 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Reasoning through Guided Adversarial Self-Play
Jan 30, 2026Reinforcement learning from verifiable rewards (RLVR) produces strong reasoning models, yet they can fail catastrophically when the conditioning context is fallible (e.g., corrupted chain-of-thought, misleading partial solutions, or mild input perturbations), since standard RLVR optimizes final-answer correctness only under clean conditioning. We introduce GASP (Guided Adversarial Self-Play), a robustification method that explicitly trains detect-and-repair capabilities using only outcome verification. Without human labels or external teachers, GASP forms an adversarial self-play game within a single model: a polluter learns to induce failure via locally coherent corruptions, while an agent learns to diagnose and recover under the same corrupted conditioning. To address the scarcity of successful recoveries early in training, we propose in-distribution repair guidance, an imitation term on self-generated repairs that increases recovery probability while preserving previously acquired capabilities. Across four open-weight models (1.5B--8B), GASP transforms strong-but-brittle reasoners into robust ones that withstand misleading and perturbed context while often improving clean accuracy. Further analysis shows that adversarial corruptions induce an effective curriculum, and in-distribution guidance enables rapid recovery learning with minimal representational drift.
Metacognitive Self-Correction for Multi-Agent System via Prototype-Guided Next-Execution Reconstruction
Oct 16, 2025Large Language Model based multi-agent systems (MAS) excel at collaborative problem solving but remain brittle to cascading errors: a single faulty step can propagate across agents and disrupt the trajectory. In this paper, we present MASC, a metacognitive framework that endows MAS with real-time, unsupervised, step-level error detection and self-correction. MASC rethinks detection as history-conditioned anomaly scoring via two complementary designs: (1) Next-Execution Reconstruction, which predicts the embedding of the next step from the query and interaction history to capture causal consistency, and (2) Prototype-Guided Enhancement, which learns a prototype prior over normal-step embeddings and uses it to stabilize reconstruction and anomaly scoring under sparse context (e.g., early steps). When an anomaly step is flagged, MASC triggers a correction agent to revise the acting agent's output before information flows downstream. On the Who&When benchmark, MASC consistently outperforms all baselines, improving step-level error detection by up to 8.47% AUC-ROC ; When plugged into diverse MAS frameworks, it delivers consistent end-to-end gains across architectures, confirming that our metacognitive monitoring and targeted correction can mitigate error propagation with minimal overhead.
Navigating Noisy Feedback: Enhancing Reinforcement Learning with Error-Prone Language Models
Oct 22, 2024The correct specification of reward models is a well-known challenge in reinforcement learning. Hand-crafted reward functions often lead to inefficient or suboptimal policies and may not be aligned with user values. Reinforcement learning from human feedback is a successful technique that can mitigate such issues, however, the collection of human feedback can be laborious. Recent works have solicited feedback from pre-trained large language models rather than humans to reduce or eliminate human effort, however, these approaches yield poor performance in the presence of hallucination and other errors. This paper studies the advantages and limitations of reinforcement learning from large language model feedback and proposes a simple yet effective method for soliciting and applying feedback as a potential-based shaping function. We theoretically show that inconsistent rankings, which approximate ranking errors, lead to uninformative rewards with our approach. Our method empirically improves convergence speed and policy returns over commonly used baselines even with significant ranking errors, and eliminates the need for complex post-processing of reward functions.
Predicting Parameters for Modeling Traffic Participants
Jan 26, 2023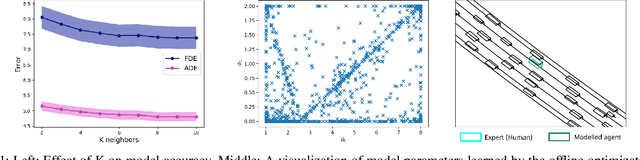


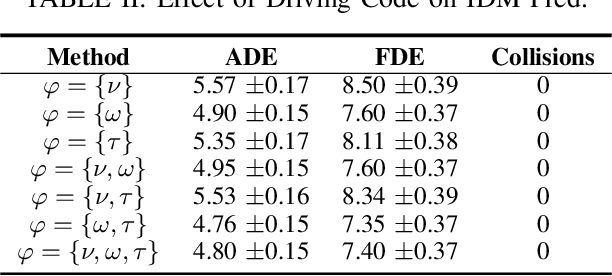
Accurately modeling the behavior of traffic participants is essential for safely and efficiently navigating an autonomous vehicle through heavy traffic. We propose a method, based on the intelligent driver model, that allows us to accurately model individual driver behaviors from only a small number of frames using easily observable features. On average, this method makes prediction errors that have less than 1 meter difference from an oracle with full-information when analyzed over a 10-second horizon of highway driving. We then validate the efficiency of our method through extensive analysis against a competitive data-driven method such as Reinforcement Learning that may be of independent interest.