 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Taylor-Lagrange Control for Safety-Critical Systems
Feb 23, 2026Solving safety-critical control problem has widely adopted the Control Barrier Function (CBF) method. However, the existence of a CBF is only a sufficient condition for system safety. The recently proposed Taylor-Lagrange Control (TLC) method addresses this limitation, but is vulnerable to the feasibility preservation problem (e.g., inter-sampling effect). In this paper, we propose a robust TLC (rTLC) method to address the feasibility preservation problem. Specifically, the rTLC method expands the safety function at an order higher than the relative degree of the function using Taylor's expansion with Lagrange remainder, which allows the control to explicitly show up at the current time instead of the future time in the TLC method. The rTLC method naturally addresses the feasibility preservation problem with only one hyper-parameter (the discretization time interval size during implementation), which is much less than its counterparts. Finally, we illustrate the effectiveness of the proposed rTLC method through an adaptive cruise control problem, and compare it with existing safety-critical control methods.
Taylor-Lagrange Control for Safety-Critical Systems
Dec 12, 2025This paper proposes a novel Taylor-Lagrange Control (TLC) method for nonlinear control systems to ensure the safety and stability through Taylor's theorem with Lagrange remainder. To achieve this, we expand a safety or stability function with respect to time along the system dynamics using the Lie derivative and Taylor's theorem. This expansion enables the control input to appear in the Taylor series at an order equivalent to the relative degree of the function. We show that the proposed TLC provides necessary and sufficient conditions for system safety and is applicable to systems and constraints of arbitrary relative degree. The TLC exhibits connections with existing Control Barrier Function (CBF) and Control Lyapunov Function (CLF) methods, and it further extends the CBF and CLF methods to the complex domain, especially for higher order cases. Compared to High-Order CBFs (HOCBFs), TLC is less restrictive as it does not require forward invariance of the intersection of a set of safe sets while HOCBFs do. We employ TLC to reformulate a constrained optimal control problem as a sequence of quadratic programs with a zero-order hold implementation method, and demonstrate the safety of zero-order hold TLC using an event-triggered control method to address inter-sampling effects. Finally, we illustrate the effectiveness of the proposed TLC method through an adaptive cruise control system and a robot control problem, and compare it with existing CBF methods.
AFLoRA: Adaptive Freezing of Low Rank Adaptation in Parameter Efficient Fine-Tuning of Large Models
Mar 20, 2024



We present a novel Parameter-Efficient Fine-Tuning (PEFT) method, dubbed as Adaptive Freezing of Low Rank Adaptation (AFLoRA). Specifically, for each pre-trained frozen weight tensor, we add a parallel path of trainable low-rank matrices, namely a down-projection and an up-projection matrix, each of which is followed by a feature transformation vector. Based on a novel freezing score, we the incrementally freeze these projection matrices during fine-tuning to reduce the computation and alleviate over-fitting. Our experimental results demonstrate that we can achieve state-of-the-art performance with an average improvement of up to $0.85\%$ as evaluated on GLUE benchmark while yeilding up to $9.5\times$ fewer average trainable parameters. While compared in terms of runtime, AFLoRA can yield up to $1.86\times$ improvement as opposed to similar PEFT alternatives. Besides the practical utility of our approach, we provide insights on the trainability requirements of LoRA paths at different modules and the freezing schedule for the different projection matrices. Code will be released.
LMUFormer: Low Complexity Yet Powerful Spiking Model With Legendre Memory Units
Jan 20, 2024
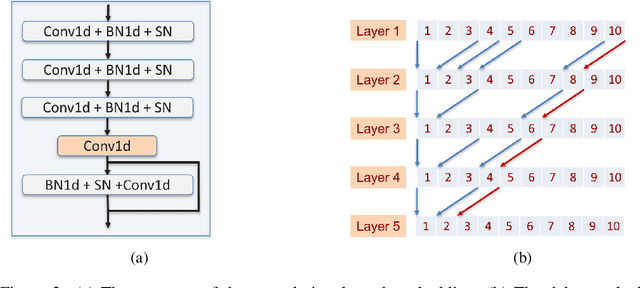
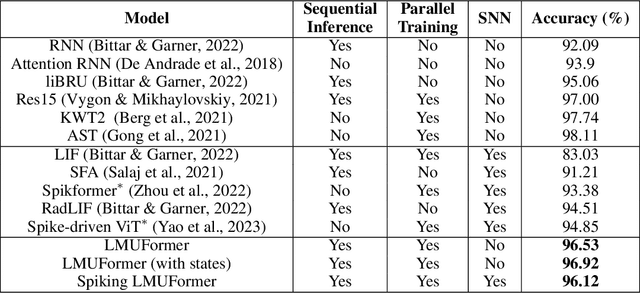
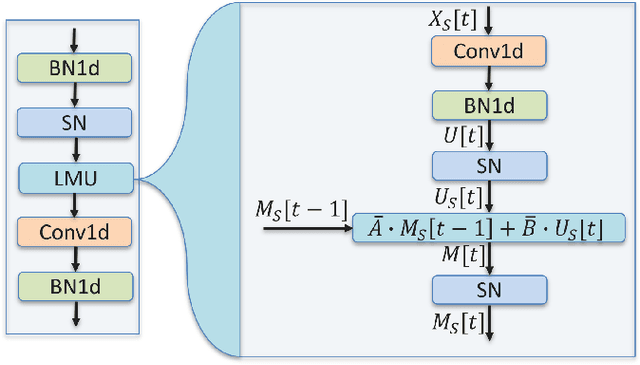
Transformer models have demonstrated high accuracy in numerous applications but have high complexity and lack sequential processing capability making them ill-suited for many streaming applications at the edge where devices are heavily resource-constrained. Thus motivated, many researchers have proposed reformulating the transformer models as RNN modules which modify the self-attention computation with explicit states. However, these approaches often incur significant performance degradation. The ultimate goal is to develop a model that has the following properties: parallel training, streaming and low-cost inference, and SOTA performance. In this paper, we propose a new direction to achieve this goal. We show how architectural modifications to a recurrent model can help push its performance toward Transformer models while retaining its sequential processing capability. Specifically, inspired by the recent success of Legendre Memory Units (LMU) in sequence learning tasks, we propose LMUFormer, which augments the LMU with convolutional patch embedding and convolutional channel mixer. Moreover, we present a spiking version of this architecture, which introduces the benefit of states within the patch embedding and channel mixer modules while simultaneously reducing the computing complexity. We evaluated our architectures on multiple sequence datasets. In comparison to SOTA transformer-based models within the ANN domain on the SCv2 dataset, our LMUFormer demonstrates comparable performance while necessitating a remarkable 53 times reduction in parameters and a substantial 65 times decrement in FLOPs. Additionally, owing to our model's proficiency in real-time data processing, we can achieve a 32.03% reduction in sequence length, all while incurring an inconsequential decline in performance. Our code is publicly available at https://github.com/zeyuliu1037/LMUFormer.git.
Induced Generative Adversarial Particle Transformers
Dec 08, 2023In high energy physics (HEP), machine learning methods have emerged as an effective way to accurately simulate particle collisions at the Large Hadron Collider (LHC). The message-passing generative adversarial network (MPGAN) was the first model to simulate collisions as point, or ``particle'', clouds, with state-of-the-art results, but suffered from quadratic time complexity. Recently, generative adversarial particle transformers (GAPTs) were introduced to address this drawback; however, results did not surpass MPGAN. We introduce induced GAPT (iGAPT) which, by integrating ``induced particle-attention blocks'' and conditioning on global jet attributes, not only offers linear time complexity but is also able to capture intricate jet substructure, surpassing MPGAN in many metrics. Our experiments demonstrate the potential of iGAPT to simulate complex HEP data accurately and efficiently.
Spiking Neural Networks with Dynamic Time Steps for Vision Transformers
Nov 28, 2023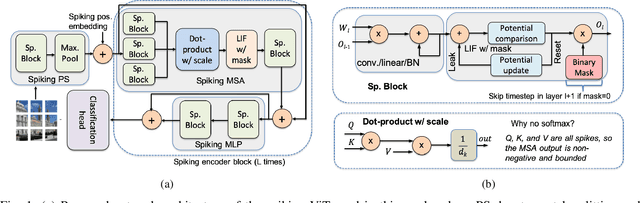
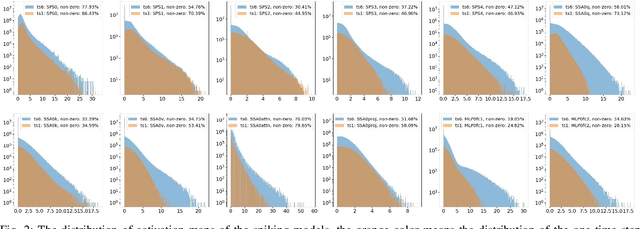
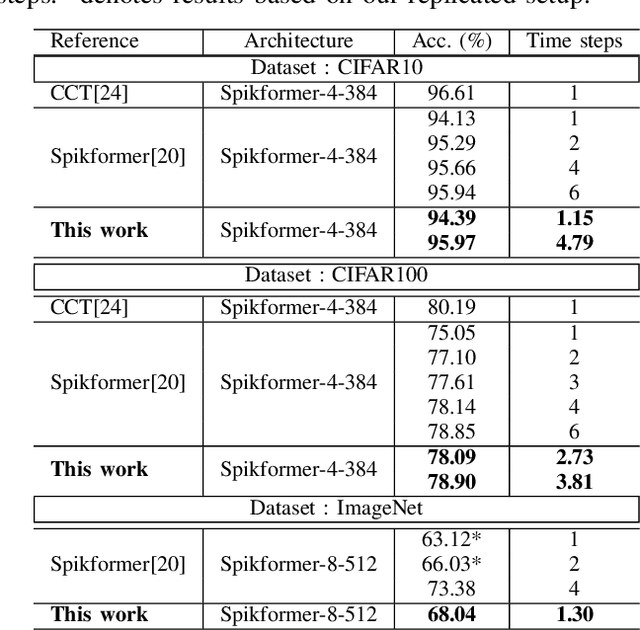
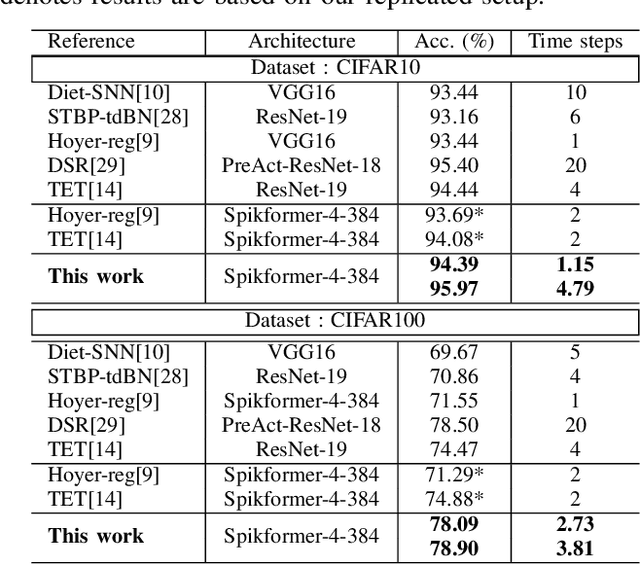
Spiking Neural Networks (SNNs) have emerged as a popular spatio-temporal computing paradigm for complex vision tasks. Recently proposed SNN training algorithms have significantly reduced the number of time steps (down to 1) for improved latency and energy efficiency, however, they target only convolutional neural networks (CNN). These algorithms, when applied on the recently spotlighted vision transformers (ViT), either require a large number of time steps or fail to converge. Based on analysis of the histograms of the ANN and SNN activation maps, we hypothesize that each ViT block has a different sensitivity to the number of time steps. We propose a novel training framework that dynamically allocates the number of time steps to each ViT module depending on a trainable score assigned to each timestep. In particular, we generate a scalar binary time step mask that filters spikes emitted by each neuron in a leaky-integrate-and-fire (LIF) layer. The resulting SNNs have high activation sparsity and require only accumulate operations (AC), except for the input embedding layer, in contrast to expensive multiply-and-accumulates (MAC) needed in traditional ViTs. This yields significant improvements in energy efficiency. We evaluate our training framework and resulting SNNs on image recognition tasks including CIFAR10, CIFAR100, and ImageNet with different ViT architectures. We obtain a test accuracy of 95.97% with 4.97 time steps with direct encoding on CIFAR10.
On the Evaluation of Generative Models in High Energy Physics
Nov 18, 2022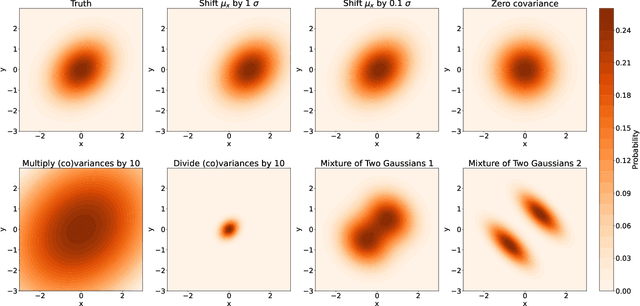
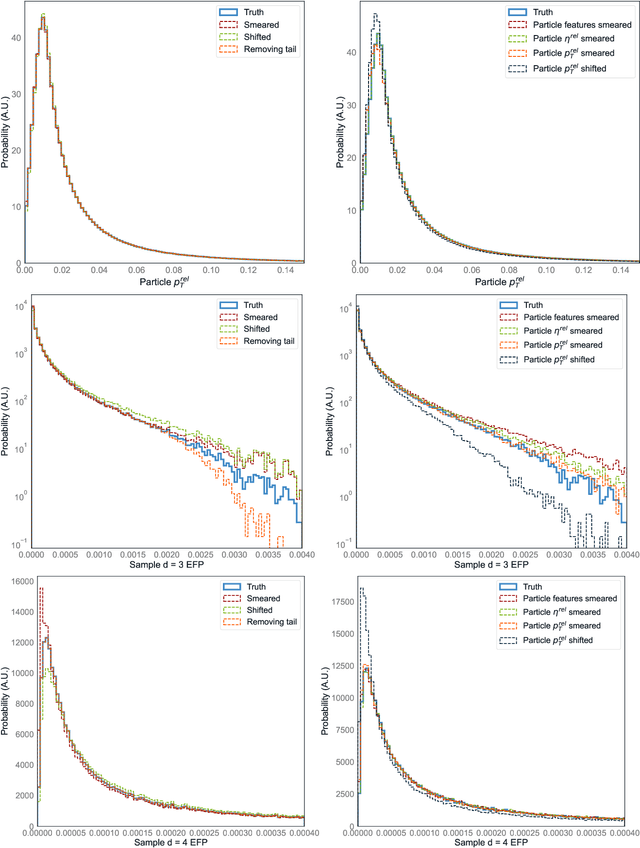
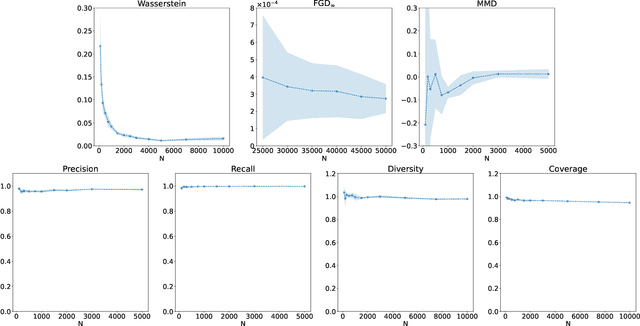
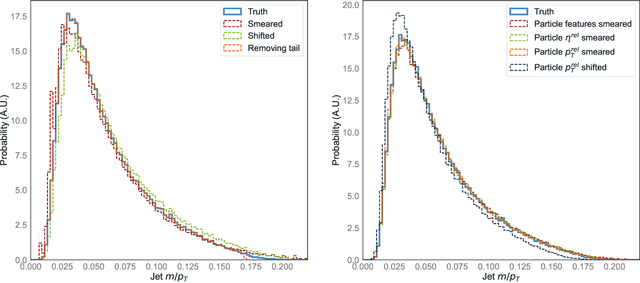
There has been a recent explosion in research into machine-learning-based generative modeling to tackle computational challenges for simulations in high energy physics (HEP). In order to use such alternative simulators in practice, we need well defined metrics to compare different generative models and evaluate their discrepancy from the true distributions. We present the first systematic review and investigation into evaluation metrics and their sensitivity to failure modes of generative models, using the framework of two-sample goodness-of-fit testing, and their relevance and viability for HEP. Inspired by previous work in both physics and computer vision, we propose two new metrics, the Fr\'echet and kernel physics distances (FPD and KPD), and perform a variety of experiments measuring their performance on simple Gaussian-distributed, and simulated high energy jet datasets. We find FPD, in particular, to be the most sensitive metric to all alternative jet distributions tested and recommend its adoption, along with the KPD and Wasserstein distances between individual feature distributions, for evaluating generative models in HEP. We finally demonstrate the efficacy of these proposed metrics in evaluating and comparing a novel attention-based generative adversarial particle transformer to the state-of-the-art message-passing generative adversarial network jet simulation model.
Cooperative Energy and Time-Optimal Lane Change Maneuvers with Minimal Highway Traffic Disruption
Nov 16, 2022



We derive optimal control policies for a Connected Automated Vehicle (CAV) and cooperating neighboring CAVs to carry out a lane change maneuver consisting of a longitudinal phase where the CAV properly positions itself relative to the cooperating neighbors and a lateral phase where it safely changes lanes. In contrast to prior work on this problem, where the CAV "selfishly" only seeks to minimize its maneuver time, we seek to ensure that the fast-lane traffic flow is minimally disrupted (through a properly defined metric). Additionally, when performing lane-changing maneuvers, we optimally select the cooperating vehicles from a set of feasible neighboring vehicles and experimentally show that the highway throughput is improved compared to the baseline case of human-driven vehicles changing lanes with no cooperation. When feasible solutions do not exist for a given maximal allowable disruption, we include a time relaxation method trading off a longer maneuver time with reduced disruption. Our analysis is also extended to multiple sequential maneuvers. Simulation results show the effectiveness of our controllers in terms of safety guarantees and up to 16% and 90% average throughput and maneuver time improvement respectively when compared to maneuvers with no cooperation.