelligence on resource-constrained devices has motivated approaches to reduce energy and latency of deep learning models. Spiking neural networks (SNNs) have gained particular interest due to their promise to reduce energy consumption using event-based processing. We assert that while sigma-delta encoding in SNNs can take advantage of the temporal redundancy across video frames, they still involve a significant amount of redundant computations due to processing insignificant events. In this paper, we propose a region masking strategy that identifies regions of interest at the input of the SNN, thereby eliminating computation and data movement for events arising from unimportant regions. Our approach demonstrates that masking regions at the input not only significantly reduces the overall spiking activity of the network, but also provides significant improvement in throughput and latency. We apply region masking during video object detection on Loihi 2, demonstrating that masking approximately 60% of input regions can reduce energy-delay product by 1.65x over a baseline sigma-delta network, with a degradation in mAP@0.5 by 1.09%.
A Pathway to Near Tissue Computing through Processing-in-CTIA Pixels for Biomedical Applications
Mar 21, 2025Near-tissue computing requires sensor-level processing of high-resolution images, essential for real-time biomedical diagnostics and surgical guidance. To address this need, we introduce a novel Capacitive Transimpedance Amplifier-based In-Pixel Computing (CTIA-IPC) architecture. Our design leverages CTIA pixels that are widely used for biomedical imaging owing to the inherent advantages of excellent linearity, low noise, and robust operation under low-light conditions. We augment CTIA pixels with IPC to enable precise deep learning computations including multi-channel, multi-bit convolution operations along with integrated batch normalization (BN) and Rectified Linear Unit (ReLU) functionalities in the peripheral ADC (Analog to Digital Converters). This design improves the linearity of Multiply and Accumulate (MAC) operations while enhancing computational efficiency. Leveraging 3D integration to embed pixel circuitry and weight storage, CTIA-IPC maintains pixel density comparable to standard CTIA designs. Moreover, our algorithm-circuit co-design approach enables efficient real-time diagnostics and AI-driven medical analysis. Evaluated on the EndoVis tissu dataset (1280x1024), CTIA-IPC achieves approximately 12x reduction in data bandwidth, yielding segmentation IoUs of 75.91% (parts), and 28.58% (instrument)-a minimal accuracy reduction (1.3%-2.5%) compared to baseline methods. Achieving 1.98 GOPS throughput and 3.39 GOPS/W efficiency, our CTIA-IPC architecture offers a promising computational framework tailored specifically for biomedical near-tissue computing.
Voltage-Controlled Magnetic Tunnel Junction based ADC-less Global Shutter Processing-in-Pixel for Extreme-Edge Intelligence
Oct 14, 2024



The vast amount of data generated by camera sensors has prompted the exploration of energy-efficient processing solutions for deploying computer vision tasks on edge devices. Among the various approaches studied, processing-in-pixel integrates massively parallel analog computational capabilities at the extreme-edge, i.e., within the pixel array and exhibits enhanced energy and bandwidth efficiency by generating the output activations of the first neural network layer rather than the raw sensory data. In this article, we propose an energy and bandwidth efficient ADC-less processing-in-pixel architecture. This architecture implements an optimized binary activation neural network trained using Hoyer regularizer for high accuracy on complex vision tasks. In addition, we also introduce a global shutter burst memory read scheme utilizing fast and disturb-free read operation leveraging innovative use of nanoscale voltage-controlled magnetic tunnel junctions (VC-MTJs). Moreover, we develop an algorithmic framework incorporating device and circuit constraints (characteristic device switching behavior and circuit non-linearity) based on state-of-the-art fabricated VC-MTJ characteristics and extensive circuit simulations using commercial GlobalFoundries 22nm FDX technology. Finally, we evaluate the proposed system's performance on two complex datasets - CIFAR10 and ImageNet, showing improvements in front-end and communication energy efficiency by 8.2x and 8.5x respectively and reduction in bandwidth by 6x compared to traditional computer vision systems, without any significant drop in the test accuracy.
Energy-Efficient & Real-Time Computer Vision with Intelligent Skipping via Reconfigurable CMOS Image Sensors
Sep 25, 2024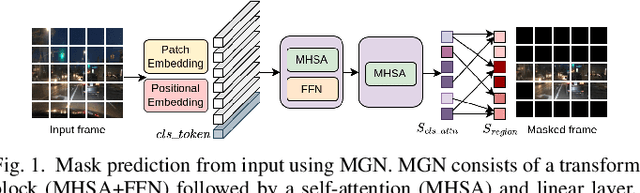
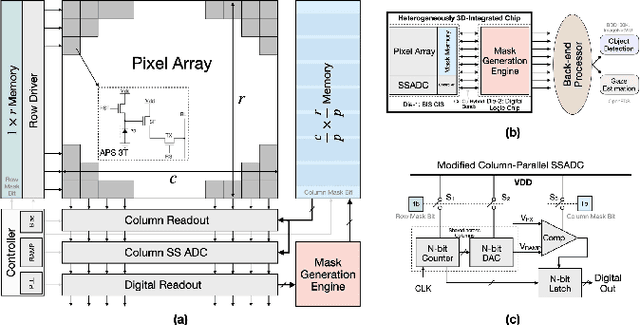
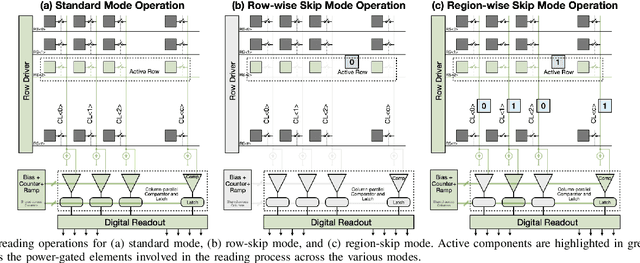
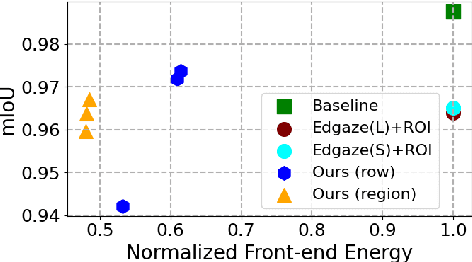
Current video-based computer vision (CV) applications typically suffer from high energy consumption due to reading and processing all pixels in a frame, regardless of their significance. While previous works have attempted to reduce this energy by skipping input patches or pixels and using feedback from the end task to guide the skipping algorithm, the skipping is not performed during the sensor read phase. As a result, these methods can not optimize the front-end sensor energy. Moreover, they may not be suitable for real-time applications due to the long latency of modern CV networks that are deployed in the back-end. To address this challenge, this paper presents a custom-designed reconfigurable CMOS image sensor (CIS) system that improves energy efficiency by selectively skipping uneventful regions or rows within a frame during the sensor's readout phase, and the subsequent analog-to-digital conversion (ADC) phase. A novel masking algorithm intelligently directs the skipping process in real-time, optimizing both the front-end sensor and back-end neural networks for applications including autonomous driving and augmented/virtual reality (AR/VR). Our system can also operate in standard mode without skipping, depending on application needs. We evaluate our hardware-algorithm co-design framework on object detection based on BDD100K and ImageNetVID, and gaze estimation based on OpenEDS, achieving up to 53% reduction in front-end sensor energy while maintaining state-of-the-art (SOTA) accuracy.
MaskVD: Region Masking for Efficient Video Object Detection
Jul 16, 2024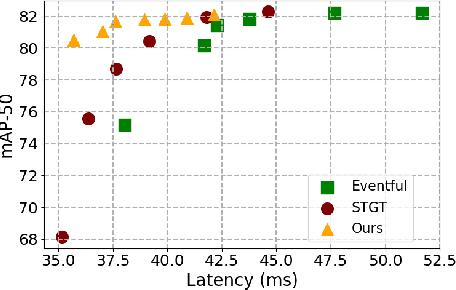
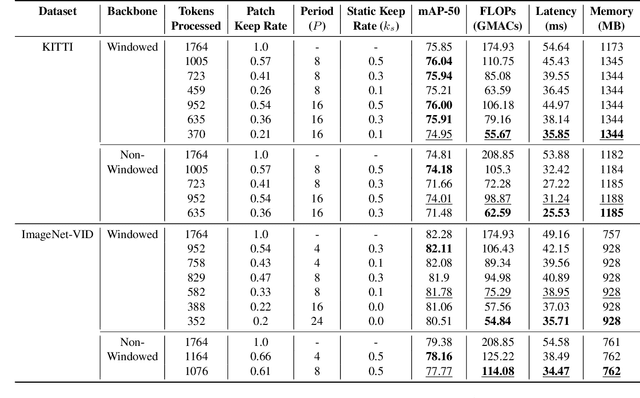
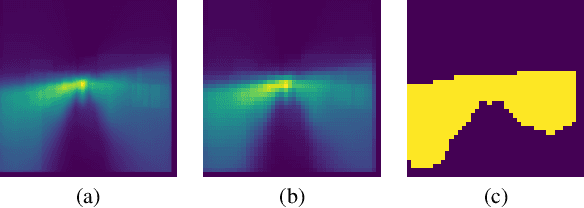
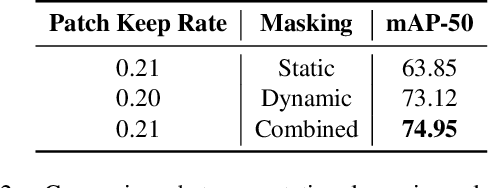
Video tasks are compute-heavy and thus pose a challenge when deploying in real-time applications, particularly for tasks that require state-of-the-art Vision Transformers (ViTs). Several research efforts have tried to address this challenge by leveraging the fact that large portions of the video undergo very little change across frames, leading to redundant computations in frame-based video processing. In particular, some works leverage pixel or semantic differences across frames, however, this yields limited latency benefits with significantly increased memory overhead. This paper, in contrast, presents a strategy for masking regions in video frames that leverages the semantic information in images and the temporal correlation between frames to significantly reduce FLOPs and latency with little to no penalty in performance over baseline models. In particular, we demonstrate that by leveraging extracted features from previous frames, ViT backbones directly benefit from region masking, skipping up to 80% of input regions, improving FLOPs and latency by 3.14x and 1.5x. We improve memory and latency over the state-of-the-art (SOTA) by 2.3x and 1.14x, while maintaining similar detection performance. Additionally, our approach demonstrates promising results on convolutional neural networks (CNNs) and provides latency improvements over the SOTA up to 1.3x using specialized computational kernels.
ReDistill: Residual Encoded Distillation for Peak Memory Reduction
Jun 07, 2024



The expansion of neural network sizes and the enhancement of image resolution through modern camera sensors result in heightened memory and power demands for neural networks. Reducing peak memory, which is the maximum memory consumed during the execution of a neural network, is critical to deploy neural networks on edge devices with limited memory budget. A naive approach to reducing peak memory is aggressive down-sampling of feature maps via pooling with large stride, which often results in unacceptable degradation in network performance. To mitigate this problem, we propose residual encoded distillation (ReDistill) for peak memory reduction in a teacher-student framework, in which a student network with less memory is derived from the teacher network using aggressive pooling. We apply our distillation method to multiple problems in computer vision including image classification and diffusion based image generation. For image classification, our method yields 2x-3.2x measured peak memory on an edge GPU with negligible degradation in accuracy for most CNN based architectures. Additionally, our method yields improved test accuracy for tiny vision transformer (ViT) based models distilled from large CNN based teacher architectures. For diffusion-based image generation, our proposed distillation method yields a denoising network with 4x lower theoretical peak memory while maintaining decent diversity and fidelity for image generation. Experiments demonstrate our method's superior performance compared to other feature-based and response-based distillation methods.
Toward High Performance, Programmable Extreme-Edge Intelligence for Neuromorphic Vision Sensors utilizing Magnetic Domain Wall Motion-based MTJ
Feb 23, 2024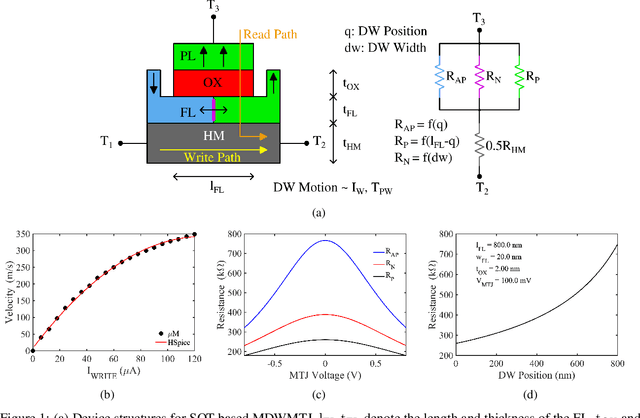
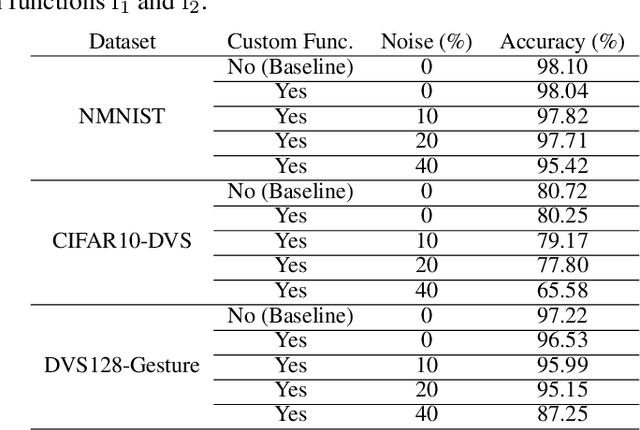
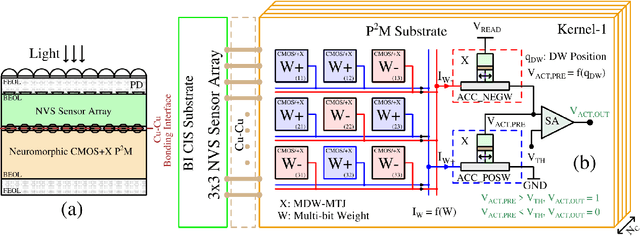
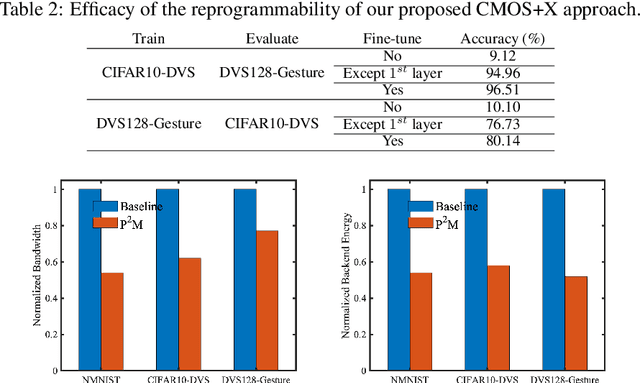
The desire to empower resource-limited edge devices with computer vision (CV) must overcome the high energy consumption of collecting and processing vast sensory data. To address the challenge, this work proposes an energy-efficient non-von-Neumann in-pixel processing solution for neuromorphic vision sensors employing emerging (X) magnetic domain wall magnetic tunnel junction (MDWMTJ) for the first time, in conjunction with CMOS-based neuromorphic pixels. Our hybrid CMOS+X approach performs in-situ massively parallel asynchronous analog convolution, exhibiting low power consumption and high accuracy across various CV applications by leveraging the non-volatility and programmability of the MDWMTJ. Moreover, our developed device-circuit-algorithm co-design framework captures device constraints (low tunnel-magnetoresistance, low dynamic range) and circuit constraints (non-linearity, process variation, area consideration) based on monte-carlo simulations and device parameters utilizing GF22nm FD-SOI technology. Our experimental results suggest we can achieve an average of 45.3% reduction in backend-processor energy, maintaining similar front-end energy compared to the state-of-the-art and high accuracy of 79.17% and 95.99% on the DVS-CIFAR10 and IBM DVS128-Gesture datasets, respectively.