 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Anything Match Your Target: Universal Adversarial Perturbations against Closed-Source MLLMs via Multi-Crop Routed Meta Optimization
Jan 30, 2026Targeted adversarial attacks on closed-source multimodal large language models (MLLMs) have been increasingly explored under black-box transfer, yet prior methods are predominantly sample-specific and offer limited reusability across inputs. We instead study a more stringent setting, Universal Targeted Transferable Adversarial Attacks (UTTAA), where a single perturbation must consistently steer arbitrary inputs toward a specified target across unknown commercial MLLMs. Naively adapting existing sample-wise attacks to this universal setting faces three core difficulties: (i) target supervision becomes high-variance due to target-crop randomness, (ii) token-wise matching is unreliable because universality suppresses image-specific cues that would otherwise anchor alignment, and (iii) few-source per-target adaptation is highly initialization-sensitive, which can degrade the attainable performance. In this work, we propose MCRMO-Attack, which stabilizes supervision via Multi-Crop Aggregation with an Attention-Guided Crop, improves token-level reliability through alignability-gated Token Routing, and meta-learns a cross-target perturbation prior that yields stronger per-target solutions. Across commercial MLLMs, we boost unseen-image attack success rate by +23.7\% on GPT-4o and +19.9\% on Gemini-2.0 over the strongest universal baseline.
Learning Representation and Synergy Invariances: A Povable Framework for Generalized Multimodal Face Anti-Spoofing
Nov 18, 2025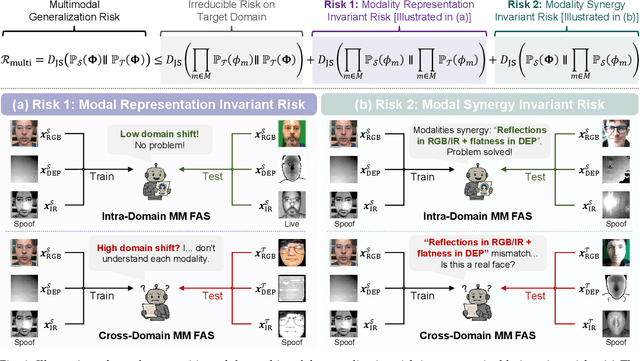

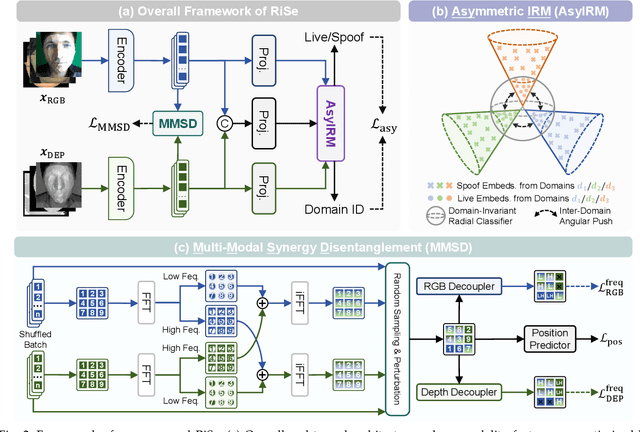
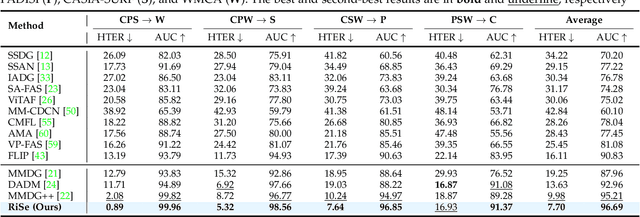
Multimodal Face Anti-Spoofing (FAS) methods, which integrate multiple visual modalities, often suffer even more severe performance degradation than unimodal FAS when deployed in unseen domains. This is mainly due to two overlooked risks that affect cross-domain multimodal generalization. The first is the modal representation invariant risk, i.e., whether representations remain generalizable under domain shift. We theoretically show that the inherent class asymmetry in FAS (diverse spoofs vs. compact reals) enlarges the upper bound of generalization error, and this effect is further amplified in multimodal settings. The second is the modal synergy invariant risk, where models overfit to domain-specific inter-modal correlations. Such spurious synergy cannot generalize to unseen attacks in target domains, leading to performance drops. To solve these issues, we propose a provable framework, namely Multimodal Representation and Synergy Invariance Learning (RiSe). For representation risk, RiSe introduces Asymmetric Invariant Risk Minimization (AsyIRM), which learns an invariant spherical decision boundary in radial space to fit asymmetric distributions, while preserving domain cues in angular space. For synergy risk, RiSe employs Multimodal Synergy Disentanglement (MMSD), a self-supervised task enhancing intrinsic, generalizable modal features via cross-sample mixing and disentanglement. Theoretical analysis and experiments verify RiSe, which achieves state-of-the-art cross-domain performance.
From Pretrain to Pain: Adversarial Vulnerability of Video Foundation Models Without Task Knowledge
Nov 10, 2025Large-scale Video Foundation Models (VFMs) has significantly advanced various video-related tasks, either through task-specific models or Multi-modal Large Language Models (MLLMs). However, the open accessibility of VFMs also introduces critical security risks, as adversaries can exploit full knowledge of the VFMs to launch potent attacks. This paper investigates a novel and practical adversarial threat scenario: attacking downstream models or MLLMs fine-tuned from open-source VFMs, without requiring access to the victim task, training data, model query, and architecture. In contrast to conventional transfer-based attacks that rely on task-aligned surrogate models, we demonstrate that adversarial vulnerabilities can be exploited directly from the VFMs. To this end, we propose the Transferable Video Attack (TVA), a temporal-aware adversarial attack method that leverages the temporal representation dynamics of VFMs to craft effective perturbations. TVA integrates a bidirectional contrastive learning mechanism to maximize the discrepancy between the clean and adversarial features, and introduces a temporal consistency loss that exploits motion cues to enhance the sequential impact of perturbations. TVA avoids the need to train expensive surrogate models or access to domain-specific data, thereby offering a more practical and efficient attack strategy. Extensive experiments across 24 video-related tasks demonstrate the efficacy of TVA against downstream models and MLLMs, revealing a previously underexplored security vulnerability in the deployment of video models.
Diversity Covariance-Aware Prompt Learning for Vision-Language Models
Mar 03, 2025Prompt tuning can further enhance the performance of visual-language models across various downstream tasks (e.g., few-shot learning), enabling them to better adapt to specific applications and needs. In this paper, we present a Diversity Covariance-Aware framework that learns distributional information from the data to enhance the few-shot ability of the prompt model. First, we propose a covariance-aware method that models the covariance relationships between visual features and uses anisotropic Mahalanobis distance, instead of the suboptimal cosine distance, to measure the similarity between two modalities. We rigorously derive and prove the validity of this modeling process. Then, we propose the diversity-aware method, which learns multiple diverse soft prompts to capture different attributes of categories and aligns them independently with visual modalities. This method achieves multi-centered covariance modeling, leading to more diverse decision boundaries. Extensive experiments on 11 datasets in various tasks demonstrate the effectiveness of our method.
Space Rotation with Basis Transformation for Training-free Test-Time Adaptation
Feb 27, 2025With the development of visual-language models (VLM) in downstream task applications, test-time adaptation methods based on VLM have attracted increasing attention for their ability to address changes distribution in test-time. Although prior approaches have achieved some progress, they typically either demand substantial computational resources or are constrained by the limitations of the original feature space, rendering them less effective for test-time adaptation tasks. To address these challenges, we propose a training-free feature space rotation with basis transformation for test-time adaptation. By leveraging the inherent distinctions among classes, we reconstruct the original feature space and map it to a new representation, thereby enhancing the clarity of class differences and providing more effective guidance for the model during testing. Additionally, to better capture relevant information from various classes, we maintain a dynamic queue to store representative samples. Experimental results across multiple benchmarks demonstrate that our method outperforms state-of-the-art techniques in terms of both performance and efficiency.
Backdoor Attacks against No-Reference Image Quality Assessment Models via A Scalable Trigger
Dec 10, 2024



No-Reference Image Quality Assessment (NR-IQA), responsible for assessing the quality of a single input image without using any reference, plays a critical role in evaluating and optimizing computer vision systems, e.g., low-light enhancement. Recent research indicates that NR-IQA models are susceptible to adversarial attacks, which can significantly alter predicted scores with visually imperceptible perturbations. Despite revealing vulnerabilities, these attack methods have limitations, including high computational demands, untargeted manipulation, limited practical utility in white-box scenarios, and reduced effectiveness in black-box scenarios. To address these challenges, we shift our focus to another significant threat and present a novel poisoning-based backdoor attack against NR-IQA (BAIQA), allowing the attacker to manipulate the IQA model's output to any desired target value by simply adjusting a scaling coefficient $\alpha$ for the trigger. We propose to inject the trigger in the discrete cosine transform (DCT) domain to improve the local invariance of the trigger for countering trigger diminishment in NR-IQA models due to widely adopted data augmentations. Furthermore, the universal adversarial perturbations (UAP) in the DCT space are designed as the trigger, to increase IQA model susceptibility to manipulation and improve attack effectiveness. In addition to the heuristic method for poison-label BAIQA (P-BAIQA), we explore the design of clean-label BAIQA (C-BAIQA), focusing on $\alpha$ sampling and image data refinement, driven by theoretical insights we reveal. Extensive experiments on diverse datasets and various NR-IQA models demonstrate the effectiveness of our attacks. Code will be released at https://github.com/yuyi-sd/BAIQA.
LOBG:Less Overfitting for Better Generalization in Vision-Language Model
Oct 14, 2024Existing prompt learning methods in Vision-Language Models (VLM) have effectively enhanced the transfer capability of VLM to downstream tasks, but they suffer from a significant decline in generalization due to severe overfitting. To address this issue, we propose a framework named LOBG for vision-language models. Specifically, we use CLIP to filter out fine-grained foreground information that might cause overfitting, thereby guiding prompts with basic visual concepts. To further mitigate overfitting, we devel oped a structural topology preservation (STP) loss at the feature level, which endows the feature space with overall plasticity, allowing effective reshaping of the feature space during optimization. Additionally, we employed hierarchical logit distilation (HLD) at the output level to constrain outputs, complementing STP at the output end. Extensive experimental results demonstrate that our method significantly improves generalization capability and alleviates overfitting compared to state-of-the-art approaches.
Towards Data-Centric Face Anti-Spoofing: Improving Cross-domain Generalization via Physics-based Data Synthesis
Sep 04, 2024Face Anti-Spoofing (FAS) research is challenged by the cross-domain problem, where there is a domain gap between the training and testing data. While recent FAS works are mainly model-centric, focusing on developing domain generalization algorithms for improving cross-domain performance, data-centric research for face anti-spoofing, improving generalization from data quality and quantity, is largely ignored. Therefore, our work starts with data-centric FAS by conducting a comprehensive investigation from the data perspective for improving cross-domain generalization of FAS models. More specifically, at first, based on physical procedures of capturing and recapturing, we propose task-specific FAS data augmentation (FAS-Aug), which increases data diversity by synthesizing data of artifacts, such as printing noise, color distortion, moir\'e pattern, \textit{etc}. Our experiments show that using our FAS augmentation can surpass traditional image augmentation in training FAS models to achieve better cross-domain performance. Nevertheless, we observe that models may rely on the augmented artifacts, which are not environment-invariant, and using FAS-Aug may have a negative effect. As such, we propose Spoofing Attack Risk Equalization (SARE) to prevent models from relying on certain types of artifacts and improve the generalization performance. Last but not least, our proposed FAS-Aug and SARE with recent Vision Transformer backbones can achieve state-of-the-art performance on the FAS cross-domain generalization protocols. The implementation is available at https://github.com/RizhaoCai/FAS_Aug.
Towards Physical World Backdoor Attacks against Skeleton Action Recognition
Aug 16, 2024Skeleton Action Recognition (SAR) has attracted significant interest for its efficient representation of the human skeletal structure. Despite its advancements, recent studies have raised security concerns in SAR models, particularly their vulnerability to adversarial attacks. However, such strategies are limited to digital scenarios and ineffective in physical attacks, limiting their real-world applicability. To investigate the vulnerabilities of SAR in the physical world, we introduce the Physical Skeleton Backdoor Attacks (PSBA), the first exploration of physical backdoor attacks against SAR. Considering the practicalities of physical execution, we introduce a novel trigger implantation method that integrates infrequent and imperceivable actions as triggers into the original skeleton data. By incorporating a minimal amount of this manipulated data into the training set, PSBA enables the system misclassify any skeleton sequences into the target class when the trigger action is present. We examine the resilience of PSBA in both poisoned and clean-label scenarios, demonstrating its efficacy across a range of datasets, poisoning ratios, and model architectures. Additionally, we introduce a trigger-enhancing strategy to strengthen attack performance in the clean label setting. The robustness of PSBA is tested against three distinct backdoor defenses, and the stealthiness of PSBA is evaluated using two quantitative metrics. Furthermore, by employing a Kinect V2 camera, we compile a dataset of human actions from the real world to mimic physical attack situations, with our findings confirming the effectiveness of our proposed attacks. Our project website can be found at https://qichenzheng.github.io/psba-website.
Unlearnable Examples Detection via Iterative Filtering
Aug 15, 2024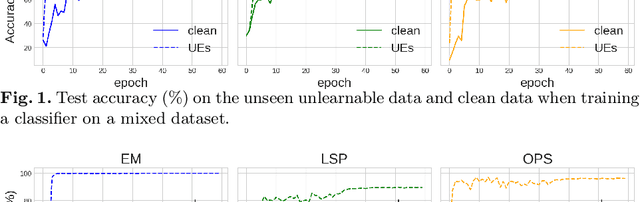
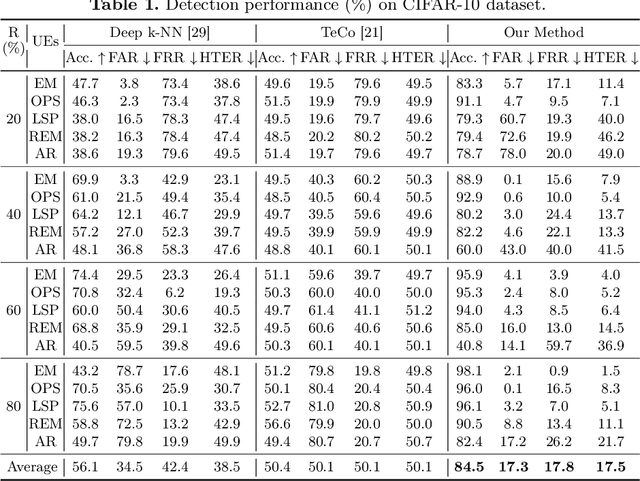
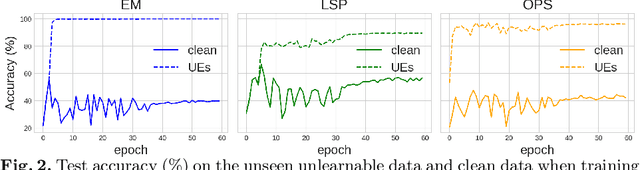
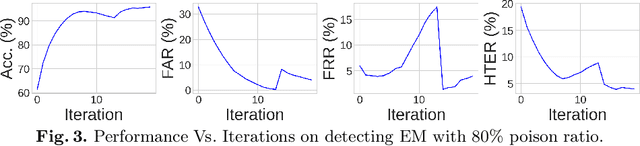
Deep neural networks are proven to be vulnerable to data poisoning attacks. Recently, a specific type of data poisoning attack known as availability attacks has led to the failure of data utilization for model learning by adding imperceptible perturbations to images. Consequently, it is quite beneficial and challenging to detect poisoned samples, also known as Unlearnable Examples (UEs), from a mixed dataset. In response, we propose an Iterative Filtering approach for UEs identification. This method leverages the distinction between the inherent semantic mapping rules and shortcuts, without the need for any additional information. We verify that when training a classifier on a mixed dataset containing both UEs and clean data, the model tends to quickly adapt to the UEs compared to the clean data. Due to the accuracy gaps between training with clean/poisoned samples, we employ a model to misclassify clean samples while correctly identifying the poisoned ones. The incorporation of additional classes and iterative refinement enhances the model's ability to differentiate between clean and poisoned samples. Extensive experiments demonstrate the superiority of our method over state-of-the-art detection approaches across various attacks, datasets, and poison ratios, significantly reducing the Half Total Error Rate (HTER) compared to existing methods.