 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Anything Match Your Target: Universal Adversarial Perturbations against Closed-Source MLLMs via Multi-Crop Routed Meta Optimization
Jan 30, 2026Targeted adversarial attacks on closed-source multimodal large language models (MLLMs) have been increasingly explored under black-box transfer, yet prior methods are predominantly sample-specific and offer limited reusability across inputs. We instead study a more stringent setting, Universal Targeted Transferable Adversarial Attacks (UTTAA), where a single perturbation must consistently steer arbitrary inputs toward a specified target across unknown commercial MLLMs. Naively adapting existing sample-wise attacks to this universal setting faces three core difficulties: (i) target supervision becomes high-variance due to target-crop randomness, (ii) token-wise matching is unreliable because universality suppresses image-specific cues that would otherwise anchor alignment, and (iii) few-source per-target adaptation is highly initialization-sensitive, which can degrade the attainable performance. In this work, we propose MCRMO-Attack, which stabilizes supervision via Multi-Crop Aggregation with an Attention-Guided Crop, improves token-level reliability through alignability-gated Token Routing, and meta-learns a cross-target perturbation prior that yields stronger per-target solutions. Across commercial MLLMs, we boost unseen-image attack success rate by +23.7\% on GPT-4o and +19.9\% on Gemini-2.0 over the strongest universal baseline.
One Small Step with Fingerprints, One Giant Leap for emph{De Novo} Molecule Generation from Mass Spectra
Aug 06, 2025
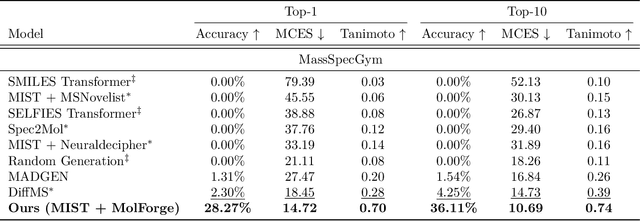

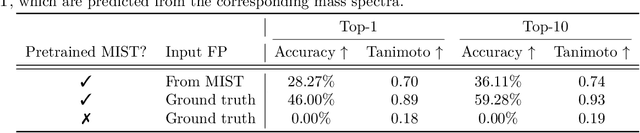
A common approach to the \emph{de novo} molecular generation problem from mass spectra involves a two-stage pipeline: (1) encoding mass spectra into molecular fingerprints, followed by (2) decoding these fingerprints into molecular structures. In our work, we adopt \textsc{MIST}~\citep{MISTgoldmanAnnotatingMetaboliteMass2023} as the encoder and \textsc{MolForge}~\citep{ucakReconstructionLosslessMolecular2023} as the decoder, leveraging pretraining to enhance performance. Notably, pretraining \textsc{MolForge} proves especially effective, enabling it to serve as a robust fingerprint-to-structure decoder. Additionally, instead of passing the probability of each bit in the fingerprint, thresholding the probabilities as a step function helps focus the decoder on the presence of substructures, improving recovery of accurate molecular structures even when the fingerprints predicted by \textsc{MIST} only moderately resembles the ground truth in terms of Tanimoto similarity. This combination of encoder and decoder results in a tenfold improvement over previous state-of-the-art methods, generating top-1 28\% / top-10 36\% of molecular structures correctly from mass spectra. We position this pipeline as a strong baseline for future research in \emph{de novo} molecule elucidation from mass spectra.
Safety Mirage: How Spurious Correlations Undermine VLM Safety Fine-tuning
Mar 14, 2025Recent vision-language models (VLMs) have made remarkable strides in generative modeling with multimodal inputs, particularly text and images. However, their susceptibility to generating harmful content when exposed to unsafe queries raises critical safety concerns. While current alignment strategies primarily rely on supervised safety fine-tuning with curated datasets, we identify a fundamental limitation we call the "safety mirage" where supervised fine-tuning inadvertently reinforces spurious correlations between superficial textual patterns and safety responses, rather than fostering deep, intrinsic mitigation of harm. We show that these spurious correlations leave fine-tuned VLMs vulnerable even to a simple one-word modification-based attack, where substituting a single word in text queries with a spurious correlation-inducing alternative can effectively bypass safeguards. Additionally, these correlations contribute to the over prudence, causing fine-tuned VLMs to refuse benign queries unnecessarily. To address this issue, we show machine unlearning (MU) as a powerful alternative to supervised safety fine-tuning as it avoids biased feature-label mappings and directly removes harmful knowledge from VLMs while preserving their general capabilities. Extensive evaluations across safety benchmarks show that under one-word attacks, MU-based alignment reduces the attack success rate by up to 60.17% and cuts unnecessary rejections by over 84.20%. Codes are available at https://github.com/OPTML-Group/VLM-Safety-MU. WARNING: There exist AI generations that may be offensive in nature.
Defending Multimodal Backdoored Models by Repulsive Visual Prompt Tuning
Dec 29, 2024



Multimodal contrastive learning models (e.g., CLIP) can learn high-quality representations from large-scale image-text datasets, yet they exhibit significant vulnerabilities to backdoor attacks, raising serious safety concerns. In this paper, we disclose that CLIP's vulnerabilities primarily stem from its excessive encoding of class-irrelevant features, which can compromise the model's visual feature resistivity to input perturbations, making it more susceptible to capturing the trigger patterns inserted by backdoor attacks. Inspired by this finding, we propose Repulsive Visual Prompt Tuning (RVPT), a novel defense approach that employs specially designed deep visual prompt tuning and feature-repelling loss to eliminate excessive class-irrelevant features while simultaneously optimizing cross-entropy loss to maintain clean accuracy. Unlike existing multimodal backdoor defense methods that typically require the availability of poisoned data or involve fine-tuning the entire model, RVPT leverages few-shot downstream clean samples and only tunes a small number of parameters. Empirical results demonstrate that RVPT tunes only 0.27\% of the parameters relative to CLIP, yet it significantly outperforms state-of-the-art baselines, reducing the attack success rate from 67.53\% to 2.76\% against SoTA attacks and effectively generalizing its defensive capabilities across multiple datasets.
Semantic Deep Hiding for Robust Unlearnable Examples
Jun 25, 2024



Ensuring data privacy and protection has become paramount in the era of deep learning. Unlearnable examples are proposed to mislead the deep learning models and prevent data from unauthorized exploration by adding small perturbations to data. However, such perturbations (e.g., noise, texture, color change) predominantly impact low-level features, making them vulnerable to common countermeasures. In contrast, semantic images with intricate shapes have a wealth of high-level features, making them more resilient to countermeasures and potential for producing robust unlearnable examples. In this paper, we propose a Deep Hiding (DH) scheme that adaptively hides semantic images enriched with high-level features. We employ an Invertible Neural Network (INN) to invisibly integrate predefined images, inherently hiding them with deceptive perturbations. To enhance data unlearnability, we introduce a Latent Feature Concentration module, designed to work with the INN, regularizing the intra-class variance of these perturbations. To further boost the robustness of unlearnable examples, we design a Semantic Images Generation module that produces hidden semantic images. By utilizing similar semantic information, this module generates similar semantic images for samples within the same classes, thereby enlarging the inter-class distance and narrowing the intra-class distance. Extensive experiments on CIFAR-10, CIFAR-100, and an ImageNet subset, against 18 countermeasures, reveal that our proposed method exhibits outstanding robustness for unlearnable examples, demonstrating its efficacy in preventing unauthorized data exploitation.
Benchmarking Cross-Domain Audio-Visual Deception Detection
May 11, 2024



Automated deception detection is crucial for assisting humans in accurately assessing truthfulness and identifying deceptive behavior. Conventional contact-based techniques, like polygraph devices, rely on physiological signals to determine the authenticity of an individual's statements. Nevertheless, recent developments in automated deception detection have demonstrated that multimodal features derived from both audio and video modalities may outperform human observers on publicly available datasets. Despite these positive findings, the generalizability of existing audio-visual deception detection approaches across different scenarios remains largely unexplored. To close this gap, we present the first cross-domain audio-visual deception detection benchmark, that enables us to assess how well these methods generalize for use in real-world scenarios. We used widely adopted audio and visual features and different architectures for benchmarking, comparing single-to-single and multi-to-single domain generalization performance. To further exploit the impacts using data from multiple source domains for training, we investigate three types of domain sampling strategies, including domain-simultaneous, domain-alternating, and domain-by-domain for multi-to-single domain generalization evaluation. Furthermore, we proposed the Attention-Mixer fusion method to improve performance, and we believe that this new cross-domain benchmark will facilitate future research in audio-visual deception detection. Protocols and source code are available at \href{https://github.com/Redaimao/cross_domain_DD}{https://github.com/Redaimao/cross\_domain\_DD}.
Improving Concept Alignment in Vision-Language Concept Bottleneck Models
May 03, 2024
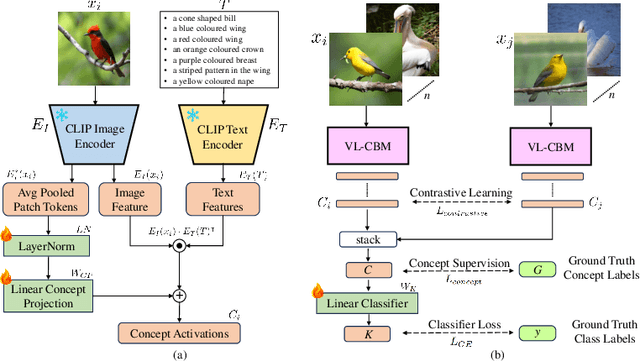


Concept Bottleneck Models (CBM) map the input image to a high-level human-understandable concept space and then make class predictions based on these concepts. Recent approaches automate the construction of CBM by prompting Large Language Models (LLM) to generate text concepts and then use Vision Language Models (VLM) to obtain concept scores to train a CBM. However, it is desired to build CBMs with concepts defined by human experts instead of LLM generated concepts to make them more trustworthy. In this work, we take a closer inspection on the faithfulness of VLM concept scores for such expert-defined concepts in domains like fine-grain bird species classification and animal classification. Our investigations reveal that frozen VLMs, like CLIP, struggle to correctly associate a concept to the corresponding visual input despite achieving a high classification performance. To address this, we propose a novel Contrastive Semi-Supervised (CSS) learning method which uses a few labeled concept examples to improve concept alignment (activate truthful visual concepts) in CLIP model. Extensive experiments on three benchmark datasets show that our approach substantially increases the concept accuracy and classification accuracy, yet requires only a fraction of the human-annotated concept labels. To further improve the classification performance, we also introduce a new class-level intervention procedure for fine-grain classification problems that identifies the confounding classes and intervenes their concept space to reduce errors.
Backdoor Secrets Unveiled: Identifying Backdoor Data with Optimized Scaled Prediction Consistency
Mar 15, 2024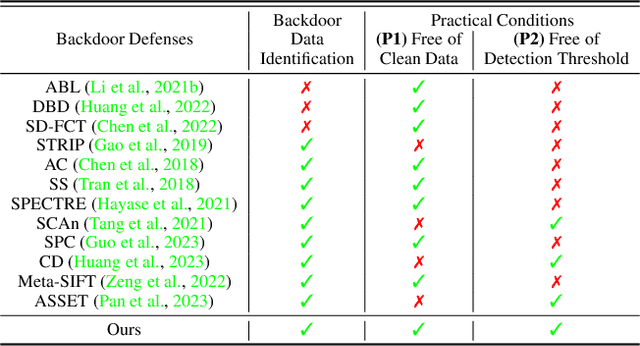


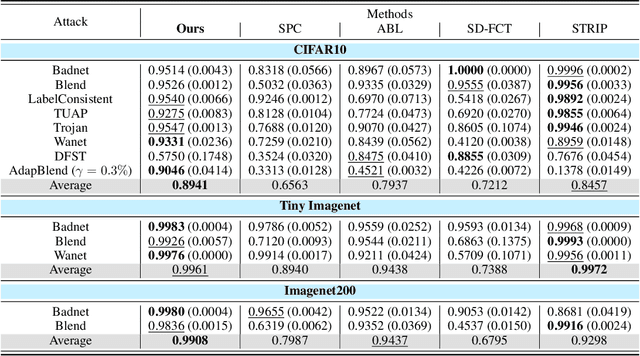
Modern machine learning (ML) systems demand substantial training data, often resorting to external sources. Nevertheless, this practice renders them vulnerable to backdoor poisoning attacks. Prior backdoor defense strategies have primarily focused on the identification of backdoored models or poisoned data characteristics, typically operating under the assumption of access to clean data. In this work, we delve into a relatively underexplored challenge: the automatic identification of backdoor data within a poisoned dataset, all under realistic conditions, i.e., without the need for additional clean data or without manually defining a threshold for backdoor detection. We draw an inspiration from the scaled prediction consistency (SPC) technique, which exploits the prediction invariance of poisoned data to an input scaling factor. Based on this, we pose the backdoor data identification problem as a hierarchical data splitting optimization problem, leveraging a novel SPC-based loss function as the primary optimization objective. Our innovation unfolds in several key aspects. First, we revisit the vanilla SPC method, unveiling its limitations in addressing the proposed backdoor identification problem. Subsequently, we develop a bi-level optimization-based approach to precisely identify backdoor data by minimizing the advanced SPC loss. Finally, we demonstrate the efficacy of our proposal against a spectrum of backdoor attacks, encompassing basic label-corrupted attacks as well as more sophisticated clean-label attacks, evaluated across various benchmark datasets. Experiment results show that our approach often surpasses the performance of current baselines in identifying backdoor data points, resulting in about 4%-36% improvement in average AUROC. Codes are available at https://github.com/OPTML-Group/BackdoorMSPC.
From Trojan Horses to Castle Walls: Unveiling Bilateral Backdoor Effects in Diffusion Models
Nov 04, 2023



While state-of-the-art diffusion models (DMs) excel in image generation, concerns regarding their security persist. Earlier research highlighted DMs' vulnerability to backdoor attacks, but these studies placed stricter requirements than conventional methods like 'BadNets' in image classification. This is because the former necessitates modifications to the diffusion sampling and training procedures. Unlike the prior work, we investigate whether generating backdoor attacks in DMs can be as simple as BadNets, i.e., by only contaminating the training dataset without tampering the original diffusion process. In this more realistic backdoor setting, we uncover bilateral backdoor effects that not only serve an adversarial purpose (compromising the functionality of DMs) but also offer a defensive advantage (which can be leveraged for backdoor defense). Specifically, we find that a BadNets-like backdoor attack remains effective in DMs for producing incorrect images (misaligned with the intended text conditions), and thereby yielding incorrect predictions when DMs are used as classifiers. Meanwhile, backdoored DMs exhibit an increased ratio of backdoor triggers, a phenomenon we refer to as `trigger amplification', among the generated images. We show that this latter insight can be used to enhance the detection of backdoor-poisoned training data. Even under a low backdoor poisoning ratio, studying the backdoor effects of DMs is also valuable for designing anti-backdoor image classifiers. Last but not least, we establish a meaningful linkage between backdoor attacks and the phenomenon of data replications by exploring DMs' inherent data memorization tendencies. The codes of our work are available at https://github.com/OPTML-Group/BiBadDiff.
Tackling VQA with Pretrained Foundation Models without Further Training
Sep 27, 2023



Large language models (LLMs) have achieved state-of-the-art results in many natural language processing tasks. They have also demonstrated ability to adapt well to different tasks through zero-shot or few-shot settings. With the capability of these LLMs, researchers have looked into how to adopt them for use with Visual Question Answering (VQA). Many methods require further training to align the image and text embeddings. However, these methods are computationally expensive and requires large scale image-text dataset for training. In this paper, we explore a method of combining pretrained LLMs and other foundation models without further training to solve the VQA problem. The general idea is to use natural language to represent the images such that the LLM can understand the images. We explore different decoding strategies for generating textual representation of the image and evaluate their performance on the VQAv2 dataset.