 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing CTR Prediction through Sequential Recommendation Pre-training: Introducing the SRP4CTR Framework
Jul 29, 2024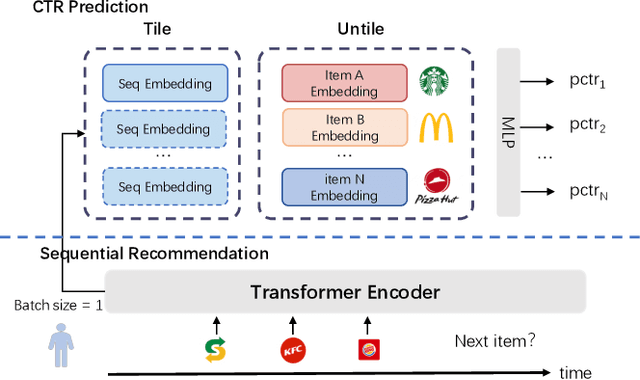
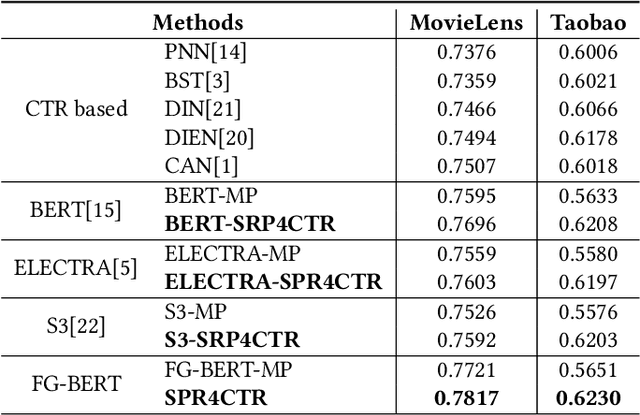
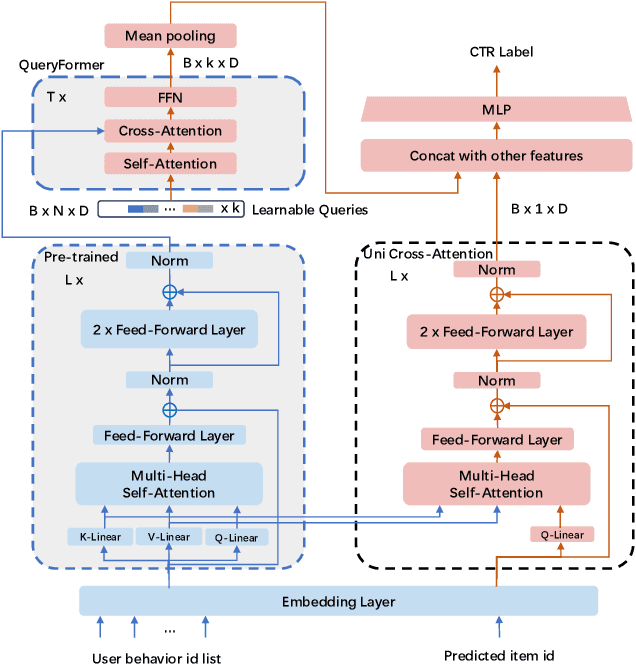
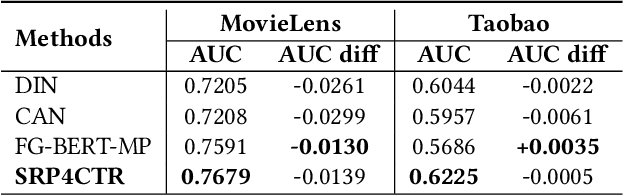
Understanding user interests is crucial for Click-Through Rate (CTR) prediction tasks. In sequential recommendation, pre-training from user historical behaviors through self-supervised learning can better comprehend user dynamic preferences, presenting the potential for direct integration with CTR tasks. Previous methods have integrated pre-trained models into downstream tasks with the sole purpose of extracting semantic information or well-represented user features, which are then incorporated as new features. However, these approaches tend to ignore the additional inference costs to the downstream tasks, and they do not consider how to transfer the effective information from the pre-trained models for specific estimated items in CTR prediction. In this paper, we propose a Sequential Recommendation Pre-training framework for CTR prediction (SRP4CTR) to tackle the above problems. Initially, we discuss the impact of introducing pre-trained models on inference costs. Subsequently, we introduced a pre-trained method to encode sequence side information concurrently.During the fine-tuning process, we incorporate a cross-attention block to establish a bridge between estimated items and the pre-trained model at a low cost. Moreover, we develop a querying transformer technique to facilitate the knowledge transfer from the pre-trained model to industrial CTR models. Offline and online experiments show that our method outperforms previous baseline models.
Context-based Fast Recommendation Strategy for Long User Behavior Sequence in Meituan Waimai
Mar 19, 2024



In the recommender system of Meituan Waimai, we are dealing with ever-lengthening user behavior sequences, which pose an increasing challenge to modeling user preference effectively. Existing sequential recommendation models often fail to capture long-term dependencies or are too complex, complicating the fulfillment of Meituan Waimai's unique business needs. To better model user interests, we consider selecting relevant sub-sequences from users' extensive historical behaviors based on their preferences. In this specific scenario, we've noticed that the contexts in which users interact have a significant impact on their preferences. For this purpose, we introduce a novel method called Context-based Fast Recommendation Strategy to tackle the issue of long sequences. We first identify contexts that share similar user preferences with the target context and then locate the corresponding PoIs based on these identified contexts. This approach eliminates the necessity to select a sub-sequence for every candidate PoI, thereby avoiding high time complexity. Specifically, we implement a prototype-based approach to pinpoint contexts that mirror similar user preferences. To amplify accuracy and interpretability, we employ JS divergence of PoI attributes such as categories and prices as a measure of similarity between contexts. A temporal graph integrating both prototype and context nodes helps incorporate temporal information. We then identify appropriate prototypes considering both target contexts and short-term user preferences. Following this, we utilize contexts aligned with these prototypes to generate a sub-sequence, aimed at predicting CTR and CTCVR scores with target attention. Since its inception in 2023, this strategy has been adopted in Meituan Waimai's display recommender system, leading to a 4.6% surge in CTR and a 4.2% boost in GMV.
TB-Net: A Three-Stream Boundary-Aware Network for Fine-Grained Pavement Disease Segmentation
Nov 07, 2020
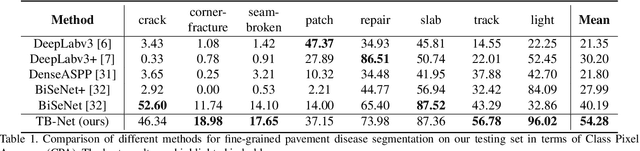
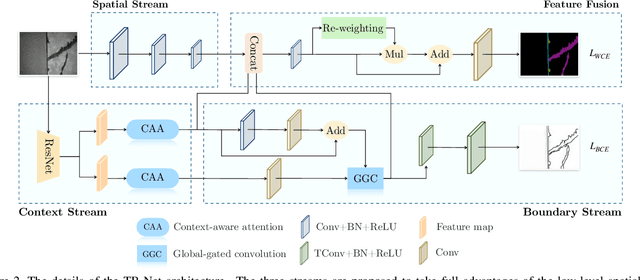
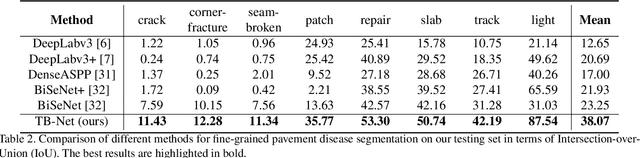
Regular pavement inspection plays a significant role in road maintenance for safety assurance. Existing methods mainly address the tasks of crack detection and segmentation that are only tailored for long-thin crack disease. However, there are many other types of diseases with a wider variety of sizes and patterns that are also essential to segment in practice, bringing more challenges towards fine-grained pavement inspection. In this paper, our goal is not only to automatically segment cracks, but also to segment other complex pavement diseases as well as typical landmarks (markings, runway lights, etc.) and commonly seen water/oil stains in a single model. To this end, we propose a three-stream boundary-aware network (TB-Net). It consists of three streams fusing the low-level spatial and the high-level contextual representations as well as the detailed boundary information. Specifically, the spatial stream captures rich spatial features. The context stream, where an attention mechanism is utilized, models the contextual relationships over local features. The boundary stream learns detailed boundaries using a global-gated convolution to further refine the segmentation outputs. The network is trained using a dual-task loss in an end-to-end manner, and experiments on a newly collected fine-grained pavement disease dataset show the effectiveness of our TB-Net.