 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeedup Techniques for Switchable Temporal Plan Graph Optimization
Dec 20, 2024



Multi-Agent Path Finding (MAPF) focuses on planning collision-free paths for multiple agents. However, during the execution of a MAPF plan, agents may encounter unexpected delays, which can lead to inefficiencies, deadlocks, or even collisions. To address these issues, the Switchable Temporal Plan Graph provides a framework for finding an acyclic Temporal Plan Graph with the minimum execution cost under delays, ensuring deadlock- and collision-free execution. Unfortunately, existing optimal algorithms, such as Mixed Integer Linear Programming and Graph-Based Switchable Edge Search (GSES), are often too slow for practical use. This paper introduces Improved GSES, which significantly accelerates GSES through four speedup techniques: stronger admissible heuristics, edge grouping, prioritized branching, and incremental implementation. Experiments conducted on four different map types with varying numbers of agents demonstrate that Improved GSES consistently achieves over twice the success rate of GSES and delivers up to a 30-fold speedup on instances where both methods successfully find solutions.
Navigating Noisy Feedback: Enhancing Reinforcement Learning with Error-Prone Language Models
Oct 22, 2024The correct specification of reward models is a well-known challenge in reinforcement learning. Hand-crafted reward functions often lead to inefficient or suboptimal policies and may not be aligned with user values. Reinforcement learning from human feedback is a successful technique that can mitigate such issues, however, the collection of human feedback can be laborious. Recent works have solicited feedback from pre-trained large language models rather than humans to reduce or eliminate human effort, however, these approaches yield poor performance in the presence of hallucination and other errors. This paper studies the advantages and limitations of reinforcement learning from large language model feedback and proposes a simple yet effective method for soliciting and applying feedback as a potential-based shaping function. We theoretically show that inconsistent rankings, which approximate ranking errors, lead to uninformative rewards with our approach. Our method empirically improves convergence speed and policy returns over commonly used baselines even with significant ranking errors, and eliminates the need for complex post-processing of reward functions.
Region Specific Optimization (RSO)-based Deep Interactive Registration
Mar 08, 2022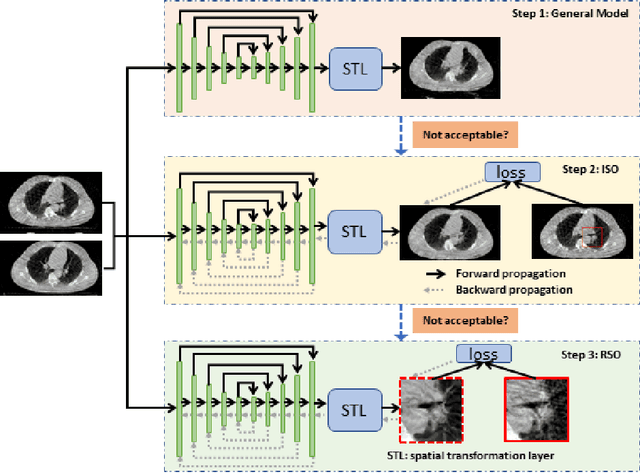
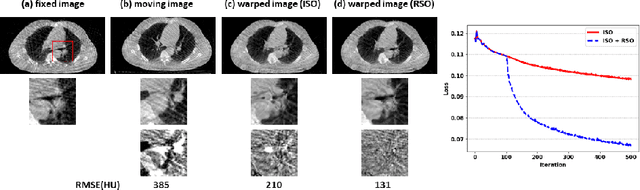

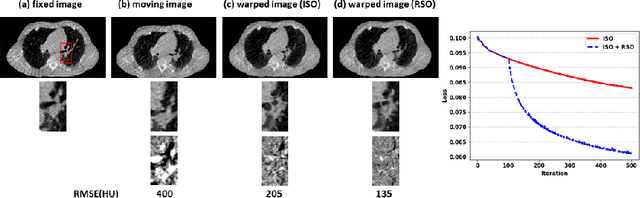
Medical image registration is a fundamental and vital task which will affect the efficacy of many downstream clinical tasks. Deep learning (DL)-based deformable image registration (DIR) methods have been investigated, showing state-of-the-art performance. A test time optimization (TTO) technique was proposed to further improve the DL models' performance. Despite the substantial accuracy improvement with this TTO technique, there still remained some regions that exhibited large registration errors even after many TTO iterations. To mitigate this challenge, we firstly identified the reason why the TTO technique was slow, or even failed, to improve those regions' registration results. We then proposed a two-levels TTO technique, i.e., image-specific optimization (ISO) and region-specific optimization (RSO), where the region can be interactively indicated by the clinician during the registration result reviewing process. For both efficiency and accuracy, we further envisioned a three-step DL-based image registration workflow. Experimental results showed that our proposed method outperformed the conventional method qualitatively and quantitatively.