 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Data-Centric Face Anti-Spoofing: Improving Cross-domain Generalization via Physics-based Data Synthesis
Sep 04, 2024Face Anti-Spoofing (FAS) research is challenged by the cross-domain problem, where there is a domain gap between the training and testing data. While recent FAS works are mainly model-centric, focusing on developing domain generalization algorithms for improving cross-domain performance, data-centric research for face anti-spoofing, improving generalization from data quality and quantity, is largely ignored. Therefore, our work starts with data-centric FAS by conducting a comprehensive investigation from the data perspective for improving cross-domain generalization of FAS models. More specifically, at first, based on physical procedures of capturing and recapturing, we propose task-specific FAS data augmentation (FAS-Aug), which increases data diversity by synthesizing data of artifacts, such as printing noise, color distortion, moir\'e pattern, \textit{etc}. Our experiments show that using our FAS augmentation can surpass traditional image augmentation in training FAS models to achieve better cross-domain performance. Nevertheless, we observe that models may rely on the augmented artifacts, which are not environment-invariant, and using FAS-Aug may have a negative effect. As such, we propose Spoofing Attack Risk Equalization (SARE) to prevent models from relying on certain types of artifacts and improve the generalization performance. Last but not least, our proposed FAS-Aug and SARE with recent Vision Transformer backbones can achieve state-of-the-art performance on the FAS cross-domain generalization protocols. The implementation is available at https://github.com/RizhaoCai/FAS_Aug.
Controllable and Gradual Facial Blemishes Retouching via Physics-Based Modelling
Jun 19, 2024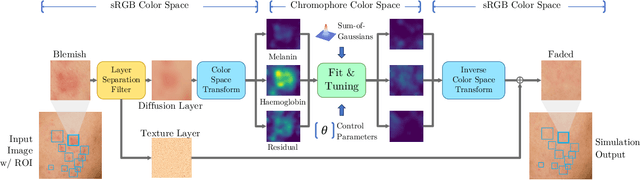
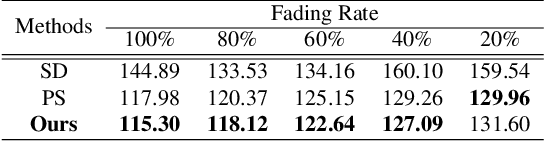
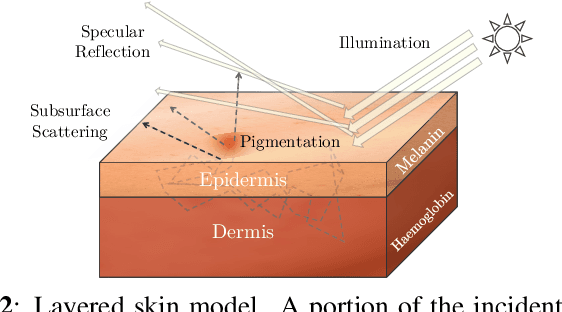
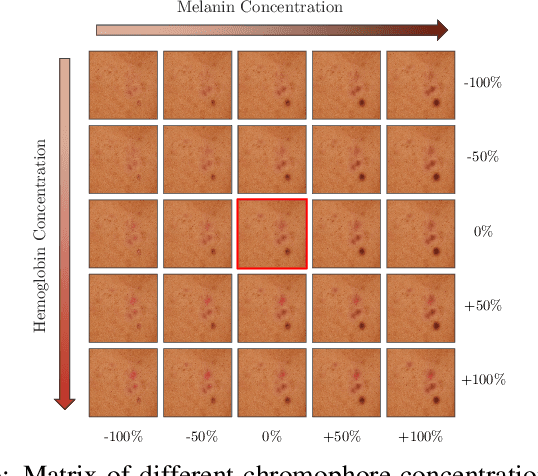
Face retouching aims to remove facial blemishes, such as pigmentation and acne, and still retain fine-grain texture details. Nevertheless, existing methods just remove the blemishes but focus little on realism of the intermediate process, limiting their use more to beautifying facial images on social media rather than being effective tools for simulating changes in facial pigmentation and ance. Motivated by this limitation, we propose our Controllable and Gradual Face Retouching (CGFR). Our CGFR is based on physical modelling, adopting Sum-of-Gaussians to approximate skin subsurface scattering in a decomposed melanin and haemoglobin color space. Our CGFR offers a user-friendly control over the facial blemishes, achieving realistic and gradual blemishes retouching. Experimental results based on actual clinical data shows that CGFR can realistically simulate the blemishes' gradual recovering process.
Suppress and Rebalance: Towards Generalized Multi-Modal Face Anti-Spoofing
Mar 05, 2024



Face Anti-Spoofing (FAS) is crucial for securing face recognition systems against presentation attacks. With advancements in sensor manufacture and multi-modal learning techniques, many multi-modal FAS approaches have emerged. However, they face challenges in generalizing to unseen attacks and deployment conditions. These challenges arise from (1) modality unreliability, where some modality sensors like depth and infrared undergo significant domain shifts in varying environments, leading to the spread of unreliable information during cross-modal feature fusion, and (2) modality imbalance, where training overly relies on a dominant modality hinders the convergence of others, reducing effectiveness against attack types that are indistinguishable sorely using the dominant modality. To address modality unreliability, we propose the Uncertainty-Guided Cross-Adapter (U-Adapter) to recognize unreliably detected regions within each modality and suppress the impact of unreliable regions on other modalities. For modality imbalance, we propose a Rebalanced Modality Gradient Modulation (ReGrad) strategy to rebalance the convergence speed of all modalities by adaptively adjusting their gradients. Besides, we provide the first large-scale benchmark for evaluating multi-modal FAS performance under domain generalization scenarios. Extensive experiments demonstrate that our method outperforms state-of-the-art methods. Source code and protocols will be released on https://github.com/OMGGGGG/mmdg.
BenchLMM: Benchmarking Cross-style Visual Capability of Large Multimodal Models
Dec 06, 2023



Large Multimodal Models (LMMs) such as GPT-4V and LLaVA have shown remarkable capabilities in visual reasoning with common image styles. However, their robustness against diverse style shifts, crucial for practical applications, remains largely unexplored. In this paper, we propose a new benchmark, BenchLMM, to assess the robustness of LMMs against three different styles: artistic image style, imaging sensor style, and application style, where each style has five sub-styles. Utilizing BenchLMM, we comprehensively evaluate state-of-the-art LMMs and reveal: 1) LMMs generally suffer performance degradation when working with other styles; 2) An LMM performs better than another model in common style does not guarantee its superior performance in other styles; 3) LMMs' reasoning capability can be enhanced by prompting LMMs to predict the style first, based on which we propose a versatile and training-free method for improving LMMs; 4) An intelligent LMM is expected to interpret the causes of its errors when facing stylistic variations. We hope that our benchmark and analysis can shed new light on developing more intelligent and versatile LMMs.
Forgery-aware Adaptive Vision Transformer for Face Forgery Detection
Sep 20, 2023With the advancement in face manipulation technologies, the importance of face forgery detection in protecting authentication integrity becomes increasingly evident. Previous Vision Transformer (ViT)-based detectors have demonstrated subpar performance in cross-database evaluations, primarily because fully fine-tuning with limited Deepfake data often leads to forgetting pre-trained knowledge and over-fitting to data-specific ones. To circumvent these issues, we propose a novel Forgery-aware Adaptive Vision Transformer (FA-ViT). In FA-ViT, the vanilla ViT's parameters are frozen to preserve its pre-trained knowledge, while two specially designed components, the Local-aware Forgery Injector (LFI) and the Global-aware Forgery Adaptor (GFA), are employed to adapt forgery-related knowledge. our proposed FA-ViT effectively combines these two different types of knowledge to form the general forgery features for detecting Deepfakes. Specifically, LFI captures local discriminative information and incorporates these information into ViT via Neighborhood-Preserving Cross Attention (NPCA). Simultaneously, GFA learns adaptive knowledge in the self-attention layer, bridging the gap between the two different domain. Furthermore, we design a novel Single Domain Pairwise Learning (SDPL) to facilitate fine-grained information learning in FA-ViT. The extensive experiments demonstrate that our FA-ViT achieves state-of-the-art performance in cross-dataset evaluation and cross-manipulation scenarios, and improves the robustness against unseen perturbations.
S-Adapter: Generalizing Vision Transformer for Face Anti-Spoofing with Statistical Tokens
Sep 07, 2023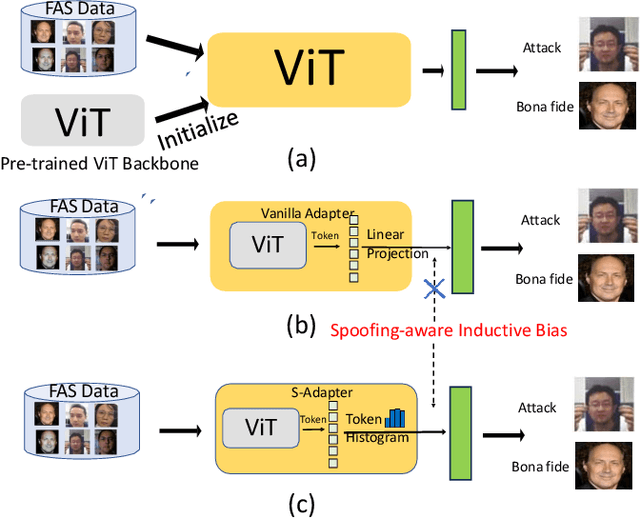
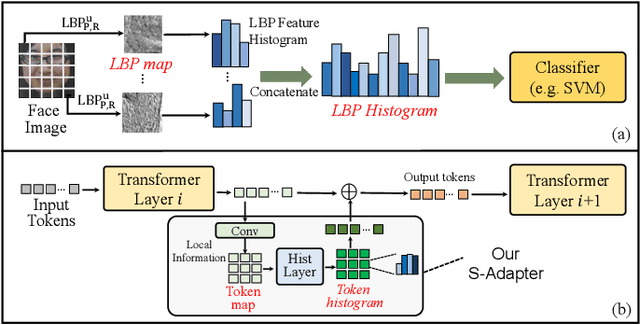
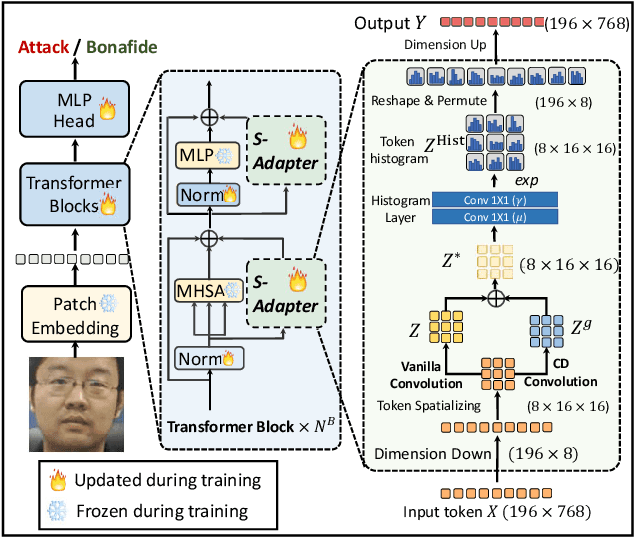
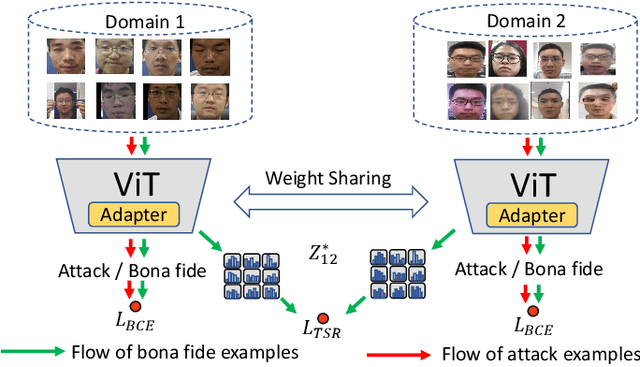
Face Anti-Spoofing (FAS) aims to detect malicious attempts to invade a face recognition system by presenting spoofed faces. State-of-the-art FAS techniques predominantly rely on deep learning models but their cross-domain generalization capabilities are often hindered by the domain shift problem, which arises due to different distributions between training and testing data. In this study, we develop a generalized FAS method under the Efficient Parameter Transfer Learning (EPTL) paradigm, where we adapt the pre-trained Vision Transformer models for the FAS task. During training, the adapter modules are inserted into the pre-trained ViT model, and the adapters are updated while other pre-trained parameters remain fixed. We find the limitations of previous vanilla adapters in that they are based on linear layers, which lack a spoofing-aware inductive bias and thus restrict the cross-domain generalization. To address this limitation and achieve cross-domain generalized FAS, we propose a novel Statistical Adapter (S-Adapter) that gathers local discriminative and statistical information from localized token histograms. To further improve the generalization of the statistical tokens, we propose a novel Token Style Regularization (TSR), which aims to reduce domain style variance by regularizing Gram matrices extracted from tokens across different domains. Our experimental results demonstrate that our proposed S-Adapter and TSR provide significant benefits in both zero-shot and few-shot cross-domain testing, outperforming state-of-the-art methods on several benchmark tests. We will release the source code upon acceptance.
Hyperbolic Face Anti-Spoofing
Aug 17, 2023



Learning generalized face anti-spoofing (FAS) models against presentation attacks is essential for the security of face recognition systems. Previous FAS methods usually encourage models to extract discriminative features, of which the distances within the same class (bonafide or attack) are pushed close while those between bonafide and attack are pulled away. However, these methods are designed based on Euclidean distance, which lacks generalization ability for unseen attack detection due to poor hierarchy embedding ability. According to the evidence that different spoofing attacks are intrinsically hierarchical, we propose to learn richer hierarchical and discriminative spoofing cues in hyperbolic space. Specifically, for unimodal FAS learning, the feature embeddings are projected into the Poincar\'e ball, and then the hyperbolic binary logistic regression layer is cascaded for classification. To further improve generalization, we conduct hyperbolic contrastive learning for the bonafide only while relaxing the constraints on diverse spoofing attacks. To alleviate the vanishing gradient problem in hyperbolic space, a new feature clipping method is proposed to enhance the training stability of hyperbolic models. Besides, we further design a multimodal FAS framework with Euclidean multimodal feature decomposition and hyperbolic multimodal feature fusion & classification. Extensive experiments on three benchmark datasets (i.e., WMCA, PADISI-Face, and SiW-M) with diverse attack types demonstrate that the proposed method can bring significant improvement compared to the Euclidean baselines on unseen attack detection. In addition, the proposed framework is also generalized well on four benchmark datasets (i.e., MSU-MFSD, IDIAP REPLAY-ATTACK, CASIA-FASD, and OULU-NPU) with a limited number of attack types.
Visual Prompt Flexible-Modal Face Anti-Spoofing
Jul 26, 2023Recently, vision transformer based multimodal learning methods have been proposed to improve the robustness of face anti-spoofing (FAS) systems. However, multimodal face data collected from the real world is often imperfect due to missing modalities from various imaging sensors. Recently, flexible-modal FAS~\cite{yu2023flexible} has attracted more attention, which aims to develop a unified multimodal FAS model using complete multimodal face data but is insensitive to test-time missing modalities. In this paper, we tackle one main challenge in flexible-modal FAS, i.e., when missing modality occurs either during training or testing in real-world situations. Inspired by the recent success of the prompt learning in language models, we propose \textbf{V}isual \textbf{P}rompt flexible-modal \textbf{FAS} (VP-FAS), which learns the modal-relevant prompts to adapt the frozen pre-trained foundation model to downstream flexible-modal FAS task. Specifically, both vanilla visual prompts and residual contextual prompts are plugged into multimodal transformers to handle general missing-modality cases, while only requiring less than 4\% learnable parameters compared to training the entire model. Furthermore, missing-modality regularization is proposed to force models to learn consistent multimodal feature embeddings when missing partial modalities. Extensive experiments conducted on two multimodal FAS benchmark datasets demonstrate the effectiveness of our VP-FAS framework that improves the performance under various missing-modality cases while alleviating the requirement of heavy model re-training.
Rehearsal-Free Domain Continual Face Anti-Spoofing: Generalize More and Forget Less
Mar 16, 2023



Face Anti-Spoofing (FAS) is recently studied under the continual learning setting, where the FAS models are expected to evolve after encountering the data from new domains. However, existing methods need extra replay buffers to store previous data for rehearsal, which becomes infeasible when previous data is unavailable because of privacy issues. In this paper, we propose the first rehearsal-free method for Domain Continual Learning (DCL) of FAS, which deals with catastrophic forgetting and unseen domain generalization problems simultaneously. For better generalization to unseen domains, we design the Dynamic Central Difference Convolutional Adapter (DCDCA) to adapt Vision Transformer (ViT) models during the continual learning sessions. To alleviate the forgetting of previous domains without using previous data, we propose the Proxy Prototype Contrastive Regularization (PPCR) to constrain the continual learning with previous domain knowledge from the proxy prototypes. Simulate practical DCL scenarios, we devise two new protocols which evaluate both generalization and anti-forgetting performance. Extensive experimental results show that our proposed method can improve the generalization performance in unseen domains and alleviate the catastrophic forgetting of the previous knowledge. The codes and protocols will be released soon.
Evaluating the Efficacy of Skincare Product: A Realistic Short-Term Facial Pore Simulation
Feb 23, 2023



Simulating the effects of skincare products on face is a potential new way to communicate the efficacy of skincare products in skin diagnostics and product recommendations. Furthermore, such simulations enable one to anticipate his/her skin conditions and better manage skin health. However, there is a lack of effective simulations today. In this paper, we propose the first simulation model to reveal facial pore changes after using skincare products. Our simulation pipeline consists of 2 steps: training data establishment and facial pore simulation. To establish training data, we collect face images with various pore quality indexes from short-term (8-weeks) clinical studies. People often experience significant skin fluctuations (due to natural rhythms, external stressors, etc.,), which introduces large perturbations in clinical data. To address this problem, we propose a sliding window mechanism to clean data and select representative index(es) to represent facial pore changes. Facial pore simulation stage consists of 3 modules: UNet-based segmentation module to localize facial pores; regression module to predict time-dependent warping hyperparameters; and deformation module, taking warping hyperparameters and pore segmentation labels as inputs, to precisely deform pores accordingly. The proposed simulation is able to render realistic facial pore changes. And this work will pave the way for future research in facial skin simulation and skincare product developments.