 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemora: A Harmonic Memory Representation Balancing Abstraction and Specificity
Feb 03, 2026Agent memory systems must accommodate continuously growing information while supporting efficient, context-aware retrieval for downstream tasks. Abstraction is essential for scaling agent memory, yet it often comes at the cost of specificity, obscuring the fine-grained details required for effective reasoning. We introduce Memora, a harmonic memory representation that structurally balances abstraction and specificity. Memora organizes information via its primary abstractions that index concrete memory values and consolidate related updates into unified memory entries, while cue anchors expand retrieval access across diverse aspects of the memory and connect related memories. Building on this structure, we employ a retrieval policy that actively exploits these memory connections to retrieve relevant information beyond direct semantic similarity. Theoretically, we show that standard Retrieval-Augmented Generation (RAG) and Knowledge Graph (KG)-based memory systems emerge as special cases of our framework. Empirically, Memora establishes a new state-of-the-art on the LoCoMo and LongMemEval benchmarks, demonstrating better retrieval relevance and reasoning effectiveness as memory scales.
Enhancing Reasoning Capabilities of Small Language Models with Blueprints and Prompt Template Search
Jun 10, 2025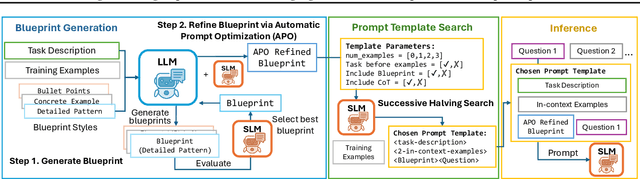
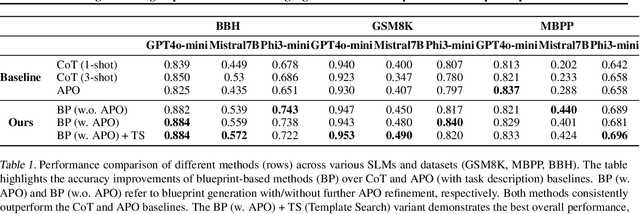


Small language models (SLMs) offer promising and efficient alternatives to large language models (LLMs). However, SLMs' limited capacity restricts their reasoning capabilities and makes them sensitive to prompt variations. To address these challenges, we propose a novel framework that enhances SLM reasoning capabilities through LLM generated blueprints. The blueprints provide structured, high-level reasoning guides that help SLMs systematically tackle related problems. Furthermore, our framework integrates a prompt template search mechanism to mitigate the SLMs' sensitivity to prompt variations. Our framework demonstrates improved SLM performance across various tasks, including math (GSM8K), coding (MBPP), and logic reasoning (BBH). Our approach improves the reasoning capabilities of SLMs without increasing model size or requiring additional training, offering a lightweight and deployment-friendly solution for on-device or resource-constrained environments.
Minerva: A Programmable Memory Test Benchmark for Language Models
Feb 05, 2025



How effectively can LLM-based AI assistants utilize their memory (context) to perform various tasks? Traditional data benchmarks, which are often manually crafted, suffer from several limitations: they are static, susceptible to overfitting, difficult to interpret, and lack actionable insights--failing to pinpoint the specific capabilities a model lacks when it does not pass a test. In this paper, we present a framework for automatically generating a comprehensive set of tests to evaluate models' abilities to use their memory effectively. Our framework extends the range of capability tests beyond the commonly explored (passkey, key-value, needle in the haystack) search, a dominant focus in the literature. Specifically, we evaluate models on atomic tasks such as searching, recalling, editing, matching, comparing information in context memory, and performing basic operations when inputs are structured into distinct blocks, simulating real-world data. Additionally, we design composite tests to investigate the models' ability to maintain state while operating on memory. Our benchmark enables an interpretable, detailed assessment of memory capabilities of LLMs.
EcoAct: Economic Agent Determines When to Register What Action
Nov 03, 2024



Recent advancements have enabled Large Language Models (LLMs) to function as agents that can perform actions using external tools. This requires registering, i.e., integrating tool information into the LLM context prior to taking actions. Current methods indiscriminately incorporate all candidate tools into the agent's context and retain them across multiple reasoning steps. This process remains opaque to LLM agents and is not integrated into their reasoning procedures, leading to inefficiencies due to increased context length from irrelevant tools. To address this, we introduce EcoAct, a tool using algorithm that allows LLMs to selectively register tools as needed, optimizing context use. By integrating the tool registration process into the reasoning procedure, EcoAct reduces computational costs by over 50% in multiple steps reasoning tasks while maintaining performance, as demonstrated through extensive experiments. Moreover, it can be plugged into any reasoning pipeline with only minor modifications to the prompt, making it applicable to LLM agents now and future.
On Evaluating LLMs' Capabilities as Functional Approximators: A Bayesian Perspective
Oct 06, 2024


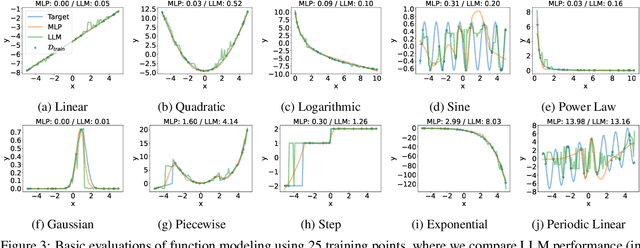
Recent works have successfully applied Large Language Models (LLMs) to function modeling tasks. However, the reasons behind this success remain unclear. In this work, we propose a new evaluation framework to comprehensively assess LLMs' function modeling abilities. By adopting a Bayesian perspective of function modeling, we discover that LLMs are relatively weak in understanding patterns in raw data, but excel at utilizing prior knowledge about the domain to develop a strong understanding of the underlying function. Our findings offer new insights about the strengths and limitations of LLMs in the context of function modeling.
Permissive Information-Flow Analysis for Large Language Models
Oct 04, 2024



Large Language Models (LLMs) are rapidly becoming commodity components of larger software systems. This poses natural security and privacy problems: poisoned data retrieved from one component can change the model's behavior and compromise the entire system, including coercing the model to spread confidential data to untrusted components. One promising approach is to tackle this problem at the system level via dynamic information flow (aka taint) tracking. Unfortunately, the traditional approach of propagating the most restrictive input label to the output is too conservative for applications where LLMs operate on inputs retrieved from diverse sources. In this paper, we propose a novel, more permissive approach to propagate information flow labels through LLM queries. The key idea behind our approach is to propagate only the labels of the samples that were influential in generating the model output and to eliminate the labels of unnecessary input. We implement and investigate the effectiveness of two variations of this approach, based on (i) prompt-based retrieval augmentation, and (ii) a $k$-nearest-neighbors language model. We compare these with the baseline of an introspection-based influence estimator that directly asks the language model to predict the output label. The results obtained highlight the superiority of our prompt-based label propagator, which improves the label in more than 85% of the cases in an LLM agent setting. These findings underscore the practicality of permissive label propagation for retrieval augmentation.
LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Mar 19, 2024



This paper focuses on task-agnostic prompt compression for better generalizability and efficiency. Considering the redundancy in natural language, existing approaches compress prompts by removing tokens or lexical units according to their information entropy obtained from a causal language model such as LLaMa-7B. The challenge is that information entropy may be a suboptimal compression metric: (i) it only leverages unidirectional context and may fail to capture all essential information needed for prompt compression; (ii) it is not aligned with the prompt compression objective. To address these issues, we propose a data distillation procedure to derive knowledge from an LLM to compress prompts without losing crucial information, and meantime, introduce an extractive text compression dataset. We formulate prompt compression as a token classification problem to guarantee the faithfulness of the compressed prompt to the original one, and use a Transformer encoder as the base architecture to capture all essential information for prompt compression from the full bidirectional context. Our approach leads to lower latency by explicitly learning the compression objective with smaller models such as XLM-RoBERTa-large and mBERT. We evaluate our method on both in-domain and out-of-domain datasets, including MeetingBank, LongBench, ZeroScrolls, GSM8K, and BBH. Despite its small size, our model shows significant performance gains over strong baselines and demonstrates robust generalization ability across different LLMs. Additionally, our model is 3x-6x faster than existing prompt compression methods, while accelerating the end-to-end latency by 1.6x-2.9x with compression ratios of 2x-5x.
Unlocking Spatial Comprehension in Text-to-Image Diffusion Models
Nov 28, 2023



We propose CompFuser, an image generation pipeline that enhances spatial comprehension and attribute assignment in text-to-image generative models. Our pipeline enables the interpretation of instructions defining spatial relationships between objects in a scene, such as `An image of a gray cat on the left of an orange dog', and generate corresponding images. This is especially important in order to provide more control to the user. CompFuser overcomes the limitation of existing text-to-image diffusion models by decoding the generation of multiple objects into iterative steps: first generating a single object and then editing the image by placing additional objects in their designated positions. To create training data for spatial comprehension and attribute assignment we introduce a synthetic data generation process, that leverages a frozen large language model and a frozen layout-based diffusion model for object placement. We compare our approach to strong baselines and show that our model outperforms state-of-the-art image generation models in spatial comprehension and attribute assignment, despite being 3x to 5x smaller in parameters.
Rethinking Privacy in Machine Learning Pipelines from an Information Flow Control Perspective
Nov 27, 2023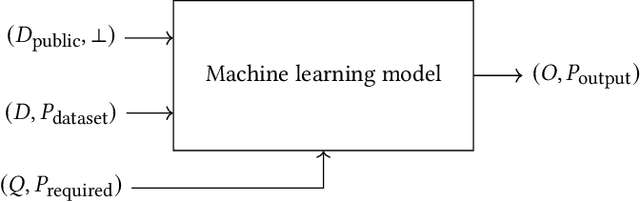
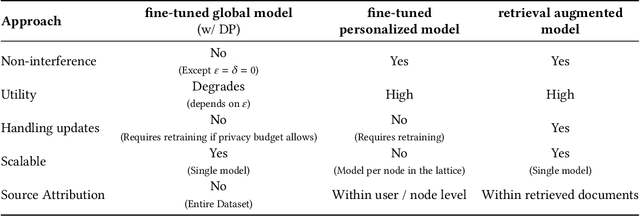
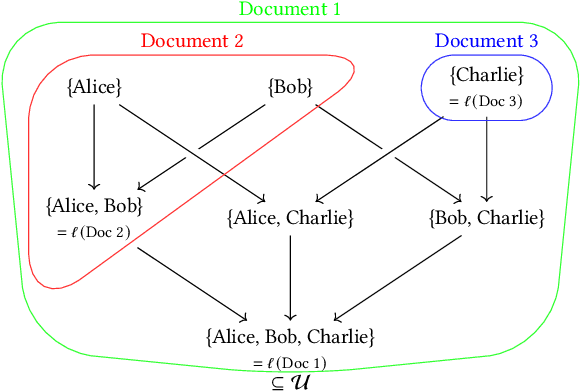
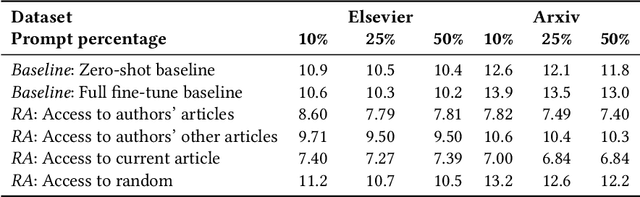
Modern machine learning systems use models trained on ever-growing corpora. Typically, metadata such as ownership, access control, or licensing information is ignored during training. Instead, to mitigate privacy risks, we rely on generic techniques such as dataset sanitization and differentially private model training, with inherent privacy/utility trade-offs that hurt model performance. Moreover, these techniques have limitations in scenarios where sensitive information is shared across multiple participants and fine-grained access control is required. By ignoring metadata, we therefore miss an opportunity to better address security, privacy, and confidentiality challenges. In this paper, we take an information flow control perspective to describe machine learning systems, which allows us to leverage metadata such as access control policies and define clear-cut privacy and confidentiality guarantees with interpretable information flows. Under this perspective, we contrast two different approaches to achieve user-level non-interference: 1) fine-tuning per-user models, and 2) retrieval augmented models that access user-specific datasets at inference time. We compare these two approaches to a trivially non-interfering zero-shot baseline using a public model and to a baseline that fine-tunes this model on the whole corpus. We evaluate trained models on two datasets of scientific articles and demonstrate that retrieval augmented architectures deliver the best utility, scalability, and flexibility while satisfying strict non-interference guarantees.
Hybrid Retrieval-Augmented Generation for Real-time Composition Assistance
Aug 08, 2023



Retrieval augmented models show promise in enhancing traditional language models by improving their contextual understanding, integrating private data, and reducing hallucination. However, the processing time required for retrieval augmented large language models poses a challenge when applying them to tasks that require real-time responses, such as composition assistance. To overcome this limitation, we propose the Hybrid Retrieval-Augmented Generation (HybridRAG) framework that leverages a hybrid setting that combines both client and cloud models. HybridRAG incorporates retrieval-augmented memory generated asynchronously by a Large Language Model (LLM) in the cloud. By integrating this retrieval augmented memory, the client model acquires the capability to generate highly effective responses, benefiting from the LLM's capabilities. Furthermore, through asynchronous memory integration, the client model is capable of delivering real-time responses to user requests without the need to wait for memory synchronization from the cloud. Our experiments on Wikitext and Pile subsets show that HybridRAG achieves lower latency than a cloud-based retrieval-augmented LLM, while outperforming client-only models in utility.