 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Role of Hallucination in Reinforcement Post-Training of Multimodal Reasoning Models
Apr 03, 2026The recent success of reinforcement learning (RL) in large reasoning models has inspired the growing adoption of RL for post-training Multimodal Large Language Models (MLLMs) to enhance their visual reasoning capabilities. Although many studies have reported improved performance, it remains unclear whether RL training truly enables models to learn from visual information. In this work, we propose the Hallucination-as-Cue Framework, an analytical framework designed to investigate the effects of RL-based post-training on multimodal reasoning models from the perspective of model hallucination. Specifically, we introduce hallucination-inductive, modality-specific corruptions that remove or replace essential information required to derive correct answers, thereby forcing the model to reason by hallucination. By applying these corruptions during both training and evaluation, our framework provides a unique perspective for diagnosing RL training dynamics and understanding the intrinsic properties of datasets. Through extensive experiments and analyses across multiple multimodal reasoning benchmarks, we reveal that the role of model hallucination for RL-training is more significant than previously recognized. For instance, we find that RL post-training under purely hallucination-inductive settings can still significantly improve models' reasoning performance, and in some cases even outperform standard training. These findings challenge prevailing assumptions about MLLM reasoning training and motivate the development of more modality-aware RL-based training designs.
SSR: A Generic Framework for Text-Aided Map Compression for Localization
Mar 04, 2026Mapping is crucial in robotics for localization and downstream decision-making. As robots are deployed in ever-broader settings, the maps they rely on continue to increase in size. However, storing these maps indefinitely (cold storage), transferring them across networks, or sending localization queries to cloud-hosted maps imposes prohibitive memory and bandwidth costs. We propose a text-enhanced compression framework that reduces both memory and bandwidth footprints while retaining high-fidelity localization. The key idea is to treat text as an alternative modality: one that can be losslessly compressed with large language models. We propose leveraging lightweight text descriptions combined with very small image feature vectors, which capture "complementary information" as a compact representation for the mapping task. Building on this, our novel technique, Similarity Space Replication (SSR), learns an adaptive image embedding in one shot that captures only the information "complementary" to the text descriptions. We validate our compression framework on multiple downstream localization tasks, including Visual Place Recognition as well as object-centric Monte Carlo localization in both indoor and outdoor settings. SSR achieves 2 times better compression than competing baselines on state-of-the-art datasets, including TokyoVal, Pittsburgh30k, Replica, and KITTI.
Learning Robust Reasoning through Guided Adversarial Self-Play
Jan 30, 2026Reinforcement learning from verifiable rewards (RLVR) produces strong reasoning models, yet they can fail catastrophically when the conditioning context is fallible (e.g., corrupted chain-of-thought, misleading partial solutions, or mild input perturbations), since standard RLVR optimizes final-answer correctness only under clean conditioning. We introduce GASP (Guided Adversarial Self-Play), a robustification method that explicitly trains detect-and-repair capabilities using only outcome verification. Without human labels or external teachers, GASP forms an adversarial self-play game within a single model: a polluter learns to induce failure via locally coherent corruptions, while an agent learns to diagnose and recover under the same corrupted conditioning. To address the scarcity of successful recoveries early in training, we propose in-distribution repair guidance, an imitation term on self-generated repairs that increases recovery probability while preserving previously acquired capabilities. Across four open-weight models (1.5B--8B), GASP transforms strong-but-brittle reasoners into robust ones that withstand misleading and perturbed context while often improving clean accuracy. Further analysis shows that adversarial corruptions induce an effective curriculum, and in-distribution guidance enables rapid recovery learning with minimal representational drift.
Metacognitive Self-Correction for Multi-Agent System via Prototype-Guided Next-Execution Reconstruction
Oct 16, 2025Large Language Model based multi-agent systems (MAS) excel at collaborative problem solving but remain brittle to cascading errors: a single faulty step can propagate across agents and disrupt the trajectory. In this paper, we present MASC, a metacognitive framework that endows MAS with real-time, unsupervised, step-level error detection and self-correction. MASC rethinks detection as history-conditioned anomaly scoring via two complementary designs: (1) Next-Execution Reconstruction, which predicts the embedding of the next step from the query and interaction history to capture causal consistency, and (2) Prototype-Guided Enhancement, which learns a prototype prior over normal-step embeddings and uses it to stabilize reconstruction and anomaly scoring under sparse context (e.g., early steps). When an anomaly step is flagged, MASC triggers a correction agent to revise the acting agent's output before information flows downstream. On the Who&When benchmark, MASC consistently outperforms all baselines, improving step-level error detection by up to 8.47% AUC-ROC ; When plugged into diverse MAS frameworks, it delivers consistent end-to-end gains across architectures, confirming that our metacognitive monitoring and targeted correction can mitigate error propagation with minimal overhead.
In Search of a Lost Metric: Human Empowerment as a Pillar of Socially Conscious Navigation
Jan 02, 2025



In social robot navigation, traditional metrics like proxemics and behavior naturalness emphasize human comfort and adherence to social norms but often fail to capture an agent's autonomy and adaptability in dynamic environments. This paper introduces human empowerment, an information-theoretic concept that measures a human's ability to influence their future states and observe those changes, as a complementary metric for evaluating social compliance. This metric reveals how robot navigation policies can indirectly impact human empowerment. We present a framework that integrates human empowerment into the evaluation of social performance in navigation tasks. Through numerical simulations, we demonstrate that human empowerment as a metric not only aligns with intuitive social behavior, but also shows statistically significant differences across various robot navigation policies. These results provide a deeper understanding of how different policies affect social compliance, highlighting the potential of human empowerment as a complementary metric for future research in social navigation.
Navigating Noisy Feedback: Enhancing Reinforcement Learning with Error-Prone Language Models
Oct 22, 2024The correct specification of reward models is a well-known challenge in reinforcement learning. Hand-crafted reward functions often lead to inefficient or suboptimal policies and may not be aligned with user values. Reinforcement learning from human feedback is a successful technique that can mitigate such issues, however, the collection of human feedback can be laborious. Recent works have solicited feedback from pre-trained large language models rather than humans to reduce or eliminate human effort, however, these approaches yield poor performance in the presence of hallucination and other errors. This paper studies the advantages and limitations of reinforcement learning from large language model feedback and proposes a simple yet effective method for soliciting and applying feedback as a potential-based shaping function. We theoretically show that inconsistent rankings, which approximate ranking errors, lead to uninformative rewards with our approach. Our method empirically improves convergence speed and policy returns over commonly used baselines even with significant ranking errors, and eliminates the need for complex post-processing of reward functions.
Multi-Robot Cooperative Navigation in Crowds: A Game-Theoretic Learning-Based Model Predictive Control Approach
Oct 10, 2023



In this paper, we develop a control framework for the coordination of multiple robots as they navigate through crowded environments. Our framework comprises of a local model predictive control (MPC) for each robot and a social long short-term memory model that forecasts pedestrians' trajectories. We formulate the local MPC formulation for each individual robot that includes both individual and shared objectives, in which the latter encourages the emergence of coordination among robots. Next, we consider the multi-robot navigation and human-robot interaction, respectively, as a potential game and a two-player game, then employ an iterative best response approach to solve the resulting optimization problems in a centralized and distributed fashion. Finally, we demonstrate the effectiveness of coordination among robots in simulated crowd navigation.
Social Navigation in Crowded Environments with Model Predictive Control and Deep Learning-Based Human Trajectory Prediction
Sep 28, 2023



Crowd navigation has received increasing attention from researchers over the last few decades, resulting in the emergence of numerous approaches aimed at addressing this problem to date. Our proposed approach couples agent motion prediction and planning to avoid the freezing robot problem while simultaneously capturing multi-agent social interactions by utilizing a state-of-the-art trajectory prediction model i.e., social long short-term memory model (Social-LSTM). Leveraging the output of Social-LSTM for the prediction of future trajectories of pedestrians at each time-step given the robot's possible actions, our framework computes the optimal control action using Model Predictive Control (MPC) for the robot to navigate among pedestrians. We demonstrate the effectiveness of our proposed approach in multiple scenarios of simulated crowd navigation and compare it against several state-of-the-art reinforcement learning-based methods.
Cooperative Energy and Time-Optimal Lane Change Maneuvers with Minimal Highway Traffic Disruption
Nov 16, 2022



We derive optimal control policies for a Connected Automated Vehicle (CAV) and cooperating neighboring CAVs to carry out a lane change maneuver consisting of a longitudinal phase where the CAV properly positions itself relative to the cooperating neighbors and a lateral phase where it safely changes lanes. In contrast to prior work on this problem, where the CAV "selfishly" only seeks to minimize its maneuver time, we seek to ensure that the fast-lane traffic flow is minimally disrupted (through a properly defined metric). Additionally, when performing lane-changing maneuvers, we optimally select the cooperating vehicles from a set of feasible neighboring vehicles and experimentally show that the highway throughput is improved compared to the baseline case of human-driven vehicles changing lanes with no cooperation. When feasible solutions do not exist for a given maximal allowable disruption, we include a time relaxation method trading off a longer maneuver time with reduced disruption. Our analysis is also extended to multiple sequential maneuvers. Simulation results show the effectiveness of our controllers in terms of safety guarantees and up to 16% and 90% average throughput and maneuver time improvement respectively when compared to maneuvers with no cooperation.
Optimal Transport Based Refinement of Physics-Informed Neural Networks
May 27, 2021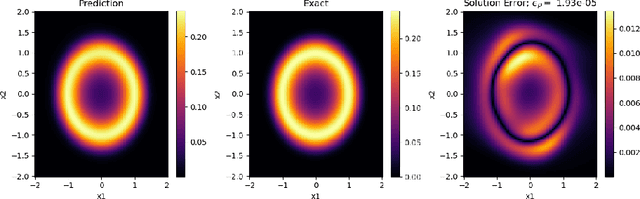

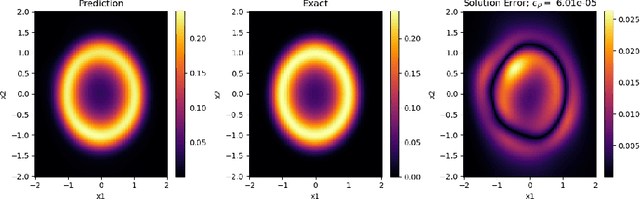
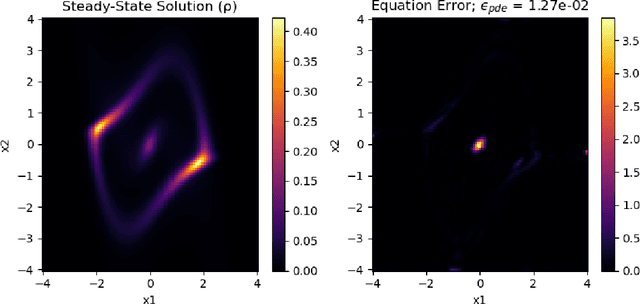
In this paper, we propose a refinement strategy to the well-known Physics-Informed Neural Networks (PINNs) for solving partial differential equations (PDEs) based on the concept of Optimal Transport (OT). Conventional black-box PINNs solvers have been found to suffer from a host of issues: spectral bias in fully-connected architectures, unstable gradient pathologies, as well as difficulties with convergence and accuracy. Current network training strategies are agnostic to dimension sizes and rely on the availability of powerful computing resources to optimize through a large number of collocation points. This is particularly challenging when studying stochastic dynamical systems with the Fokker-Planck-Kolmogorov Equation (FPKE), a second-order PDE which is typically solved in high-dimensional state space. While we focus exclusively on the stationary form of the FPKE, positivity and normalization constraints on its solution make it all the more unfavorable to solve directly using standard PINNs approaches. To mitigate the above challenges, we present a novel training strategy for solving the FPKE using OT-based sampling to supplement the existing PINNs framework. It is an iterative approach that induces a network trained on a small dataset to add samples to its training dataset from regions where it nominally makes the most error. The new samples are found by solving a linear programming problem at every iteration. The paper is complemented by an experimental evaluation of the proposed method showing its applicability on a variety of stochastic systems with nonlinear dynamics.