 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTGR: Industrial-Scale Generative Recommendation Framework in Meituan
May 24, 2025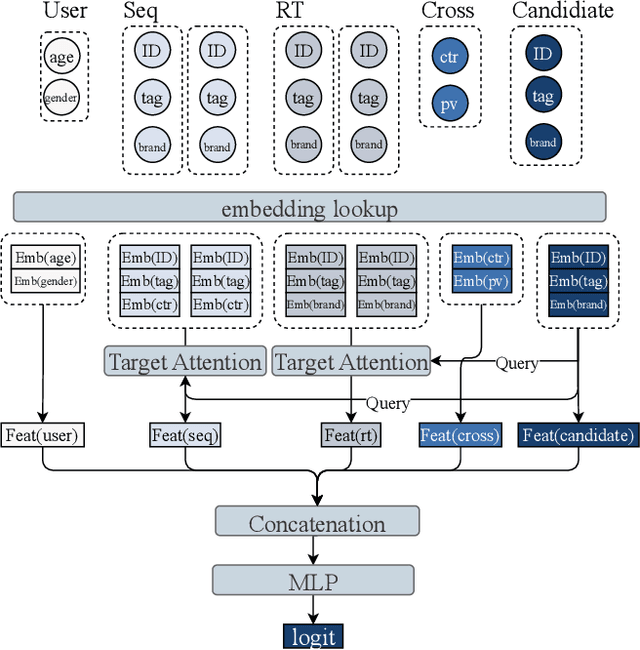
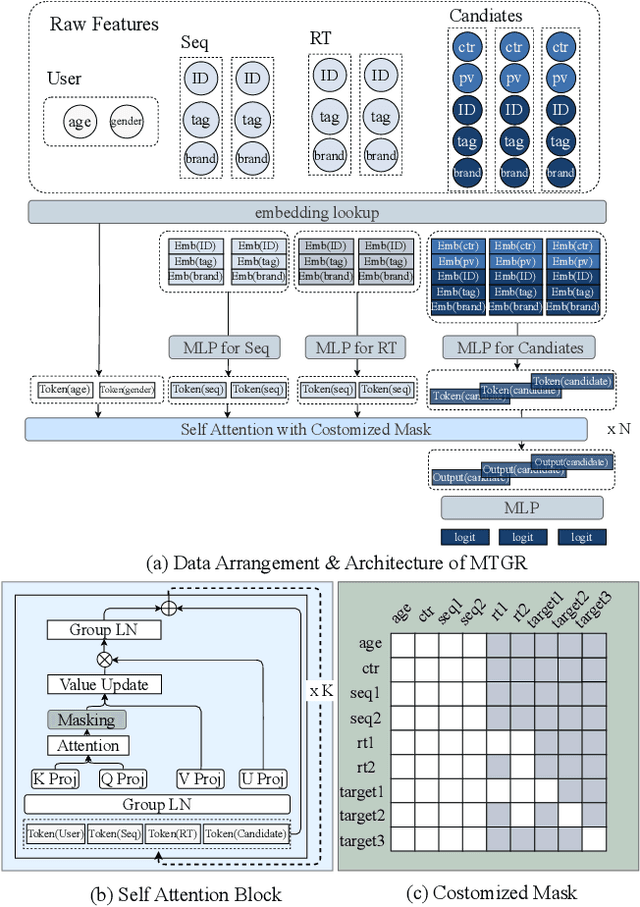

Scaling law has been extensively validated in many domains such as natural language processing and computer vision. In the recommendation system, recent work has adopted generative recommendations to achieve scalability, but their generative approaches require abandoning the carefully constructed cross features of traditional recommendation models. We found that this approach significantly degrades model performance, and scaling up cannot compensate for it at all. In this paper, we propose MTGR (Meituan Generative Recommendation) to address this issue. MTGR is modeling based on the HSTU architecture and can retain the original deep learning recommendation model (DLRM) features, including cross features. Additionally, MTGR achieves training and inference acceleration through user-level compression to ensure efficient scaling. We also propose Group-Layer Normalization (GLN) to enhance the performance of encoding within different semantic spaces and the dynamic masking strategy to avoid information leakage. We further optimize the training frameworks, enabling support for our models with 10 to 100 times computational complexity compared to the DLRM, without significant cost increases. MTGR achieved 65x FLOPs for single-sample forward inference compared to the DLRM model, resulting in the largest gain in nearly two years both offline and online. This breakthrough was successfully deployed on Meituan, the world's largest food delivery platform, where it has been handling the main traffic.
Speedup Techniques for Switchable Temporal Plan Graph Optimization
Dec 20, 2024



Multi-Agent Path Finding (MAPF) focuses on planning collision-free paths for multiple agents. However, during the execution of a MAPF plan, agents may encounter unexpected delays, which can lead to inefficiencies, deadlocks, or even collisions. To address these issues, the Switchable Temporal Plan Graph provides a framework for finding an acyclic Temporal Plan Graph with the minimum execution cost under delays, ensuring deadlock- and collision-free execution. Unfortunately, existing optimal algorithms, such as Mixed Integer Linear Programming and Graph-Based Switchable Edge Search (GSES), are often too slow for practical use. This paper introduces Improved GSES, which significantly accelerates GSES through four speedup techniques: stronger admissible heuristics, edge grouping, prioritized branching, and incremental implementation. Experiments conducted on four different map types with varying numbers of agents demonstrate that Improved GSES consistently achieves over twice the success rate of GSES and delivers up to a 30-fold speedup on instances where both methods successfully find solutions.
Deploying Ten Thousand Robots: Scalable Imitation Learning for Lifelong Multi-Agent Path Finding
Oct 28, 2024



Lifelong Multi-Agent Path Finding (LMAPF) is a variant of MAPF where agents are continually assigned new goals, necessitating frequent re-planning to accommodate these dynamic changes. Recently, this field has embraced learning-based methods, which reactively generate single-step actions based on individual local observations. However, it is still challenging for them to match the performance of the best search-based algorithms, especially in large-scale settings. This work proposes an imitation-learning-based LMAPF solver that introduces a novel communication module and systematic single-step collision resolution and global guidance techniques. Our proposed solver, Scalable Imitation Learning for LMAPF (SILLM), inherits the fast reasoning speed of learning-based methods and the high solution quality of search-based methods with the help of modern GPUs. Across six large-scale maps with up to 10,000 agents and varying obstacle structures, SILLM surpasses the best learning- and search-based baselines, achieving average throughput improvements of 137.7% and 16.0%, respectively. Furthermore, SILLM also beats the winning solution of the 2023 League of Robot Runners, an international LMAPF competition sponsored by Amazon Robotics. Finally, we validated SILLM with 10 real robots and 100 virtual robots in a mockup warehouse environment.
Enhancing CTR Prediction through Sequential Recommendation Pre-training: Introducing the SRP4CTR Framework
Jul 29, 2024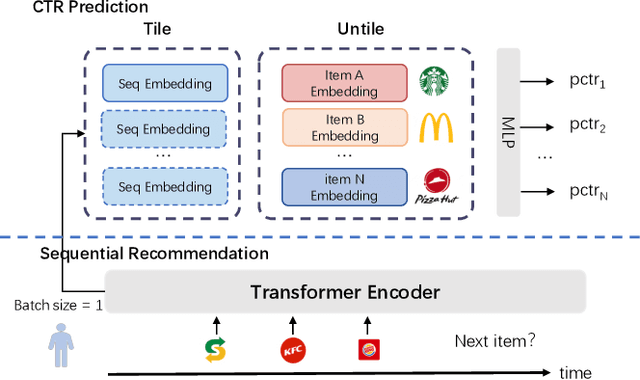
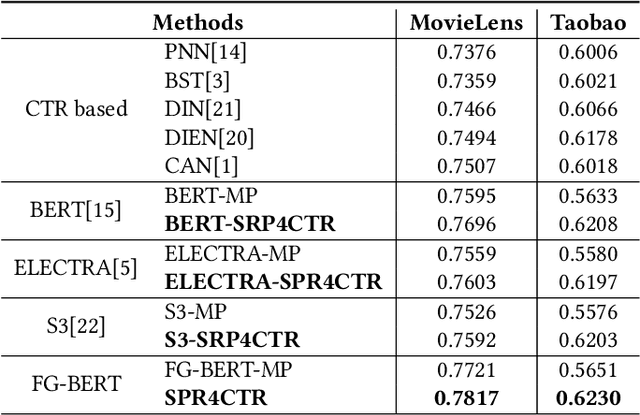
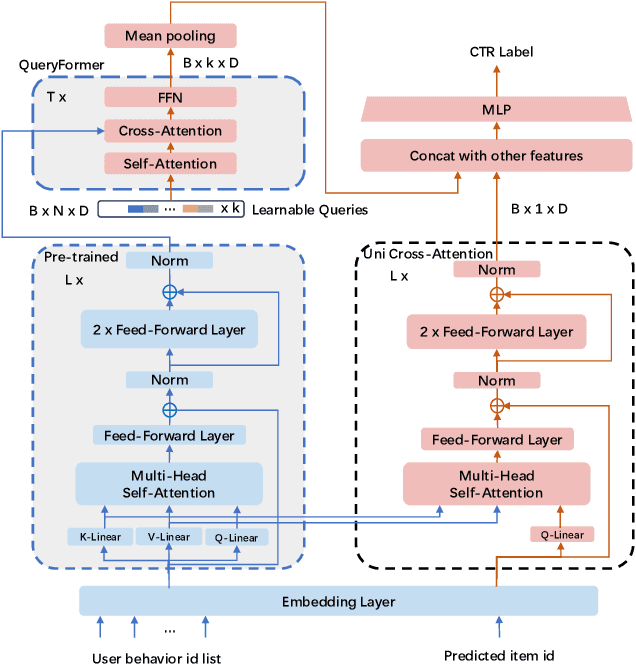
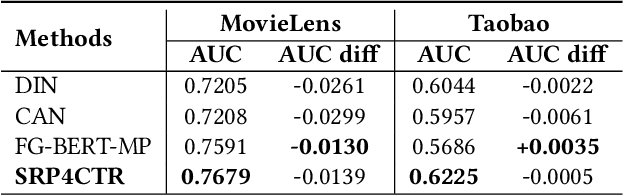
Understanding user interests is crucial for Click-Through Rate (CTR) prediction tasks. In sequential recommendation, pre-training from user historical behaviors through self-supervised learning can better comprehend user dynamic preferences, presenting the potential for direct integration with CTR tasks. Previous methods have integrated pre-trained models into downstream tasks with the sole purpose of extracting semantic information or well-represented user features, which are then incorporated as new features. However, these approaches tend to ignore the additional inference costs to the downstream tasks, and they do not consider how to transfer the effective information from the pre-trained models for specific estimated items in CTR prediction. In this paper, we propose a Sequential Recommendation Pre-training framework for CTR prediction (SRP4CTR) to tackle the above problems. Initially, we discuss the impact of introducing pre-trained models on inference costs. Subsequently, we introduced a pre-trained method to encode sequence side information concurrently.During the fine-tuning process, we incorporate a cross-attention block to establish a bridge between estimated items and the pre-trained model at a low cost. Moreover, we develop a querying transformer technique to facilitate the knowledge transfer from the pre-trained model to industrial CTR models. Offline and online experiments show that our method outperforms previous baseline models.
Scaling Lifelong Multi-Agent Path Finding to More Realistic Settings: Research Challenges and Opportunities
Apr 24, 2024Multi-Agent Path Finding (MAPF) is the problem of moving multiple agents from starts to goals without collisions. Lifelong MAPF (LMAPF) extends MAPF by continuously assigning new goals to agents. We present our winning approach to the 2023 League of Robot Runners LMAPF competition, which leads us to several interesting research challenges and future directions. In this paper, we outline three main research challenges. The first challenge is to search for high-quality LMAPF solutions within a limited planning time (e.g., 1s per step) for a large number of agents (e.g., 10,000) or extremely high agent density (e.g., 97.7%). We present future directions such as developing more competitive rule-based and anytime MAPF algorithms and parallelizing state-of-the-art MAPF algorithms. The second challenge is to alleviate congestion and the effect of myopic behaviors in LMAPF algorithms. We present future directions, such as developing moving guidance and traffic rules to reduce congestion, incorporating future prediction and real-time search, and determining the optimal agent number. The third challenge is to bridge the gaps between the LMAPF models used in the literature and real-world applications. We present future directions, such as dealing with more realistic kinodynamic models, execution uncertainty, and evolving systems.
Guidance Graph Optimization for Lifelong Multi-Agent Path Finding
Feb 02, 2024We study how to use guidance to improve the throughput of lifelong Multi-Agent Path Finding (MAPF). Previous studies have demonstrated that while incorporating guidance, such as highways, can accelerate MAPF algorithms, this often results in a trade-off with solution quality. In addition, how to generate good guidance automatically remains largely unexplored, with current methods falling short of surpassing manually designed ones. In this work, we introduce the directed guidance graph as a versatile representation of guidance for lifelong MAPF, framing Guidance Graph Optimization (GGO) as the task of optimizing its edge weights. We present two GGO algorithms to automatically generate guidance for arbitrary lifelong MAPF algorithms and maps. The first method directly solves GGO by employing CMA-ES, a black-box optimization algorithm. The second method, PIU, optimizes an update model capable of generating guidance, demonstrating the ability to transfer optimized guidance graphs to larger maps with similar layouts. Empirically, we show that (1) our guidance graphs improve the throughput of three representative lifelong MAPF algorithms in four benchmark maps, and (2) our update model can generate guidance graphs for as large as $93 \times 91$ maps and as many as 3000 agents.
An Empirical Study on Google Research Football Multi-agent Scenarios
May 16, 2023Few multi-agent reinforcement learning (MARL) research on Google Research Football (GRF) focus on the 11v11 multi-agent full-game scenario and to the best of our knowledge, no open benchmark on this scenario has been released to the public. In this work, we fill the gap by providing a population-based MARL training pipeline and hyperparameter settings on multi-agent football scenario that outperforms the bot with difficulty 1.0 from scratch within 2 million steps. Our experiments serve as a reference for the expected performance of Independent Proximal Policy Optimization (IPPO), a state-of-the-art multi-agent reinforcement learning algorithm where each agent tries to maximize its own policy independently across various training configurations. Meanwhile, we open-source our training framework Light-MALib which extends the MALib codebase by distributed and asynchronized implementation with additional analytical tools for football games. Finally, we provide guidance for building strong football AI with population-based training and release diverse pretrained policies for benchmarking. The goal is to provide the community with a head start for whoever experiment their works on GRF and a simple-to-use population-based training framework for further improving their agents through self-play. The implementation is available at https://github.com/Shanghai-Digital-Brain-Laboratory/DB-Football.
Metropolis Theorem and Its Applications in Single Image Detail Enhancement
Feb 20, 2023



Traditional image detail enhancement is local filter-based or global filter-based. In both approaches, the original image is first divided into the base layer and the detail layer, and then the enhanced image is obtained by amplifying the detail layer. Our method is different, and its innovation lies in the special way to get the image detail layer. The detail layer in our method is obtained by updating the residual features, and the updating mechanism is usually based on searching and matching similar patches. However, due to the diversity of image texture features, perfect matching is often not possible. In this paper, the process of searching and matching is treated as a thermodynamic process, where the Metropolis theorem can minimize the internal energy and get the global optimal solution of this task, that is, to find a more suitable feature for a better detail enhancement performance. Extensive experiments have proven that our algorithm can achieve better results in quantitative metrics testing and visual effects evaluation. The source code can be obtained from the link.
Ontology-aware Network for Zero-shot Sketch-based Image Retrieval
Feb 20, 2023Zero-Shot Sketch-Based Image Retrieval (ZSSBIR) is an emerging task. The pioneering work focused on the modal gap but ignored inter-class information. Although recent work has begun to consider the triplet-based or contrast-based loss to mine inter-class information, positive and negative samples need to be carefully selected, or the model is prone to lose modality-specific information. To respond to these issues, an Ontology-Aware Network (OAN) is proposed. Specifically, the smooth inter-class independence learning mechanism is put forward to maintain inter-class peculiarity. Meanwhile, distillation-based consistency preservation is utilized to keep modality-specific information. Extensive experiments have demonstrated the superior performance of our algorithm on two challenging Sketchy and Tu-Berlin datasets.
Deep Forest with Hashing Screening and Window Screening
Jul 25, 2022
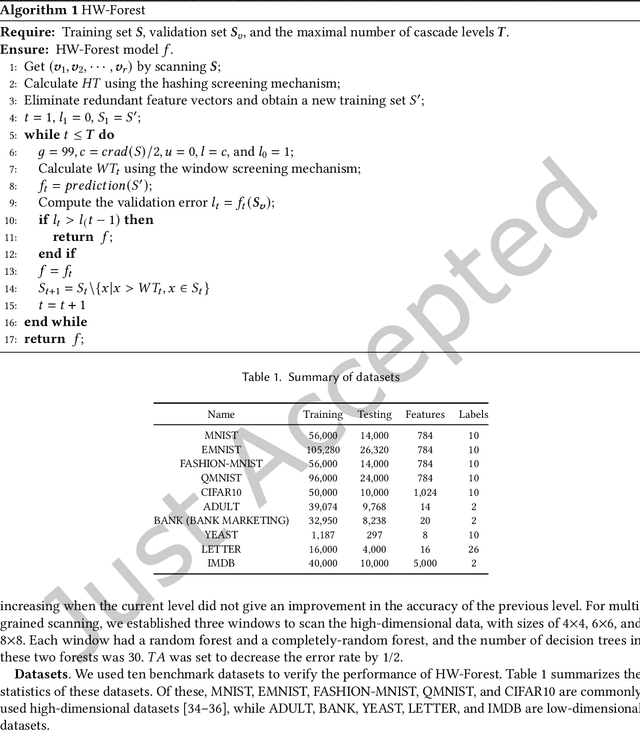
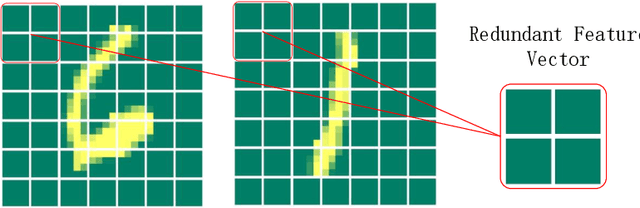
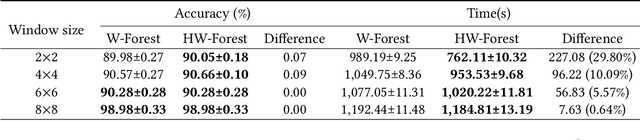
As a novel deep learning model, gcForest has been widely used in various applications. However, the current multi-grained scanning of gcForest produces many redundant feature vectors, and this increases the time cost of the model. To screen out redundant feature vectors, we introduce a hashing screening mechanism for multi-grained scanning and propose a model called HW-Forest which adopts two strategies, hashing screening and window screening. HW-Forest employs perceptual hashing algorithm to calculate the similarity between feature vectors in hashing screening strategy, which is used to remove the redundant feature vectors produced by multi-grained scanning and can significantly decrease the time cost and memory consumption. Furthermore, we adopt a self-adaptive instance screening strategy to improve the performance of our approach, called window screening, which can achieve higher accuracy without hyperparameter tuning on different datasets. Our experimental results show that HW-Forest has higher accuracy than other models, and the time cost is also reduced.