 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestAlign: Overcoming Data Scarcity in Aligning Large Language Models with Investor Decision-Making Processes under Herd Behavior
Jul 09, 2025Aligning Large Language Models (LLMs) with investor decision-making processes under herd behavior is a critical challenge in behavioral finance, which grapples with a fundamental limitation: the scarcity of real-user data needed for Supervised Fine-Tuning (SFT). While SFT can bridge the gap between LLM outputs and human behavioral patterns, its reliance on massive authentic data imposes substantial collection costs and privacy risks. We propose InvestAlign, a novel framework that constructs high-quality SFT datasets by leveraging theoretical solutions to similar and simple optimal investment problems rather than complex scenarios. Our theoretical analysis demonstrates that training LLMs with InvestAlign-generated data achieves faster parameter convergence than using real-user data, suggesting superior learning efficiency. Furthermore, we develop InvestAgent, an LLM agent fine-tuned with InvestAlign, which demonstrates significantly closer alignment to real-user data than pre-SFT models in both simple and complex investment problems. This highlights our proposed InvestAlign as a promising approach with the potential to address complex optimal investment problems and align LLMs with investor decision-making processes under herd behavior. Our code is publicly available at https://github.com/thu-social-network-research-group/InvestAlign.
Lightweight Transformer via Unrolling of Mixed Graph Algorithms for Traffic Forecast
May 19, 2025
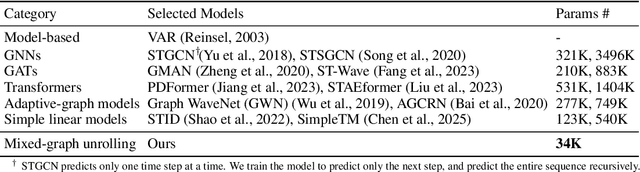

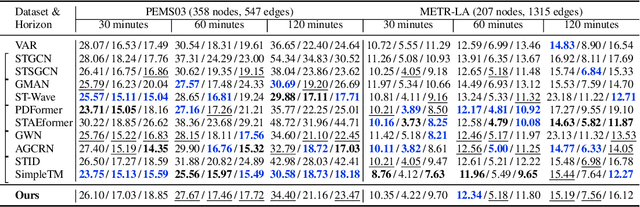
To forecast traffic with both spatial and temporal dimensions, we unroll a mixed-graph-based optimization algorithm into a lightweight and interpretable transformer-like neural net. Specifically, we construct two graphs: an undirected graph $\mathcal{G}^u$ capturing spatial correlations across geography, and a directed graph $\mathcal{G}^d$ capturing sequential relationships over time. We formulate a prediction problem for the future samples of signal $\mathbf{x}$, assuming it is "smooth" with respect to both $\mathcal{G}^u$ and $\mathcal{G}^d$, where we design new $\ell_2$ and $\ell_1$-norm variational terms to quantify and promote signal smoothness (low-frequency reconstruction) on a directed graph. We construct an iterative algorithm based on alternating direction method of multipliers (ADMM), and unroll it into a feed-forward network for data-driven parameter learning. We insert graph learning modules for $\mathcal{G}^u$ and $\mathcal{G}^d$, which are akin to the self-attention mechanism in classical transformers. Experiments show that our unrolled networks achieve competitive traffic forecast performance as state-of-the-art prediction schemes, while reducing parameter counts drastically. Our code is available in https://github.com/SingularityUndefined/Unrolling-GSP-STForecast.
On Memory Construction and Retrieval for Personalized Conversational Agents
Feb 08, 2025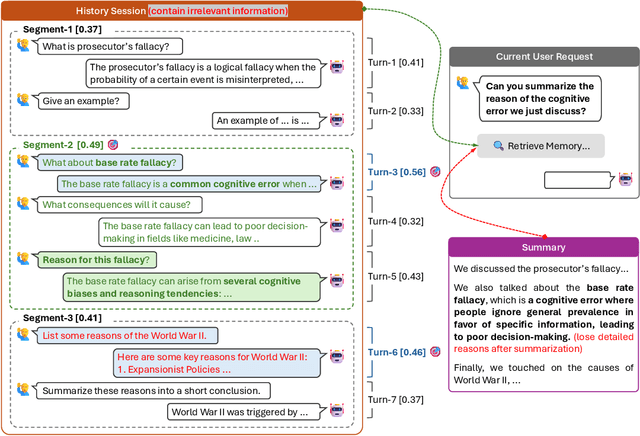
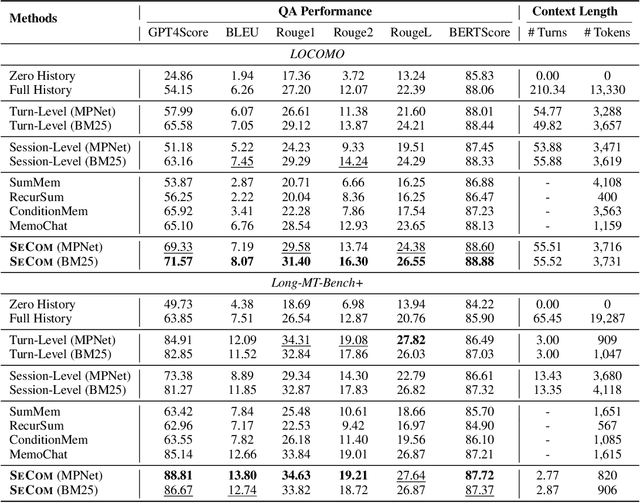
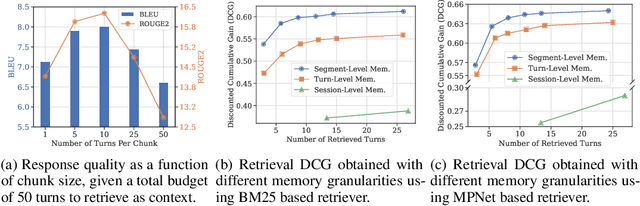

To deliver coherent and personalized experiences in long-term conversations, existing approaches typically perform retrieval augmented response generation by constructing memory banks from conversation history at either the turn-level, session-level, or through summarization techniques. In this paper, we present two key findings: (1) The granularity of memory unit matters: Turn-level, session-level, and summarization-based methods each exhibit limitations in both memory retrieval accuracy and the semantic quality of the retrieved content. (2) Prompt compression methods, such as \textit{LLMLingua-2}, can effectively serve as a denoising mechanism, enhancing memory retrieval accuracy across different granularities. Building on these insights, we propose SeCom, a method that constructs a memory bank with topical segments by introducing a conversation Segmentation model, while performing memory retrieval based on Compressed memory units. Experimental results show that SeCom outperforms turn-level, session-level, and several summarization-based methods on long-term conversation benchmarks such as LOCOMO and Long-MT-Bench+. Additionally, the proposed conversation segmentation method demonstrates superior performance on dialogue segmentation datasets such as DialSeg711, TIAGE, and SuperDialSeg.
UniGAD: Unifying Multi-level Graph Anomaly Detection
Nov 10, 2024



Graph Anomaly Detection (GAD) aims to identify uncommon, deviated, or suspicious objects within graph-structured data. Existing methods generally focus on a single graph object type (node, edge, graph, etc.) and often overlook the inherent connections among different object types of graph anomalies. For instance, a money laundering transaction might involve an abnormal account and the broader community it interacts with. To address this, we present UniGAD, the first unified framework for detecting anomalies at node, edge, and graph levels jointly. Specifically, we develop the Maximum Rayleigh Quotient Subgraph Sampler (MRQSampler) that unifies multi-level formats by transferring objects at each level into graph-level tasks on subgraphs. We theoretically prove that MRQSampler maximizes the accumulated spectral energy of subgraphs (i.e., the Rayleigh quotient) to preserve the most significant anomaly information. To further unify multi-level training, we introduce a novel GraphStitch Network to integrate information across different levels, adjust the amount of sharing required at each level, and harmonize conflicting training goals. Comprehensive experiments show that UniGAD outperforms both existing GAD methods specialized for a single task and graph prompt-based approaches for multiple tasks, while also providing robust zero-shot task transferability. All codes can be found at https://github.com/lllyyq1121/UniGAD.
LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Mar 19, 2024



This paper focuses on task-agnostic prompt compression for better generalizability and efficiency. Considering the redundancy in natural language, existing approaches compress prompts by removing tokens or lexical units according to their information entropy obtained from a causal language model such as LLaMa-7B. The challenge is that information entropy may be a suboptimal compression metric: (i) it only leverages unidirectional context and may fail to capture all essential information needed for prompt compression; (ii) it is not aligned with the prompt compression objective. To address these issues, we propose a data distillation procedure to derive knowledge from an LLM to compress prompts without losing crucial information, and meantime, introduce an extractive text compression dataset. We formulate prompt compression as a token classification problem to guarantee the faithfulness of the compressed prompt to the original one, and use a Transformer encoder as the base architecture to capture all essential information for prompt compression from the full bidirectional context. Our approach leads to lower latency by explicitly learning the compression objective with smaller models such as XLM-RoBERTa-large and mBERT. We evaluate our method on both in-domain and out-of-domain datasets, including MeetingBank, LongBench, ZeroScrolls, GSM8K, and BBH. Despite its small size, our model shows significant performance gains over strong baselines and demonstrates robust generalization ability across different LLMs. Additionally, our model is 3x-6x faster than existing prompt compression methods, while accelerating the end-to-end latency by 1.6x-2.9x with compression ratios of 2x-5x.
Message-Enhanced DeGroot Model
Feb 29, 2024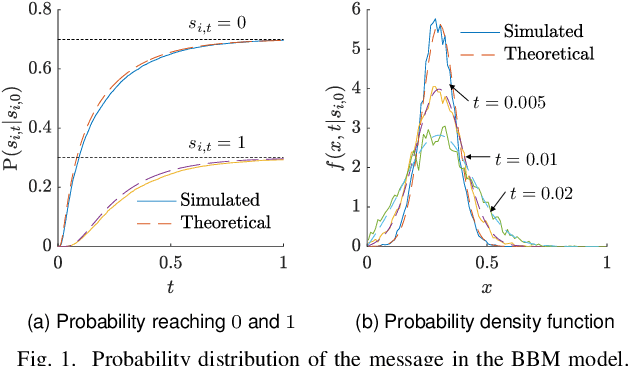
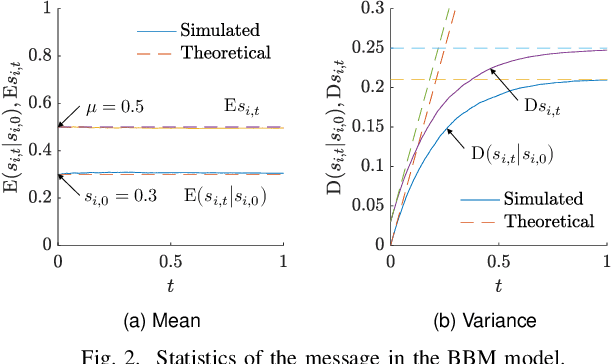
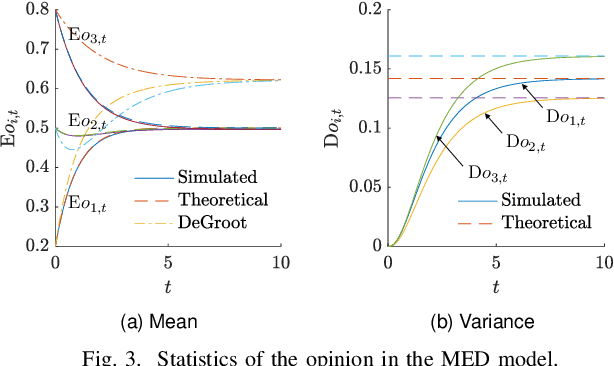
Understanding the impact of messages on agents' opinions over social networks is important. However, to our best knowledge, there has been limited quantitative investigation into this phenomenon in the prior works. To address this gap, this paper proposes the Message-Enhanced DeGroot model. The Bounded Brownian Message model provides a quantitative description of the message evolution, jointly considering temporal continuity, randomness, and polarization from mass media theory. The Message-Enhanced DeGroot model, combining the Bounded Brownian Message model with the traditional DeGroot model, quantitatively describes the evolution of agents' opinions under the influence of messages. We theoretically study the probability distribution and statistics of the messages and agents' opinions and quantitatively analyze the impact of messages on opinions. We also conduct simulations to validate our analyses.
From Trojan Horses to Castle Walls: Unveiling Bilateral Backdoor Effects in Diffusion Models
Nov 04, 2023



While state-of-the-art diffusion models (DMs) excel in image generation, concerns regarding their security persist. Earlier research highlighted DMs' vulnerability to backdoor attacks, but these studies placed stricter requirements than conventional methods like 'BadNets' in image classification. This is because the former necessitates modifications to the diffusion sampling and training procedures. Unlike the prior work, we investigate whether generating backdoor attacks in DMs can be as simple as BadNets, i.e., by only contaminating the training dataset without tampering the original diffusion process. In this more realistic backdoor setting, we uncover bilateral backdoor effects that not only serve an adversarial purpose (compromising the functionality of DMs) but also offer a defensive advantage (which can be leveraged for backdoor defense). Specifically, we find that a BadNets-like backdoor attack remains effective in DMs for producing incorrect images (misaligned with the intended text conditions), and thereby yielding incorrect predictions when DMs are used as classifiers. Meanwhile, backdoored DMs exhibit an increased ratio of backdoor triggers, a phenomenon we refer to as `trigger amplification', among the generated images. We show that this latter insight can be used to enhance the detection of backdoor-poisoned training data. Even under a low backdoor poisoning ratio, studying the backdoor effects of DMs is also valuable for designing anti-backdoor image classifiers. Last but not least, we establish a meaningful linkage between backdoor attacks and the phenomenon of data replications by exploring DMs' inherent data memorization tendencies. The codes of our work are available at https://github.com/OPTML-Group/BiBadDiff.
Opinion Dynamics in Two-Step Process: Message Sources, Opinion Leaders and Normal Agents
Sep 11, 2023



According to mass media theory, the dissemination of messages and the evolution of opinions in social networks follow a two-step process. First, opinion leaders receive the message from the message sources, and then they transmit their opinions to normal agents. However, most opinion models only consider the evolution of opinions within a single network, which fails to capture the two-step process accurately. To address this limitation, we propose a unified framework called the Two-Step Model, which analyzes the communication process among message sources, opinion leaders, and normal agents. In this study, we examine the steady-state opinions and stability of the Two-Step Model. Our findings reveal that several factors, such as message distribution, initial opinion, level of stubbornness, and preference coefficient, influence the sample mean and variance of steady-state opinions. Notably, normal agents' opinions tend to be influenced by opinion leaders in the two-step process. We also conduct numerical and social experiments to validate the accuracy of the Two-Step Model, which outperforms other models on average. Our results provide valuable insights into the factors that shape social opinions and can guide the development of effective strategies for opinion guidance in social networks.
Spread Control Method on Unknown Networks Based on Hierarchical Reinforcement Learning
Aug 28, 2023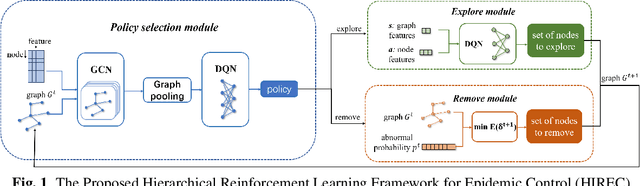
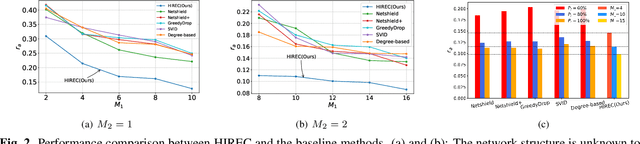
The spread of infectious diseases, rumors, and harmful speech in networks can result in substantial losses, underscoring the significance of studying how to suppress such hazardous events. However, previous studies often assume full knowledge of the network structure, which is often not the case in real-world scenarios. In this paper, we address the challenge of controlling the propagation of hazardous events by removing nodes when the network structure is unknown. To tackle this problem, we propose a hierarchical reinforcement learning method that drastically reduces the action space, making the problem feasible to solve. Simulation experiments demonstrate the superiority of our method over the baseline methods. Remarkably, even though the baseline methods possess extensive knowledge of the network structure, while our method has no prior information about it, our approach still achieves better results.
Modeling Viral Information Spreading via Directed Acyclic Graph Diffusion
May 09, 2023



Viral information like rumors or fake news is spread over a communication network like a virus infection in a unidirectional manner: entity $i$ conveys information to a neighbor $j$, resulting in two equally informed (infected) parties. Existing graph diffusion works focus only on bidirectional diffusion on an undirected graph. Instead, we propose a new directed acyclic graph (DAG) diffusion model to estimate the probability $x_i(t)$ of node $i$'s infection at time $t$ given a source node $s$, where $x_i(\infty)~=~1$. Specifically, given an undirected positive graph modeling node-to-node communication, we first compute its graph embedding: a latent coordinate for each node in an assumed low-dimensional manifold space from extreme eigenvectors via LOBPCG. Next, we construct a DAG based on Euclidean distances between latent coordinates. Spectrally, we prove that the asymmetric DAG Laplacian matrix contains real non-negative eigenvalues, and that the DAG diffusion converges to the all-infection vector $\x(\infty) = \1$ as $t \rightarrow \infty$. Simulation experiments show that our proposed DAG diffusion accurately models viral information spreading over a variety of graph structures at different time instants.