 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRSplat: Feed-Forward Super-Resolution Gaussian Splatting from Sparse Multi-View Images
Nov 15, 2025Feed-forward 3D reconstruction from sparse, low-resolution (LR) images is a crucial capability for real-world applications, such as autonomous driving and embodied AI. However, existing methods often fail to recover fine texture details. This limitation stems from the inherent lack of high-frequency information in LR inputs. To address this, we propose \textbf{SRSplat}, a feed-forward framework that reconstructs high-resolution 3D scenes from only a few LR views. Our main insight is to compensate for the deficiency of texture information by jointly leveraging external high-quality reference images and internal texture cues. We first construct a scene-specific reference gallery, generated for each scene using Multimodal Large Language Models (MLLMs) and diffusion models. To integrate this external information, we introduce the \textit{Reference-Guided Feature Enhancement (RGFE)} module, which aligns and fuses features from the LR input images and their reference twin image. Subsequently, we train a decoder to predict the Gaussian primitives using the multi-view fused feature obtained from \textit{RGFE}. To further refine predicted Gaussian primitives, we introduce \textit{Texture-Aware Density Control (TADC)}, which adaptively adjusts Gaussian density based on the internal texture richness of the LR inputs. Extensive experiments demonstrate that our SRSplat outperforms existing methods on various datasets, including RealEstate10K, ACID, and DTU, and exhibits strong cross-dataset and cross-resolution generalization capabilities.
A Reactive Framework for Whole-Body Motion Planning of Mobile Manipulators Combining Reinforcement Learning and SDF-Constrained Quadratic Programmi
Mar 31, 2025As an important branch of embodied artificial intelligence, mobile manipulators are increasingly applied in intelligent services, but their redundant degrees of freedom also limit efficient motion planning in cluttered environments. To address this issue, this paper proposes a hybrid learning and optimization framework for reactive whole-body motion planning of mobile manipulators. We develop the Bayesian distributional soft actor-critic (Bayes-DSAC) algorithm to improve the quality of value estimation and the convergence performance of the learning. Additionally, we introduce a quadratic programming method constrained by the signed distance field to enhance the safety of the obstacle avoidance motion. We conduct experiments and make comparison with standard benchmark. The experimental results verify that our proposed framework significantly improves the efficiency of reactive whole-body motion planning, reduces the planning time, and improves the success rate of motion planning. Additionally, the proposed reinforcement learning method ensures a rapid learning process in the whole-body planning task. The novel framework allows mobile manipulators to adapt to complex environments more safely and efficiently.
EPRecon: An Efficient Framework for Real-Time Panoptic 3D Reconstruction from Monocular Video
Sep 03, 2024



Panoptic 3D reconstruction from a monocular video is a fundamental perceptual task in robotic scene understanding. However, existing efforts suffer from inefficiency in terms of inference speed and accuracy, limiting their practical applicability. We present EPRecon, an efficient real-time panoptic 3D reconstruction framework. Current volumetric-based reconstruction methods usually utilize multi-view depth map fusion to obtain scene depth priors, which is time-consuming and poses challenges to real-time scene reconstruction. To end this, we propose a lightweight module to directly estimate scene depth priors in a 3D volume for reconstruction quality improvement by generating occupancy probabilities of all voxels. In addition, to infer richer panoptic features from occupied voxels, EPRecon extracts panoptic features from both voxel features and corresponding image features, obtaining more detailed and comprehensive instance-level semantic information and achieving more accurate segmentation results. Experimental results on the ScanNetV2 dataset demonstrate the superiority of EPRecon over current state-of-the-art methods in terms of both panoptic 3D reconstruction quality and real-time inference. Code is available at https://github.com/zhen6618/EPRecon.
High-Linearity PAM-4 Silicon Micro-ring Transmitter Architecture with Electronic-Photonic Hybrid DAC
Apr 14, 2024



This paper presents a high linearity PAM-4 transmitter (TX) architecture, consisting of a three-segment micro-ring modulator (MRM) and a matched CMOS driver. This architecture can drive a high-linearity 4-level pulse amplitude (PAM-4) modulation signal, thereby extending the tunable operating wavelength range for achieving linear PAM-4 output. We use the three-segment MRM to increase design flexibility so that the linearity of PAM-4 output can be optimized with another degree of freedom. Each phase shift region is directly driven by the independently amplitude-tunable Non-Return-to-Zero (NRZ) signal. The three-segment modulator can achieve an adjustable wavelength range of approximately 0.037 nm within the high linearity PAM-4 output limit when the driving voltage varies from 1.5 V to 3 V, simultaneously achieving an adjustable insertion loss (IL) range of approximately 2 dB, roughly four times that of the two-segment MRM with a similar design. The driver circuit with adjustable driving voltage is co-designed to adjust the eye height to improve PAM-4 linearity. In this article, the high linearity PAM-4 silicon micro-ring architecture can be employed in optical transmitters to adjust PAM-4 eye-opening size and maximize the PAM-4 output linearity, thus offering the potential for high-performance and low-power overhead transmitters.
Completely Occluded and Dense Object Instance Segmentation Using Box Prompt-Based Segmentation Foundation Models
Jan 16, 2024Completely occluded and dense object instance segmentation (IS) is an important and challenging task. Although current amodal IS methods can predict invisible regions of occluded objects, they are difficult to directly predict completely occluded objects. For dense object IS, existing box-based methods are overly dependent on the performance of bounding box detection. In this paper, we propose CFNet, a coarse-to-fine IS framework for completely occluded and dense objects, which is based on box prompt-based segmentation foundation models (BSMs). Specifically, CFNet first detects oriented bounding boxes (OBBs) to distinguish instances and provide coarse localization information. Then, it predicts OBB prompt-related masks for fine segmentation. To predict completely occluded object instances, CFNet performs IS on occluders and utilizes prior geometric properties, which overcomes the difficulty of directly predicting completely occluded object instances. Furthermore, based on BSMs, CFNet reduces the dependence on bounding box detection performance, improving dense object IS performance. Moreover, we propose a novel OBB prompt encoder for BSMs. To make CFNet more lightweight, we perform knowledge distillation on it and introduce a Gaussian smoothing method for teacher targets. Experimental results demonstrate that CFNet achieves the best performance on both industrial and publicly available datasets.
Linear Gaussian Bounding Box Representation and Ring-Shaped Rotated Convolution for Oriented Object Detection
Nov 14, 2023In oriented object detection, current representations of oriented bounding boxes (OBBs) often suffer from boundary discontinuity problem. Methods of designing continuous regression losses do not essentially solve this problem. Although Gaussian bounding box (GBB) representation avoids this problem, directly regressing GBB is susceptible to numerical instability. We propose linear GBB (LGBB), a novel OBB representation. By linearly transforming the elements of GBB, LGBB avoids the boundary discontinuity problem and has high numerical stability. In addition, existing convolution-based rotation-sensitive feature extraction methods only have local receptive fields, resulting in slow feature aggregation. We propose ring-shaped rotated convolution (RRC), which adaptively rotates feature maps to arbitrary orientations to extract rotation-sensitive features under a ring-shaped receptive field, rapidly aggregating features and contextual information. Experimental results demonstrate that LGBB and RRC achieve state-of-the-art performance. Furthermore, integrating LGBB and RRC into various models effectively improves detection accuracy.
RegHEC: Hand-Eye Calibration via Simultaneous Multi-view Point Clouds Registration of Arbitrary Object
Apr 27, 2023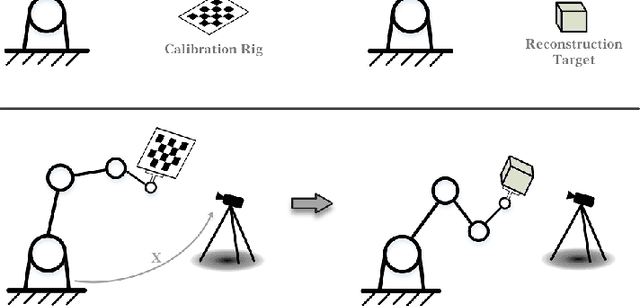



RegHEC is a registration-based hand-eye calibration technique with no need for accurate calibration rig but arbitrary available objects, applicable for both eye-in-hand and eye-to-hand cases. It tries to find the hand-eye relation which brings multi-view point clouds of arbitrary scene into simultaneous registration under a common reference frame. RegHEC first achieves initial alignment of multi-view point clouds via Bayesian optimization, where registration problem is modeled as a Gaussian process over hand-eye relation and the covariance function is modified to be compatible with distance metric in 3-D motion space SE(3), then passes the initial guess of hand-eye relation to an Anderson Accelerated ICP variant for later fine registration and accurate calibration. RegHEC has little requirement on calibration object, it is applicable with sphere, cone, cylinder and even simple plane, which can be quite challenging for correct point cloud registration and sensor motion estimation using existing methods. While suitable for most 3-D vision guided tasks, RegHEC is especially favorable for robotic 3-D reconstruction, as calibration and multi-view point clouds registration of reconstruction target are unified into a single process. Our technique is verified with extensive experiments using varieties of arbitrary objects and real hand-eye system. We release an open-source C++ implementation of RegHEC.
Automatic Facial Skin Feature Detection for Everyone
Mar 30, 2022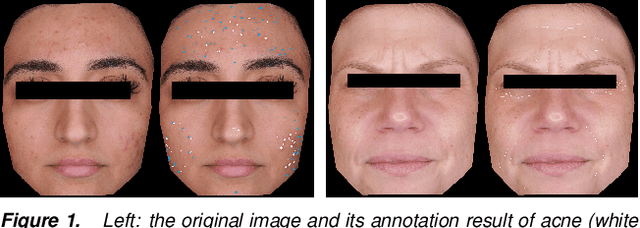
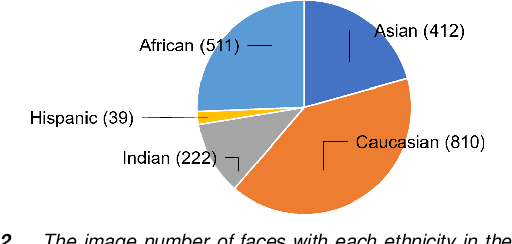
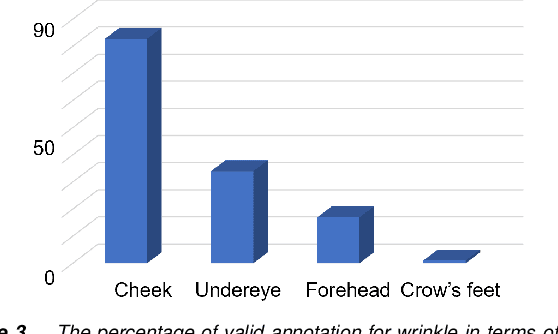
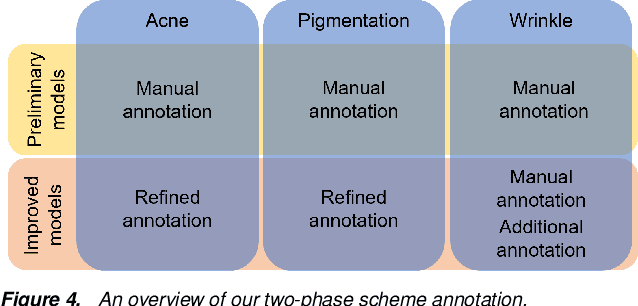
Automatic assessment and understanding of facial skin condition have several applications, including the early detection of underlying health problems, lifestyle and dietary treatment, skin-care product recommendation, etc. Selfies in the wild serve as an excellent data resource to democratize skin quality assessment, but suffer from several data collection challenges.The key to guaranteeing an accurate assessment is accurate detection of different skin features. We present an automatic facial skin feature detection method that works across a variety of skin tones and age groups for selfies in the wild. To be specific, we annotate the locations of acne, pigmentation, and wrinkle for selfie images with different skin tone colors, severity levels, and lighting conditions. The annotation is conducted in a two-phase scheme with the help of a dermatologist to train volunteers for annotation. We employ Unet++ as the network architecture for feature detection. This work shows that the two-phase annotation scheme can robustly detect the accurate locations of acne, pigmentation, and wrinkle for selfie images with different ethnicities, skin tone colors, severity levels, age groups, and lighting conditions.
HybrUR: A Hybrid Physical-Neural Solution for Unsupervised Underwater Image Restoration
Jul 06, 2021
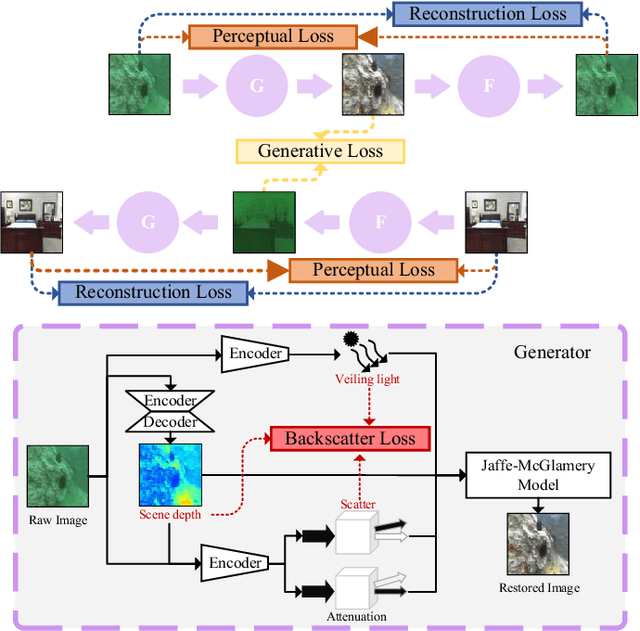
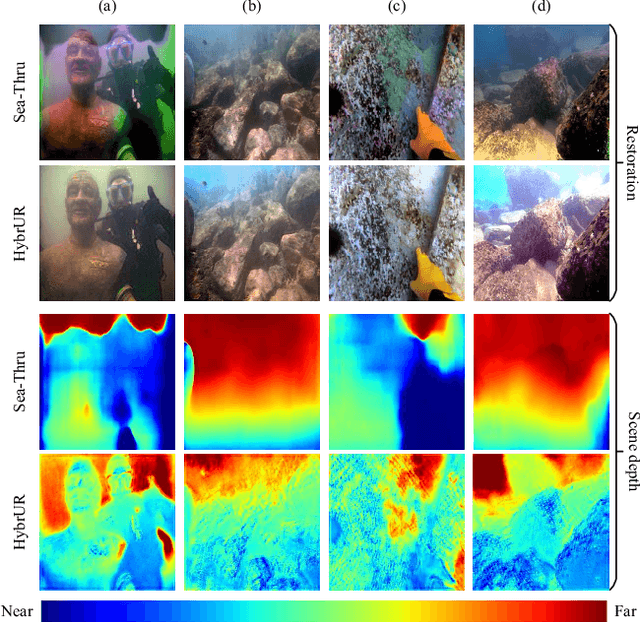

Robust vision restoration for an underwater image remains a challenging problem. For the lack of aligned underwater-terrestrial image pairs, the unsupervised method is more suited to this task. However, the pure data-driven unsupervised method usually has difficulty in achieving realistic color correction for lack of optical constraint. In this paper, we propose a data- and physics-driven unsupervised architecture that learns underwater vision restoration from unpaired underwater-terrestrial images. For sufficient domain transformation and detail preservation, the underwater degeneration needs to be explicitly constructed based on the optically unambiguous physics law. Thus, we employ the Jaffe-McGlamery degradation theory to design the generation models, and use neural networks to describe the process of underwater degradation. Furthermore, to overcome the problem of invalid gradient when optimizing the hybrid physical-neural model, we fully investigate the intrinsic correlation between the scene depth and the degradation factors for the backscattering estimation, to improve the restoration performance through physical constraints. Our experimental results show that the proposed method is able to perform high-quality restoration for unconstrained underwater images without any supervision. On multiple benchmarks, we outperform several state-of-the-art supervised and unsupervised approaches. We also demonstrate that our methods yield encouraging results on real-world applications.
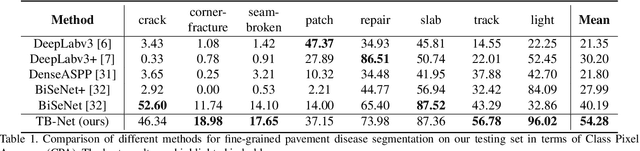
TB-Net: A Three-Stream Boundary-Aware Network for Fine-Grained Pavement Disease Segmentation
Nov 07, 2020
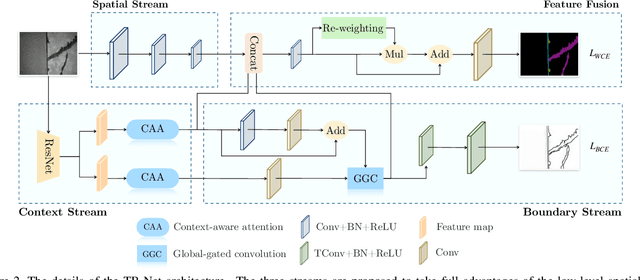
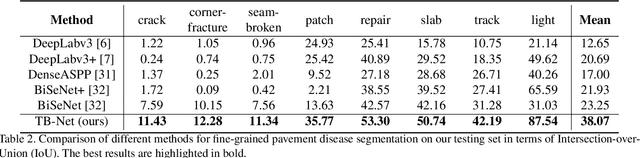
Regular pavement inspection plays a significant role in road maintenance for safety assurance. Existing methods mainly address the tasks of crack detection and segmentation that are only tailored for long-thin crack disease. However, there are many other types of diseases with a wider variety of sizes and patterns that are also essential to segment in practice, bringing more challenges towards fine-grained pavement inspection. In this paper, our goal is not only to automatically segment cracks, but also to segment other complex pavement diseases as well as typical landmarks (markings, runway lights, etc.) and commonly seen water/oil stains in a single model. To this end, we propose a three-stream boundary-aware network (TB-Net). It consists of three streams fusing the low-level spatial and the high-level contextual representations as well as the detailed boundary information. Specifically, the spatial stream captures rich spatial features. The context stream, where an attention mechanism is utilized, models the contextual relationships over local features. The boundary stream learns detailed boundaries using a global-gated convolution to further refine the segmentation outputs. The network is trained using a dual-task loss in an end-to-end manner, and experiments on a newly collected fine-grained pavement disease dataset show the effectiveness of our TB-Net.